编译原理NFA转DFA ,请问DFA的初始状态如何确定?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理NFA转DFA ,请问DFA的初始状态如何确定?相关的知识,希望对你有一定的参考价值。
能否举个简单的例子说明,不胜感谢!
NFA确定化的时候,包含NFA初态的那个DFA状态就是确定后的DFA的初态。
DFA的终态就是所有包含了NFA终态的DFA的状态。
先以0开始,经过任意个ε得到的结点就是第一个状态,这道题没有ε就是0。
根据算法转化来的DFA肯定是唯一的,但是转化得到的DFA并不一定是状态最少的,每一个DFA都可以转化到状态最少的DFA。状态最少的DFA是唯一的(状态名不同的同构情况除外)。因为每个DFA都可以对应相应的NFA(DFA本身就是),所以NFA转化的DFA不一定都是状态数最少的。
扩展资料:
DFA以如下方式接受或拒绝一个字符串:从初始状态出发,对于输入字符串中的每个字符,自动机都将沿着一条确定的边到另一状态,这条边必须是标有输入符号的边。对n个字符的字符串进行了n次状态变换后,如果自动机到达了一个终态,自动机将接收该字符串。
若到达的不是终态,或者找不到与输入字符相匹配的边,那么字符串将拒绝接受这个字符串。 由一个自动机识别的语言是该自动机接收的字符串集合。
参考资料来源:百度百科-DFA
参考技术ANFA确定化的时候,包含NFA初态的那个DFA状态就是确定后的DFA的初态。
DFA的终态就是所有包含了NFA终态的DFA的状态。
对于DFA来说,他的初态就是包含了NFA唯一初态1的那个状态,就是左边的1,2右边的1了。
脱氧核糖-磷酸链在螺旋结构的外面,碱基朝向里面。两条多脱氧核苷酸链反向互补,通过碱基间的氢键形成的碱基配对相连,形成相当稳定的组合。

扩展资料:
将DNA或RNA序列以三个核苷酸为一组的密码子转译为蛋白质的氨基酸序列,以用于蛋白质合成。密码子由mRNA上的三个核苷酸(例如ACU,CAG,UUU)的序列组成,每三个核苷酸与特定氨基酸相关。
