记录一次生产环境中Redis内存增长异常排查全流程!
Posted 不加班程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一次生产环境中Redis内存增长异常排查全流程!相关的知识,希望对你有一定的参考价值。
★一枚用心坚持写原创的“无趣”程序猿,在自身受益的同时也让朋友们在技术上有所提升。
最近 DBA 反馈线上的一个 Redis 资源已经超过了预先设计时的容量,并且已经进行了两次扩容,内存增长还在持续中,希望业务方排查一下容量增长是否正常,若正常则期望重新评估资源的使用情况,若不正常请尽快查明问题并给出解决方案进行处理。
问题现象
下面是当时资源容量使用和 key 数量的监控情况:
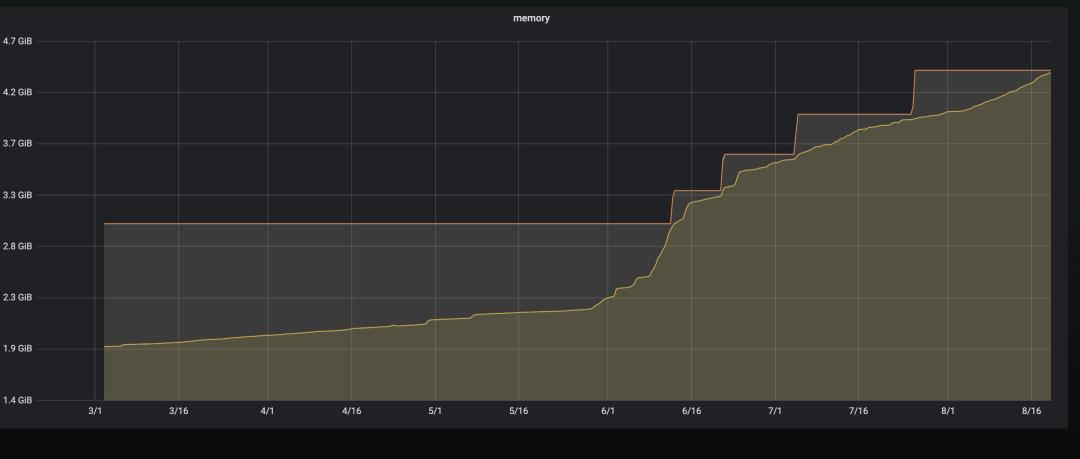
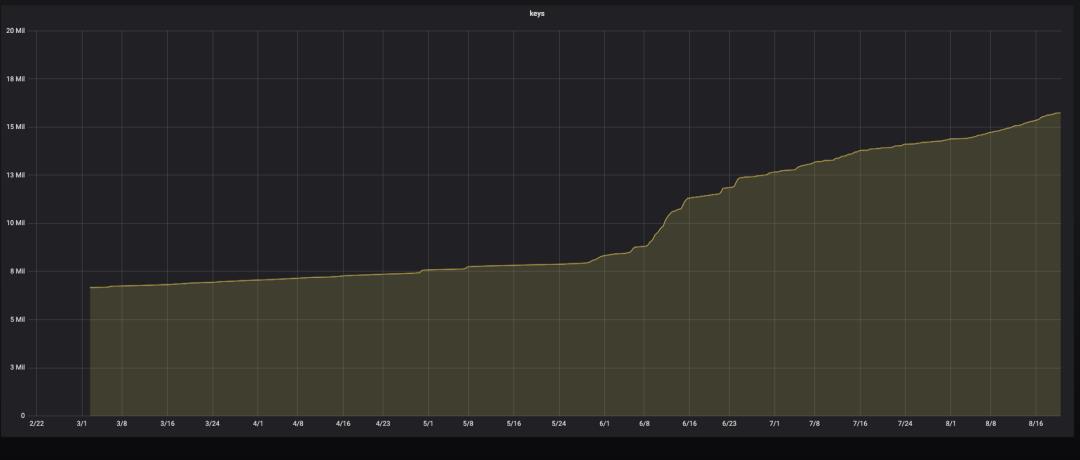
从监控可以看出,6.1 号开始容量和 keys 的增长陡增。首先怀疑是有恶意刷量的操作导致 key 数量增加比较多,经过代码排查后发现,确实有代码漏洞导致可以恶意刷量,后经过 bug 修复后上线。你以为到这里就完事了?天真,要不然写这篇文章还有什么用?
但是从接口的请求量来看的话,刷量的情况并没有那么明显,下面是接口请求的 qps:

继续排查存储设计发现,存储使用了 Set 结构(由于产品最开始没有明确说明一个 key 下存储多少元素,所以采用了 Set,这也为后续容量异常增长打下了 坚实的基础 ),实际每个 Set 中只存储了一个元素,但实际容量却增长了 30M,根据容量计算公式 9w * 14(key 长度) * 1(元素个数) * 10(元素长度)= 8.4M,实际容量却超出了近 4 倍。
到此,产生了两个怀疑点,其一:实际存储的数据占用内存大小有问题,其二:容量评估公式有问题。
疑点一:实际存储的数据占用内存大小有问题
查看 Redis 的 Set 底层存储结构发现,Set 集合采用了整数集合和字典两种方式来实现的,当满足如下两个条件的时候,采用整数集合实现;一旦有一个条件不满足时则采用字典来实现。
-
Set 集合中的所有元素都为整数 -
Set 集合中的元素个数不大于 512(默认 512,可以通过修改 set-max-intset-entries 配置调整集合大小)
关于详细内容,可以查看作者写过的这篇内容:
排查到这里,按照正常情况的话,其应该采用的是整数集合存储的才对啊,但是登陆到机器上,使用 memory usage key 命令查看内存的使用情况发现,单个 key 的内存占用竟然达到了 218B :

是不是觉得不可思议,只是存储一个 10 位的数据且内容是数字,为什么会占用这么大的内存呢?
