Redis五种基本数据类型的典型应用场景
Posted 探索编程之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis五种基本数据类型的典型应用场景相关的知识,希望对你有一定的参考价值。
字符串
1、缓存功能
Redis比较典型的是缓存使用场景,其中Redis作为缓存层,mysql作为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
使用Redis做缓存访问过程:伪代码展示代码访问流程:1)定义用于获取用户基础信息的函数
UserInfo getUserInfo(long id){...}
2)首先从Redis获取用户信息
// 定义键userRedisKey = "user:info:" + id;// 从Redis获取值value = redis.get(userRedisKey);if (value != null) {// 将值进行反序列化为UserInfo并返回结果userInfo = deserialize(value);return userInfo;}
Redis和MySQL等关系型数据库不同的是,Redis没有命令空间,而且也没有对键名有强制要求(除了不能使用一些特殊字符)。但设计合理的键名,有利于防止键冲突和项目的可维护性,比较推荐的方式是使用“业务名:对象名:id:[属性]”作为键名。
例如MySQL的数据库名为 vs ,用户表名为 user ,那么对应的键可以用 “ vs:user:1” ,“vs :user:1:name”来表示,如果当前Redis只被一个业务使用,甚至可以去掉“vs:”。如果键名比较长,例如“user:{uid}:friends:messages:{mid}”,可以在能描述键含义的前提下适当减少键的长度,例如变为“u:{uid}:fr:m:{mid}”,从而减少由于键过长的内存浪费。
3)如果没有从Redis获取到用户信息,需要从MySQL中进行获取,并将结果写到Redis,添加 1 小时(3600秒)过期时间。
// 从MySQL获取用户信息userInfo = mysql.get(id);// 将userInfo序列化,并存入Redisredis.setex(userRedisKey, 3600, serialize(userInfo));// 返回结果return userInfo
整个功能完整的伪代码如下:
UserInfo getUserInfo(long id){userRedisKey = "user:info:" + idvalue = redis.get(userRedisKey);UserInfo userInfo;if (value != null) {userInfo = deserialize(value);} else {userInfo = mysql.get(id);if (userInfo != null)redis.setex(userRedisKey, 3600, serialize(userInfo));}return userInfo;}
2、计数
许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数,查询缓存的功能,同时数据可以异步落地到其他数据源。例如视频播放系统就是使用Redis作为视频播放计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增 1 。
long incrVideoCounter(long id) {key = "video:playCount:" + id;return redis.incr(key);}
实际上一个真实的计数系统要考虑的问题有很多:防作弊,按照不同维度计数,数据持久化到底层数据源等。
3、共享Session
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的。
Session如果是分散管理的话,呈现类似下面的情况: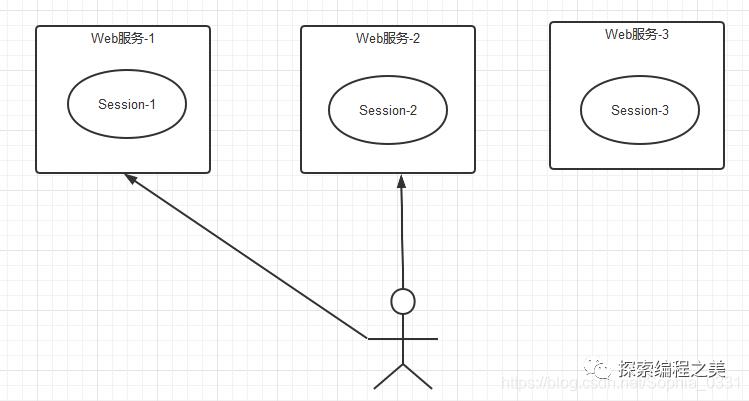 为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如下图,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或查询登录信息都直接从Redis中集中获取。
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如下图,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或查询登录信息都直接从Redis中集中获取。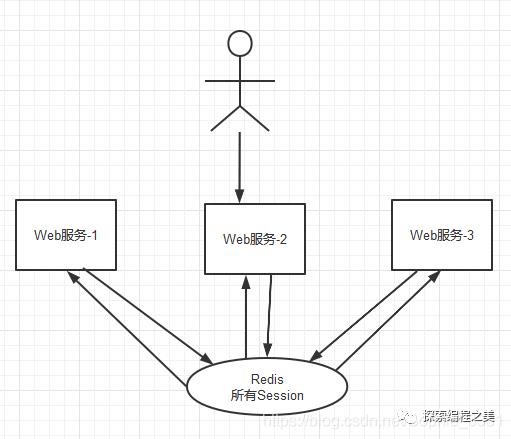
4、限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过 5 次,如下图: 可以用Redis来实现限速功能,下面用伪代码给出了基本实现思路:
可以用Redis来实现限速功能,下面用伪代码给出了基本实现思路:
phoneNum = "138xxxxxxxx";key = "shortMsg:limit:" + phoneNum;// SET key value EX 60 NXisExists = redis.set(key,1,"EX 60","NX");if(isExists != null || redis.incr(key) <=5){// 通过}else{// 限速}
哈希
1、缓存用户信息
下图是在关系型数据表记录的两条用户信息,用户的属性作为表的列,每条用户信息作为行。
 如果将其用哈希类型存储,如下:
如果将其用哈希类型存储,如下: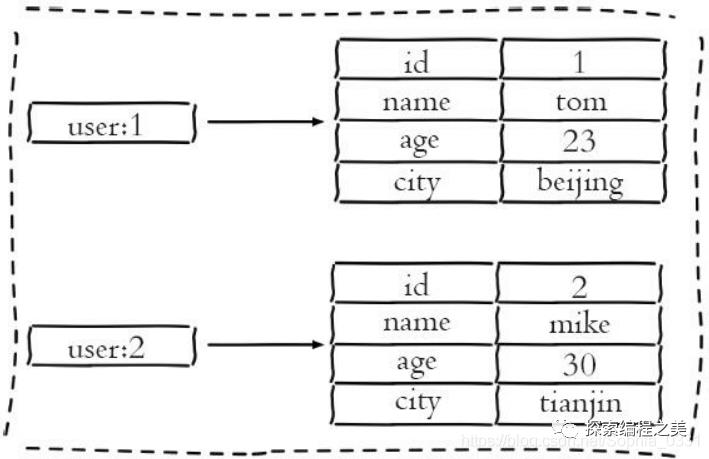 相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的 id 定义为键后缀,多对 field-value 对应每个用户的属性,类似如下伪代码:
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的 id 定义为键后缀,多对 field-value 对应每个用户的属性,类似如下伪代码:
UserInfo getUserInfo(long id){// 用户id作为key后缀userRedisKey = "user:info:" + id;// 使用hgetall获取所有用户信息映射关系userInfoMap = redis.hgetAll(userRedisKey);UserInfo userInfo;if (userInfoMap != null) {// 将映射关系转换为UserInfouserInfo = transferMapToUserInfo(userInfoMap);} else {// 从MySQL中获取用户信息userInfo = mysql.get(id);// 将userInfo变为映射关系使用hmset保存到Redis中redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));// 添加过期时间 redis.expire(userRedisKey, 3600);}return userInfo;}
但是要注意哈希类型和关系型数据库有两点不同之处:
-
哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值(即使为NULL)。 -
关系型数据库可以做复杂的关系查询,而Redis 去模拟关系型复杂查询开发困难,维护成本高
将这两者特点搞清楚,才能在适合的场景使用适合的技术。我们可以用三种方法缓存用户信息,下面给出三种方案的实现方法和优缺点分析。
1)原生字符串类型:每个属性一个键
set user:1:name tomset user:1:age 23set user:1:city beijing
优点:简单直观,每个属性都支持更新操作 缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以此种方案一般不会在生产环境使用。
2)序列化字符串类型:将用户信息序列化后用一个键保存
set user:1 serialize(userInfo)优点:简化编程,如果合理的使用序列化可以提高内存的使用效率 缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
3)哈希类型:每个用户属性使用一对 field-value ,但是只用一个键保存
hmset user:1 name tomage 23 city beijing优点:简单直观,如果使用合理可以减少内存空间的使用 缺点:要控制哈希在ziplist和hashtable 两种内部编码的转换,hashtable会消耗更多的内存。
列表
1、消息队列
Redis 的 lpush+brpop 命令组合即可实现阻塞队列,生产者客户端使用 lrpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式 的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
lpush :从左边插入数据brpop :移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
2、文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。1)每篇文章使用哈希结构存储,例如每篇文章有3个属性 title,timestamp,content:
hmset acticle:5 title xx timestamp 1456474536 content xxx2)向用户文章列表添加文章,user:{id}:articles 作为用户文章列表的键:
lpush user:1:acticles article:1 article3...lpush user:k:acticles article:5...