例如,三个重复的胸腺嘧啶(UUU)编码苯丙氨酸。使用三个字母,可以拥有多达64种不同的组合。由于有64种可能的三联体和仅20种氨基酸,因此认为遗传密码是多余的(或简并的):一些氨基酸确实可以由几种不同的三联体编码。
但每个三联体将对应于单个氨基酸。最后,有三个三联体不编码任何氨基酸,它们代表停止(或无意义)密码子,分别是UAA,UGA和UAG 。
参考资料来源:百度百科--脱氧核糖核酸
参考技术BNFA确定化的时候,包含NFA初态的那个DFA状态就是确定后的DFA的初态
DFA的终态就是所有包含了NFA终态的DFA的状态
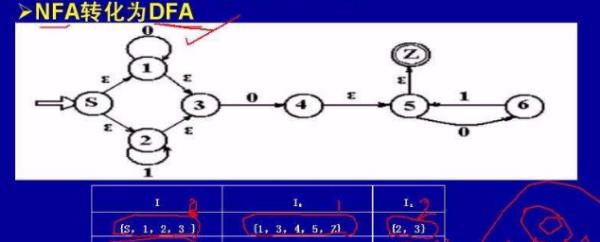
就如下边的例子,是一个初态为1,终态为6,7,9的NFA经过确定化得到的转换矩阵,右侧是将左侧的转换矩阵改名之后的DFA,也就是最后得到的DFA
对于DFA来说,他的初态就是包含了NFA唯一初态1的那个状态,就是左边的1,2右边的1了
终态则是左边的2,4,5,6,7和3,8,9和9对应的就是右边的2,4,5
不知道我这样解释您能不能理解~
答非所问,而且这个答案是其他问题批发来的,我看过。。。
编译原理:非确定的自动机NFA确定化为DFA
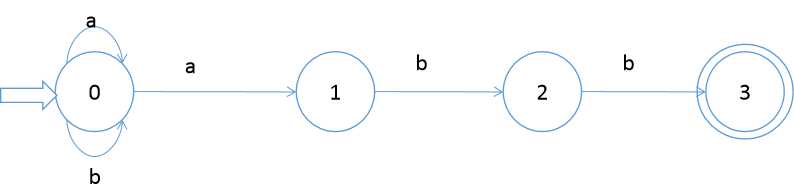
1.设有 NFA M=( {0,1,2,3}, {a,b},f,0,{3} ),其中 f(0,a)={0,1} f(0,b)={0} f(1,b)={2} f(2,b)={3}
画出状态转换矩阵,状态转换图,并说明该NFA识别的是什么样的语言。
解析:
状态转换图如下:
a
b
0
{0,1}
0
1
2
2
3
3
识别语言为:(a | b)*abb
2.NFA 确定化为 DFA
1.解决多值映射:子集法
1). 上述练习1的NFA
解析:
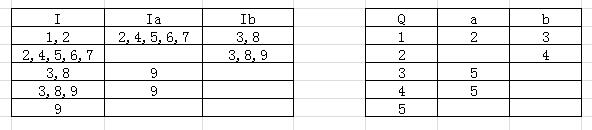
根据1的NFA构造DFA状态转换矩阵如下:
a
b
A
{0}
{0,1}
{0}
B
{0,1}
{0,1}
{0,2}
C
{0,2}
{0,1}
{0,3}
D
{0,3}
{0,1}
{0}
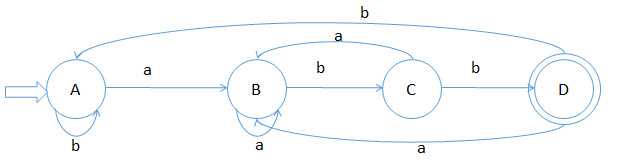