到此我们开始怀疑是不是序列化的方式有问题导致实际写入 Redis 的内容不是一个数字,所以接着查数据实际写入时用的序列化方式。经过排查发现写入的 value 被序列化以后变成了一个十六进制的数据,到这里这个疑点基本就真相大白了,因为此时 Redis 认为存储的内容已经不适用于整数集合存储了,而改为字典存储。将序列化方式修改以后,测试添加一个元素进去,发现实际内存占用只有 72B,缩减为原来的 1/3:
疑点二:容量评估公式有问题
容量评估公式忽略了 Redis 对于不同的情况下内存的占用情况,统一按照元素的大小去计算,导致实际内容占用过小。
到此,整个 Redis 内存容量增长异常基本上可以告一段路了,接下来就是修改正确的序列化和反序列化方式,然后进行洗库操作,经业务调查发现,目前的实际使用方式可以改为 KV 结构,所以将底层存储进行了改造。
洗库流程介绍
-
上线双写逻辑 -
同步历史数据 -
切换读取新数据源 -
观察线上业务是否正常 -
关闭旧存储的写入 -
删除旧资源 -
下线旧的读写逻辑
关于新数据的存储位置有两种选择,
-
第一种方式是:旧数据正常写旧资源,新数据写到新部署的资源下。此种方式的优点是,将旧数据全量洗入新资源后,然后下线旧资源就可以了;缺点是,需要在代码层重新写一套到资源的配置,DBA 也需要新部署一个资源。 -
第二种方式是:新旧数据都写到旧资源里面,然后将旧数据映射到新数据结构上,然后全量洗入旧资源。此种方式的优点是,不需要重新写一套到资源的配置,DBA 也不需要新部署资源,只需要将旧资源的内存进行扩容操作即可;缺点是,全量数据洗入完成后,需要手动剔除旧数据。
两种方案都可行,可以根据自己的喜好来选择,我们最终选择了第二种方案进行数据清洗操作。
上线双写逻辑
在资源存储层,对上下行读写操作分别增加 switcher(开关),然后增加读写新存储的逻辑,代码测试通过后上线。
这一步的流程在于开关,可以选择热部署的任何方式来修改标志位,从而控制代码流程的执行,另外需要注意的一点是:开关状态的修改不能被工程上下线所影响。
同步历史数据
上线完成后,导出线上库的 RDB 文件,解析出所有 key(关于 RDB 文件的解析,如果有专门的 DBA 同事,可以让 DBA 同事给解析好,如果没有的话,可以自己在网上查查 RDB 文件解析的工具,也不是很难);依次遍历解析出来的 key,查询 key 对应的旧数据,将旧数据映射到新数据结构下,最后写入到新的存储下。
关于同步历史数据,需要根据自身实际的业务场景去做适当的调整,这里只提供一个思路。下面是洗数据可以使用的小工具,需要的朋友可以适当调整代码逻辑就可以使用了:
public class fixData {
public static void main(String[] args) {
String fileName = "test.txt";
int rate = 500;
int size = 200;
if (args != null) {
fileName = args[0];
rate = Integer.parseInt(args[1]);
size = Integer.parseInt(args[2]);
}
RateLimiter rateLimiter = RateLimiter.create(rate);
ThreadPoolExecutor executorService = new ThreadPoolExecutor(size, size, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());
executorService.prestartAllCoreThreads();
try {
FileReader fr = new FileReader(fileName);
LineNumberReader br = new LineNumberReader(fr);
String line;
while ((line = br.readLine()) != null) {
try {
rateLimiter.acquire();
executorService.submit(() -> {
// TODO 编写自己的数据处理逻辑
});
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
}
切换读取新数据源
历史所以数据同步完成后,将读操作的开关关闭,让其走读新存储的逻辑
这一步需要注意的是,此时只修改下行读取数据的开关状态,让其读取新数据源,上行写入数据开关不动,依旧让其进行双写操作,防止下行切到新数据源有问题需要回滚导致新旧数据不一致的尴尬情况发生。
观察线上业务是否正常
切到读新存储的逻辑下,观察线上业务,有无用户投诉数据异常的情况
关闭就存储的写入
线上业务无异常情况,将写操作也切到只写新存储的逻辑下,停止旧资源的写入
删除旧资源
将写上所有旧 key 全部剔除,剔除旧数据的操作方式可以复用洗数据的流程即可。
下线旧的读写逻辑
将线上就的读写逻辑代码全部下线,最终完成整个数据清洗的全流程
总结
以上,是一次完整的真实生产环境中问题排查及数据清洗全过程,通过本次问题的排查,也进一步加深了对 Redis 的底层实现的认识和理解;
同时,透过本次事故需要我们反思的是,面对亲手写下的每一行代码,都需要怀着一颗敬畏心理,永远不要轻视,有可能一个不小心就会酿成一个灾难性的事故。文章到此就先告一段落了,但是排查问题的脚步还在继续,欢迎关注我学习更多有干货的知识。
以上是关于记录一次生产环境中Redis内存增长异常排查全流程!的主要内容,如果未能解决你的问题,请参考以下文章
记录一次生产环境Net Core应用内存暴涨导致OOM的排查过程
记录一次生产环境Net Core应用内存暴涨导致OOM的排查过程