你真的会写冒泡排序吗?
Posted 王雄宁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你真的会写冒泡排序吗?相关的知识,希望对你有一定的参考价值。
Bubble Sort 是什么?
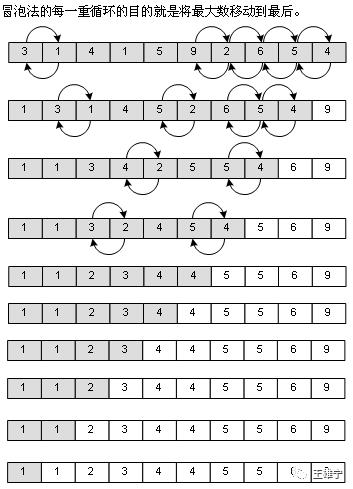
说起面试题,在众多有趣又有难度的题目中,排序算法是我们常常需要考的题型,而其中有一道必考题,那就是实现冒泡排序。
它很好写,却很难写好,可以想象问了这道题后,在3分钟内面试的同学会相当自信的将那一小段代码交给面试官,剩下的就是看面试官是否能满意你这段冒泡排序的代码了。
冒泡排序是什么呢?在计算机里,我们往往需要对数组进行操作,往往是在操作排好序的数组时时间复杂度最小,比如我们查找数组中某个元素的位置,如果是无序数组我们需要顺序查找逐个查找,这样在最好的情况下也就是第一个元素就查到了,它的时间复杂度是O(1),最坏要达到O(n)。而如果是排好序的数组,我们就可以用一些查找算法比如二分查找来优化算法最坏情况也才只有O(logn),必要时我们还是把数组排好序可以减少操作的时间复杂度。
冒泡排序的思想就是从左向右依次比较,把大的放右边小的放左边,这样经过n次交换之后数组就排好序了。
基础版 Bubble Sort
如果在面试中遇到冒泡排序的题,大家可能很自信的写出如下代码:
func bobbleSort(s []int) {
for i := 0; i < len(s)-1; i++ {
for j := 0; j < len(s)-i-1; j++ {
if s[j] > s[j+1] {
s[j], s[j+1] = s[j+1], s[j]
}
}
}
}
我相信每一个程序员都可以写出这样的代码,写出这样的冒泡排序代码只能相当于及格,我们当然不满足于这样烂大街的代码。
其实上述代码还有一种优雅的写法:
func bubbleSort(s []int) {
n := len(s)
for sorted := false; !sorted; n-- {
for j := 0; j < n-1; j++ {
if s[j+1] < s[j] {
s[j+1], s[j] = s[j], s[j+1]
sorted = true
}
}
sorted = !sorted
}
}
有兴趣的同学可以研究一下,我这里就不解释了!
上面冒泡排序代码的时间复杂度是O(n^2),这样的时间复杂度似乎有些太高了。我们看看怎么优化一下上面算法呢?
改进B版
我们来分析一下上面冒泡排序算法,每经过一次外层循环,都会有一个新的元素就位,对于第一次而言,这个新的元素就是全局最大的元素。这样不断循环,右侧白色有序的部分会不断增加,左侧灰色无序的部分不断减少,我们可以肯定白色部分一定是有序的,但是我们不能保证灰色部分一定是无序的,灰色部分有可能其中一部分是有序的,甚至全部都是有序的。
那么我们如何能够提早的判断出这种情况从而提前结束这个算法呢?
我们可以在每一次扫描交换中记录一下,是否曾经真的存在逆序元素,如果曾经没有做过至少一次扫描交换,说明已经是排好序的了,我们直接结束算法就好了啊。那我们来看下冒泡排序版本B的代码:
func bobbleSort(s []int) {
for i := 0; i < len(s)-1; i++ {
sorted := true
for j := 0; j < len(s)-i-1; j++ {
if s[j] > s[j+1] {
sorted = false
s[j], s[j+1] = s[j+1], s[j]
}
}
if sorted {
break
}
}
}
这个版本主要不同在于我们加一个标志 sorted 来判断 if 语句曾经发生交换过。
不过我们对于这个算法对改进并不满足于此,因为在其他情况下,或者更多情况下,这个算法依然存在继续改进对空间。
再改进C版
为此我们来考察一个数组,这个数组有长度比较悬殊对一个前缀和一个后缀,就好比下面绿色部分是前缀,红色是后缀。后缀的元素都已经按顺序排列而且已经是严格就位。所有乱序的元素都集中于相对更短对前缀中。
对于这样一个实例,刚才我们经过优化过的冒泡排序算法会如何表现呢?
首先它会做第一趟扫描交换,并且确认最后这个位置的元素已经就位,虽然它原本就已经是就位的了。虽然在我们的后缀中存在大量的就位元素,但是由于在前缀中存在交换,sorted 会标记为 false,也就是说算法接下来还会继续下去。尽管能够判断就位的元素的数目会继续增加,但是与刚才同理,我们依然不能确认可以提前退出,也就是说我们还要继续循环判断。
对于这样一个例子,我们需要多少次扫描交换呢?这个扫描交换的趟数不会超过前缀的长度。为什么呢?因为我们此前所做的各趟扫描交换,与其说对整个数组做扫描处理,不如说在实际中它影响的只是前缀中对元素。
我们每一趟对扫描交换所起的实质作用无非是在前缀中令一个一个的后缀元素依次就位。
我们能否及时检测出这样的情况呢?重新审视这个例子,我们会发现所多余出来的时间消耗无非是在后缀中对已经就位对这些元素反复的扫描,而这些元素是不需要交换的。
我们可以通过记录在上一趟扫描交换中最后一次进行交换的位置,就很容易确定,在上一次扫描中有多长的后缀实际上没有进行任何交换,也就是说他们中的元素都是就位的,然后我们只需要将原先的右侧标志hi指向这个新的位置。
我们来看一下代码吧!
func bubbleSort(s []int) {
hi := len(s) - 1
for hi > 0 {
last := 0
for i := 0; i < hi; i++ {
if s[i] > s[i+1] {
s[i+1], s[i] = s[i], s[i+1]
last = i
}
}
hi=last
}
}
虽然我们对冒泡排序进行了一系列优化,但是最坏情况下它的时间复杂度仍然是O(n^2)。
面试官:for range和普通遍历谁的效率更高?
以上是关于你真的会写冒泡排序吗?的主要内容,如果未能解决你的问题,请参考以下文章