什么是冒泡排序?最形象的分析解读和源码实现不容错过!
Posted Python运维圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是冒泡排序?最形象的分析解读和源码实现不容错过!相关的知识,希望对你有一定的参考价值。
什么是冒泡排序?
冒泡排序的英文Bubble Sort,是一种最基础的交换排序。
大家一定都喝过汽水,汽水中常常有许多小小的气泡,哗啦哗啦飘到上面来。这是因为组成小气泡的二氧化碳比水要轻,所以小气泡可以一点一点向上浮动。
而我们的冒泡排序之所以叫做冒泡排序,正是因为这种排序算法的每一个元素都可以像小气泡一样,根据自身大小,一点一点向着数组的一侧移动。
具体如何来移动呢?让我们来看一个栗子:

有8个数组成一个无序数列:5,8,6,3,9,2,1,7,希望从小到大排序。
按照冒泡排序的思想,我们要把相邻的元素两两比较,根据大小来交换元素的位置,过程如下:
首先让5和8比较,发现5比8要小,因此元素位置不变。
接下来让8和6比较,发现8比6要大,所以8和6交换位置。


继续让8和3比较,发现8比3要大,所以8和3交换位置。
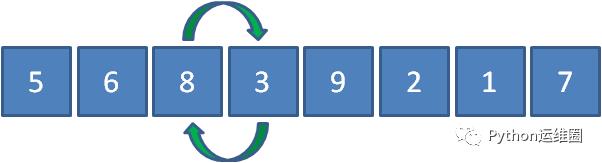

继续让8和9比较,发现8比9要小,所以元素位置不变。
接下来让9和2比较,发现9比2要大,所以9和2交换位置。
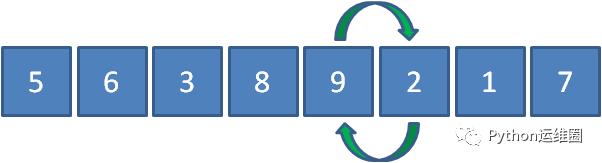

接下来让9和1比较,发现9比1要大,所以9和1交换位置。


最后让9和7比较,发现9比7要大,所以9和7交换位置。


这样一来,元素9作为数列的最大元素,就像是汽水里的小气泡一样漂啊漂,漂到了最右侧。
这时候,我们的冒泡排序的第一轮结束了。数列最右侧的元素9可以认为是一个有序区域,有序区域目前只有一个元素。

下面,让我们来进行第二轮排序:
首先让5和6比较,发现5比6要小,因此元素位置不变。
接下来让6和3比较,发现6比3要大,所以6和3交换位置。


继续让6和8比较,发现6比8要小,因此元素位置不变。
接下来让8和2比较,发现8比2要大,所以8和2交换位置。
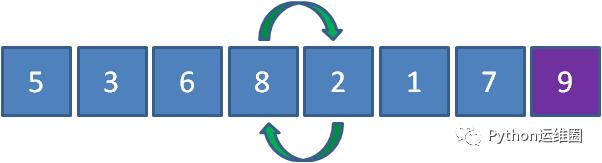

接下来让8和1比较,发现8比1要大,所以8和1交换位置。
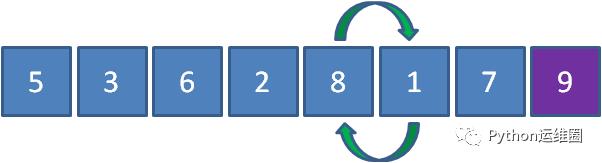

继续让8和7比较,发现8比7要大,所以8和7交换位置。


第二轮排序结束后,我们数列右侧的有序区有了两个元素,顺序如下:

至于后续的交换细节,我们这里就不详细描述了,第三轮过后的状态如下:

第四轮过后状态如下:

第五轮过后状态如下:

第六轮过后状态如下:

第七轮过后状态如下(已经是有序了,所以没有改变):

第八轮过后状态如下(同样没有改变):