根据1的NFA构造DFA状态转换图如下:
识别语言:b*aa*(ba)*bb, 与1的NFA的识别的语言相同,都是以abb结尾的字符串的集合。
2). P64页练习3
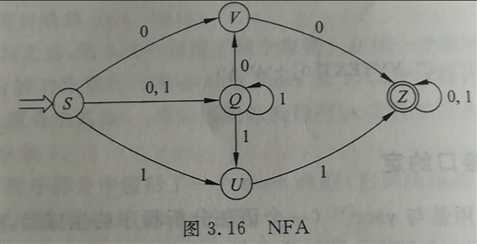
状态转换矩阵如下:
0
1
A
{S}
{Q,V}
{Q,U}
B
{Q,V}
{V,Z}
{Q,U}
C
{V,Z}
{Z}
{Z}
D
{Q,U}
{V}
{Q,U,Z}
E
{V}
{Z}
F
{Q,U,Z}
{V,Z}
{Q,U,Z}
G
{Z}
{Z}
{Z}
状态转换图如下:
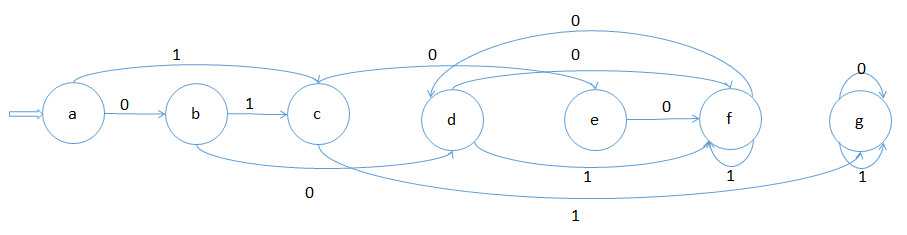
2.解决空弧:对初态和所有新状态求ε-闭包
1). 发给大家的图2
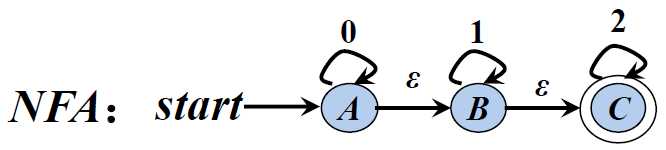
解析:
识别语言:0*(11*2 | 2)2*
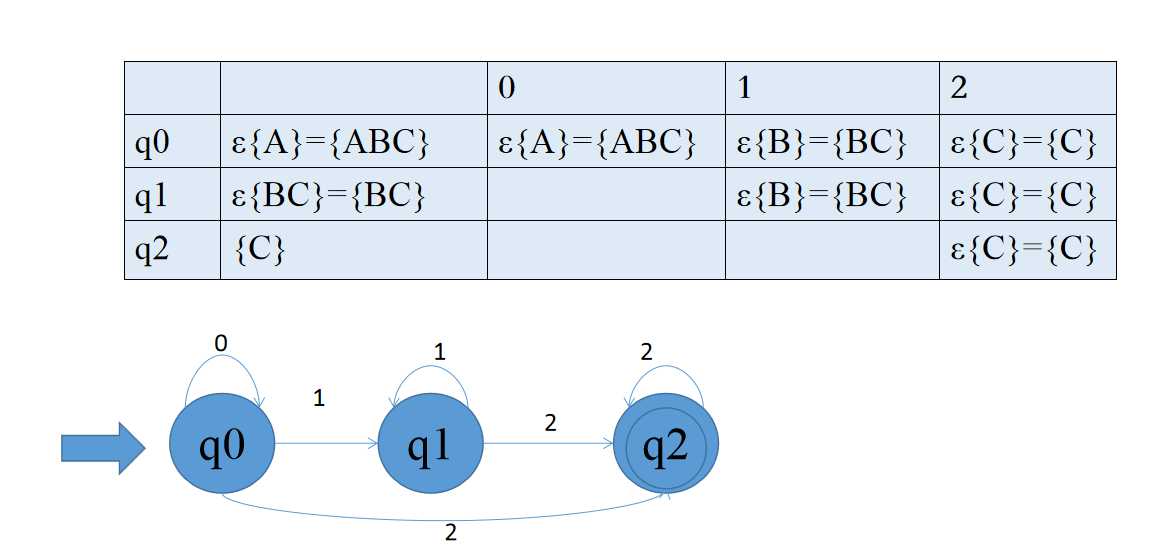
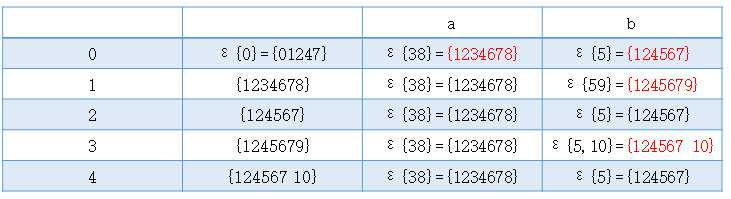
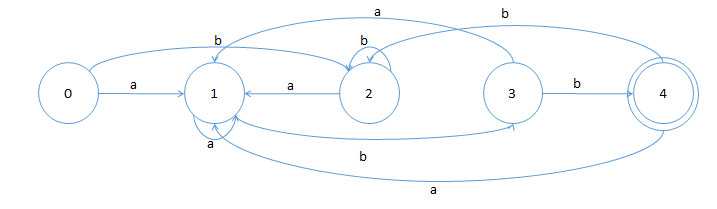
2).P50图3.6
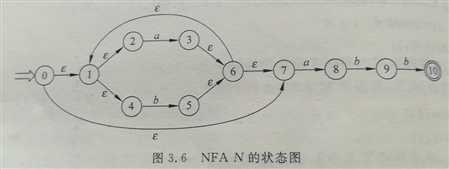
子集法:
f(q,a)={q1,q2,…,qn},状态集的子集
将{q1,q2,…,qn}看做一个状态A,去记录NFA读入输入符号之后可能达到的所有状态的集合。
步骤:
1).根据NFA构造DFA状态转换矩阵
①确定DFA的字母表,初态(NFA的所有初态集)
②从初态出发,经字母表到达的状态集看成一个新状态
③将新状态添加到DFA状态集
④重复23步骤,直到没有新的DFA状态
2).画出DFA
3).看NFA和DFA识别的符号串是否一致。
解析:
识别语言:(a | bb*a)a*(ba)*bb((bb*aa*(ba)*bb)* | (aa*(ba)*bb)*)
以上是关于编译原理NFA转DFA ,请问DFA的初始状态如何确定?的主要内容,如果未能解决你的问题,请参考以下文章