老司机带你玩转面试:Redis 集群模式 Redis Cluster
Posted 极客挖掘机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了老司机带你玩转面试:Redis 集群模式 Redis Cluster相关的知识,希望对你有一定的参考价值。
简介
之前介绍的 Redis 的高可用方案:主从模式或者说哨兵模式,都只是在解决高可用的问题,比如说主从模式解决了读高可用,哨兵模式解决了写高可用。
如果我们需要缓存的数据量比较少,几个 G 足够用了,那么这两种方案的高可用模式完全可以满足需求,一个 master 对多个 salve ,需要几个 salve 跟读的吞吐量相关,然后再搞一个 sentinel 集群去保证 Redis 主从模式的高可用。
但是如果我们有大量的数据需要进缓存,单机的存储容量无法满足的时候,怎么办?
这时,需要用到分布式缓存,就在几年前,想用分布式缓存还得借助中间件来实现,比如当时风靡一时的 codis ,或者说还有 twemproxy 。在使用上,我们对 Redis 中间件进行读写操作, Redis 中间件负责将我们的数据分布式的存储在多台机器上的 Redis 实例中。
而 Redis 也是不断在发展的,终于在 3.0 的版本中(其实对现在来讲也是比较早的版本了,现在的版本都 6.0 了),原生支持了集群模式。
可以做到在多台机器上,部署多个 Redis 实例,每个实例存储一部分的数据,同时每个 Redis 主实例可以挂载 Redis 从实例,实现了 Redis 主实例挂了,会自动切换到 Redis 从实例上来。
除了实现了分布式存储以外,还顺便实现了高可用。
分布式寻址算法
Redis Cluster 的数据是分布式存储的,这就必然会引发一个问题,假如我有 3 个节点,我如何知道一个 key 是存在这 3 个节点的哪一个节点上,取数的时候如何准确的找到对应的节点将数据取出来?这就要用到分布式寻址算法了。
常见的分布式寻址算法有两种:
-
hash 算法 -
一致性 hash 算法
hash 算法
hash 算法是对 key 进行 hash 运算后取值,然后对节点的数量取模。
接着将 key 存入对应的节点,但是,一旦其中某个节点宕机,所有的请求过来,都会基于最新的存活的节点数量进行取模运算,这就会导致大多数的请求无法拿到缓存数据。
举个例子,一开始我有 3 个节点,这时大家正常的取模运算将数据基本均匀的存在了 3 个节点上,突然宕机了一台,现在只剩下 2 个有效的节点了,这时所有的运算都会基于最新的 2 个节点进行取模运算,原来的 key 对 2 进行取模运算后,显然和对 3 进行取模运算得到的结果是不一样的。
结果是大量的数据请求会直接打在 DB 上,这是不可容忍的。
一致性 hash 算法
一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
来看一个经典的一致性 hash 算法的环状示意图:
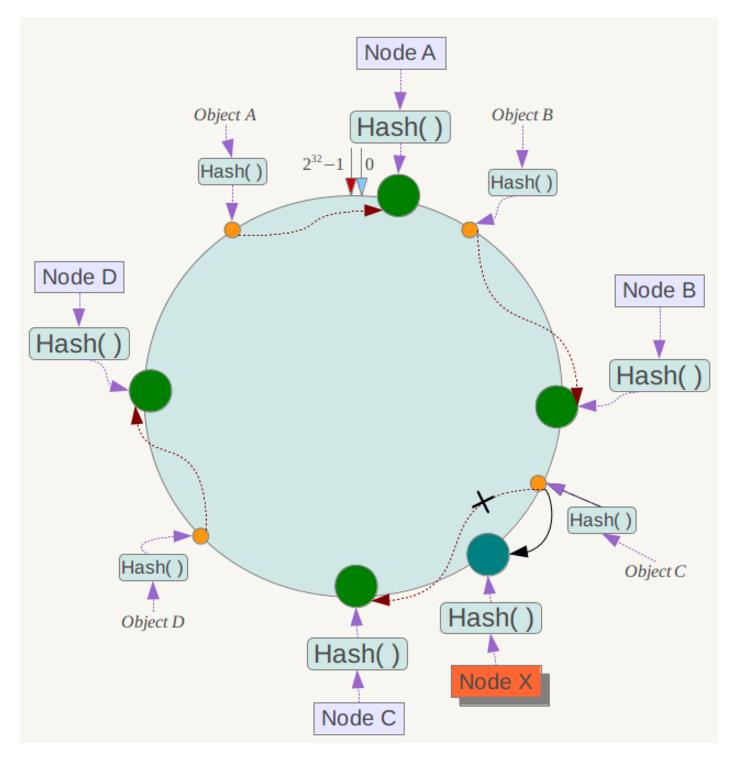
来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针「行走」,遇到的第一个 master 节点就是 key 所在位置。
在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
Redis Cluster 的 hash slot 算法
Redis Cluster 的实现方案十分的聪明,它的分区方式采用了虚拟槽分区。
Redis Cluster 首先会预设虚拟槽,每个槽就相当于一个数字,有一定范围,每个槽映射一个数据子集。
Redis Cluster中预设虚拟槽的范围为 0 到 16383
-
Redis Cluster 会把 16384 个槽按照节点数量进行平均分配,由节点进行管理。 -
当一个 key 过来的时候,会对这个 key 按照 CRC16 规则进行 hash 运算。 -
把 hash 结果对 16383 进行取余。 -
把余数发送给 Redis 节点。 -
节点接收到数据,验证是否在自己管理的槽编号的范围: -
如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果。 -
如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中。
注意:Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
节点内部通信机制
在分布式的存储方式中,还有另外一个点需要我们关注,那就是集群之间的内部通信方式,毕竟整个集群是需要知道当前集群中有多少有效的节点,这些节点分配的 ip 以及一些其他的数据,这些数据我们可以称之为元数据。
集群元数据的维护有两种方式:集中式、 Gossip 协议。而 Redis Cluster 节点间采用 Gossip 协议进行通信。
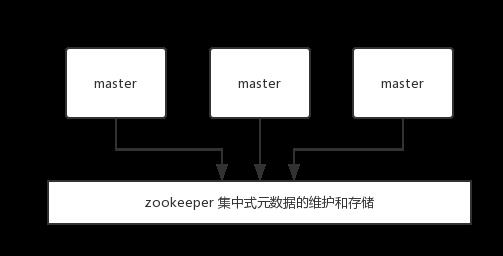
集中式是将集群元数据(节点信息、故障等等)几种存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的 storm 。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper (分布式协调的中间件)对所有元数据进行存储维护。