到此为止,所有元素都是有序的了,这就是冒泡排序的整体思路。
下面来看看源码是如何实现的。
冒泡排序第一版
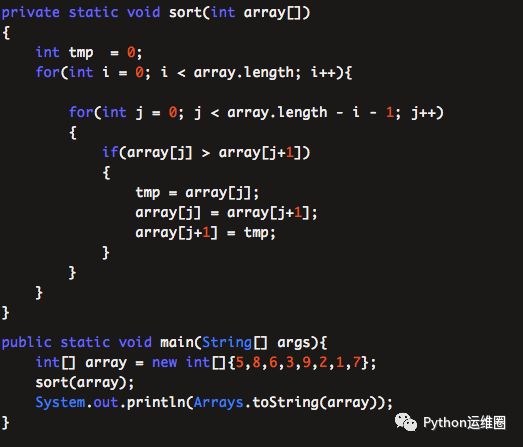
Python版本:
def bubbleSort(lista):
leng=len(lista);
for i in range(0,leng):
for j in range(1,leng-i):
if lista[j-1]>lista[j]:
lista[j-1],lista[j]=lista[j],lista[j-1]
return lista
代码非常简单,使用双循环来进行排序。外部循环控制所有的回合,内部循环代表每一轮的冒泡处理,先进行元素比较,再进行元素交换。
原始的冒泡排序有哪些优化点呢?
让我们回顾一下刚才描述的排序细节,仍然以5,8,6,3,9,2,1,7这个数列为例,当排序算法分别执行到第六、第七、第八轮的时候,数列状态如下:

很明显可以看出,自从经过第六轮排序,整个数列已然是有序的了。可是我们的排序算法仍然“兢兢业业”地继续执行第七轮、第八轮。
这种情况下,如果我们能判断出数列已经有序,并且做出标记,剩下的几轮排序就可以不必执行,提早结束工作。
冒泡排序第二版
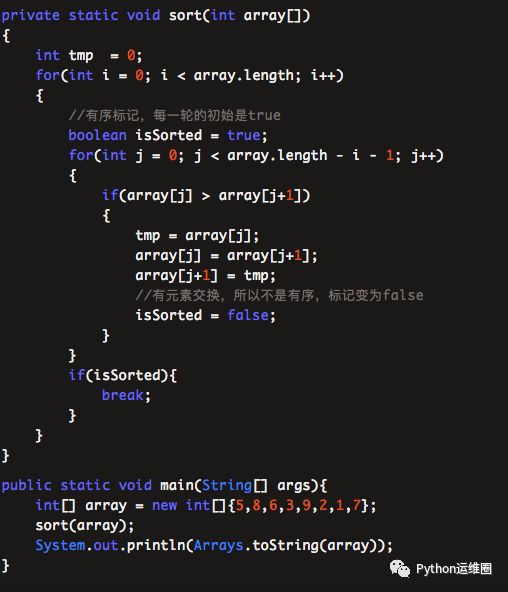
Python改进版
def bubbleSort2(lista):
leng = len(lista)
flag = True
while(flag):
flag = False
for i in range(0,leng):
for j in range(1,leng-i):
if lista[j-1] > lista[j]:
lista[j-1],lista[j] = lista[j],lista[j-1]
flag = True
return lista
这一版代码做了小小的改动,利用布尔变量isSorted作为标记。如果在本轮排序中,元素有交换,则说明数列无序;如果没有元素交换,说明数列已然有序,直接跳出大循环。
还有木有可能再做进一步的性能优化呢??
为了说明问题,咱们这次找一个新的数列:

这个数列的特点是前半部分(3,4,2,1)无序,后半部分(5,6,7,8)升序,并且后半部分的元素已经是数列最大值。
让我们按照冒泡排序的思路来进行排序,看一看具体效果:
第一轮
3和4比较,发现3小于4,所以位置不变。
4和2比较,发现4大于2,所以4和2交换。