3)分页获取用户文章列表,例如下面伪代码获取用户 id=1 的前 10 篇文章:
articles =lrange user:1:articles 0 9for article in {articles}hgetall {article}
使用列表类型保存和获取文章列表会存在两个问题:
-
第一,如果每次分页获取的文章个数较多,需要执行多次 hgetall 操作,此时可以考虑使用 Pipeline批量获取,或者考虑文章数据序列化为字符串类型,使用mget批量获取。 -
第二,分页获取文章列表时,lrange命令在列表两端性能较好,但是如果列表较大,获取列表中间范围的元素性能会变差,此时可以考虑将列表做二级拆分,或者使用Redis 3.2 的quicklist 内部编码实现,它结合 ziplist和 linkedlist 的特点,获取列表中间范围的元素时也可以高效完成。
实际上列表的使用场景很多,在选择时可以参考以下口诀:
lpush + lpop = Stack(栈)lpush + rpop = Queue (队列)lpsh + ltrim = Capped Collection (有限集合)lpush + brpop = Message Queue (消息队列)
集合
1、标签(tag)
集合类型比较典型的使用场景是标签(tag)。例如一个用户可能会娱乐,体育比较感兴趣,另一个用户可能对历史,新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户粘度比较重要。
例如一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益。
下面用集合类型实现标签功能的若干功能。1)给用户添加标签
sadd user:1:tags tag1 tag2 tag5sadd user:2:tags tag2 tag3 tag5
2)给标签添加用户
sadd tag1:users user:1 user:3sadd tag2:users user:1 user:2 user:3
用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致,或者使用Lua脚本。3)删除用户下的标签
srem user:1:tags tag1 tag54)删除标签下的用户
srem tag1:users user:1srem tag5:users user:1
3)和4)也是尽量放在一个事务执行。5)计算用户共同感兴趣的标签 可以使用 sinter 命令,来计算用户共同感兴趣的标签,如下:
sinter user:1:tags user:2:tags集合类型的应用场景通常为以下几种:
sadd = Tagging(标签)spop / srandmember = Random item (生成随机数,比如抽奖)sadd + sinter = Social Graph(社交需求)
有序集合
1、排行榜
有序集合典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间,按照播放数量,按照获得的赞数。
举例说明赞数这个维度,记录每天用户上传视频的排行榜,主要需要实现以下 4 个功能。
1)添加用户赞数 例如用户Mike上传了一个视频,并获得了 3 个赞,可以使用有序集合的 zadd 和 zincrby 功能:
zadd user:ranking:2016_03_15 mike 3如果之后再获得一个赞,可以使用 zincrby
zinbrby user:ranking:2016_03_15 mike 12)取消用户赞数 由于各种原因(例如用户注销,用户作弊)需要将用户删除,此时需要将用户从榜单中删除掉,可以使用 zrem 。例如删除成员 tom:
zrem user:ranking:2016_03_15 tom3)展示获取赞数最多的十个用户 此功能使用 zrevrange 命令实现:
zrevrangebyrank user:ranking:2016_03_15 0 94)展示用户信息以及用户分数 此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用 zscore 和 zrank 两个功能。
hgetall user:info:tomzscore user:ranking:2016_03_15 mikezrank user:ranking:2016_03_15 mike
以上是关于Redis五种基本数据类型的典型应用场景的主要内容,如果未能解决你的问题,请参考以下文章