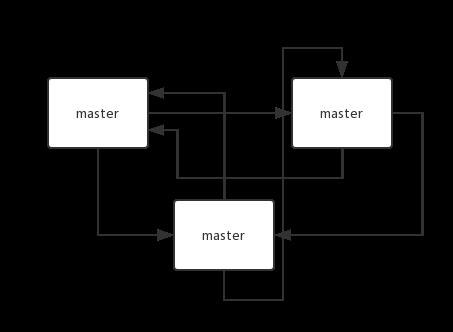
Redis 维护集群元数据采用另一个方式, Gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。
Gossip 协议
Gossip 协议是一种非常有意思的协议,它的过程是由一个种子节点发起,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。
这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
Gossip 协议的一些特性:
-
扩展性:网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。 -
容错:网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。 -
去中心化:Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。 -
一致性收敛:Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。 -
消息的延迟:由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。 -
消息冗余:Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
Gossip 协议包含多种消息,包含 ping , pong , meet , fail 等等。
-
meet:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。 -
ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。 -
pong:返回 ping 和 meeet,包含自己的状态和其它信息,也用于信息广播和更新。 -
fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机啦。
由于 Redis Cluster 节点之间会定期交换 Gossip 消息,以及做一些心跳检测,对网络带宽的压力还有比较大的,包括官方都直接建议 Redis Cluster 节点数量不要超过 1000 个,当集群中节点数量过多的时候,会产生不容忽视的带宽消耗。
高可用和主备切换
一说到集群就不得不提高可用和主备切换,而Redis cluster 的高可用的原理,几乎跟哨兵是类似的。
判断宕机
首先第一步当然是判断宕机,这和哨兵模式非常的像,同样是分成两种类型,一种是主观宕机 pfail ,另一种的客观宕机 fail 。
-
主观宕机:一个节点认为另外一个节点宕机,这是一种「偏见」,并不代表整个集群的认知。
-
节点 1 定期发送 ping 消息给节点 2 。 -
如果发送成功,代表节点 2 正常运行,节点 2 会响应 PONG 消息给节点 1 ,节点 1 更新与节点 2 的最后通信时间 -
如果发送失败,则节点 1 与节点 2 之间的通信异常判断连接,在下一个定时任务周期时,仍然会与节点 2 发送 ping 消息 -
如果节点 1 发现与节点 2 最后通信时间超过 cluster-node-timeout,则把节点 2 标识为 pfail 状态。
-
客观宕机:当半数以上持有槽的主节点都标记某节点主观下线。
-
当节点 1 认为节点 2 宕机后,那么会在 Gossip ping 消息中, ping 给其他节点。 -
当其他节点会重新尝试之前节点 1 主观宕机的过程。 -
如果有超过半数的节点都认为 pfail了,那么这个节点 2 就会变成真的fail。
注意:集群模式下,只有主节点( master )才有读写权限和集群槽的维护权限,从节点( slave )只有复制的权限。
从节点选举
-
先检查资格,检查所有的 salve 与 master 断开连接的时间,如果超过了 cluster-node-timeout * cluster-slave-validity-factor,那么久没有资格成为 master 。 -
每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。 -
所有的 master 开始选举投票,如果大部分 master 节点 (N/2 + 1) 都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master 。 -
从节点执行主备切换,从节点切换为主节点。
参考
https://www.cnblogs.com/williamjie/p/11132211.html
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-cluster.md
https://zhuanlan.zhihu.com/p/41228196
以上是关于老司机带你玩转面试:Redis 集群模式 Redis Cluster的主要内容,如果未能解决你的问题,请参考以下文章