4和1比较,发现4大于1,所以4和1交换。
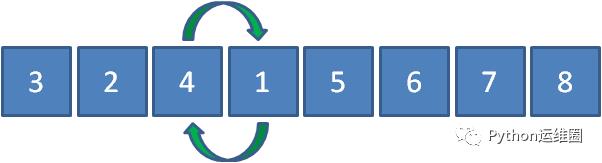

4和5比较,发现4小于5,所以位置不变。
5和6比较,发现5小于6,所以位置不变。
6和7比较,发现6小于7,所以位置不变。
7和8比较,发现7小于8,所以位置不变。
第一轮结束,数列有序区包含一个元素:

第二轮
3和2比较,发现3大于2,所以3和2交换。


3和1比较,发现3大于1,所以3和1交换。


3和4比较,发现3小于4,所以位置不变。
4和5比较,发现4小于5,所以位置不变。
5和6比较,发现5小于6,所以位置不变。
6和7比较,发现6小于7,所以位置不变。
7和8比较,发现7小于8,所以位置不变。
第二轮结束,数列有序区包含一个元素:

其实在右面的许多元素已经有序了,可是每一轮还是多浪费了几次轮询迭代,这里还有可优化的空间麽??
这个问题的关键点在哪里呢?关键在于对数列有序区的界定。
按照现有的逻辑,有序区的长度和排序的轮数是相等的。比如第一轮排序过后的有序区长度是1,第二轮排序过后的有序区长度是2 ......
实际上,数列真正的有序区可能会大于这个长度,比如例子中仅仅第二轮,后面5个元素实际都已经属于有序区。因此后面的许多次元素比较是没有意义的。
如何避免这种情况呢?我们可以在每一轮排序的最后,记录下最后一次元素交换的位置,那个位置也就是无序数列的边界,再往后就是有序区了。
冒泡排序第三版
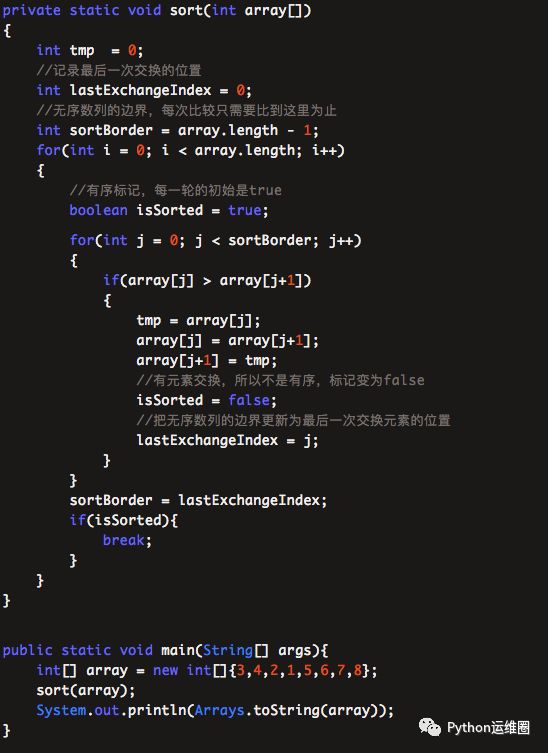
这一版代码中,sortBorder就是无序数列的边界。每一轮排序过程中,sortBorder之后的元素就完全不需要比较了,肯定是有序的。
冒泡排序就讲到这里了,作为运维开发的你,能熟练的写出来了麽?虽然在实际的生产编程环境中很少直接用到冒泡排序,但是对于编程思维的锻炼,还是很有帮助的。可能帮助最大的,还是找在工作面试的时候,就像中国的应试教育 。放下手机,去写写试试吧。
。放下手机,去写写试试吧。
Linux干货分享
Python干货分享
更多干货请猛戳下面的阅读原文↓↓↓
以上是关于什么是冒泡排序?最形象的分析解读和源码实现不容错过!的主要内容,如果未能解决你的问题,请参考以下文章