Python 和 C++ 下字符串查找速度对比,你觉得Python适合算法竞赛吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 和 C++ 下字符串查找速度对比,你觉得Python适合算法竞赛吗相关的知识,希望对你有一定的参考价值。
参考技术A一位同学最近在备战一场算法竞赛,语言误选了 Python ,无奈只能着手对常见场景进行语言迁移。而字符串查找的场景在算法竞赛中时有出现。本文即对此场景在 Python 和竞赛常用语言 C++ 下的速度进行对比,并提供相关参数和运行结果供他人参考。
本次实测设置两个场景:场景 1 的源串字符分布使用伪随机数生成器生成,表示字符串查找的平均情况;场景 2 的源串可连续分割成 20,000 个长度为 50 的字符片段,其中第 15,001 个即为模式串,形如“ab…b”(1 个“a”,49 个 “b”),其余的字符片段形如“ab…c”(1 个“a”,48 个“b”,1 个“c”)。
本次实测中,Python 语言使用内置类型 str 的 .find() 成员函数,C++ 语言分别使用 string 类的 .find() 成员函数、 strstr 标准库函数和用户实现的 KMP 算法。
IPython 的 %timeit 魔法命令可以输出代码多次执行的平均时间和标准差,在此取平均时间。C++ 的代码对每个模式串固定运行 1,000 次后取平均时间。
以下时间若无特别说明,均以微秒为单位,保留到整数位。
* 原输出为“2.63 ms”。IPython 的 %timeit 输出的均值保留 3 位有效数字,由于此时间已超过 1 毫秒,微秒位被舍弃。此处仍以微秒作单位,数值记为“2630”。
本次实测时使用的设备硬件上劣于算法竞赛中的标准配置机器,实测结果中的“绝对数值”参考性较低。
根据上表中的结果,在给定环境和相关参数条件下,场景 1 中 Python 的运行时间大约为 C++ 中 string::find 的五分之一,与 std:strstr 接近;而在场景 2 中 Python 的运行时间明显增长,但 C++ 的前两种测试方法的运行时间与先前接近甚至更短。四次测试中,C++ 的用户实现的 KMP 算法运行时间均较长,长于同条件下 Python 的情况。
Python 中的内置类型 str 的快速查找( .find() )和计数( .count() )算法基于 Boyer-Moore 算法 和 Horspool 算法 的混合,其中后者是前者的简化,而前者与 Knuth-Morris-Pratt 算法 有关。
有关 C++ 的 string::find 比 std::strstr 运行时间长的相关情况,参见 Bug 66414 - string::find ten times slower than strstr 。
Why do you think strstr should be slower than all the others? Do you know what algorithm strstr uses? I think it\'s quite likely that strstr uses a fine-tuned, processor-specific, assembly-coded algorithm of the KMP type or better. In which case you don\'t stand a chance of out-performing it in C for such small benchmarks.
KMP 算法并非是所有线性复杂度算法中最快的。在不同的环境(软硬件、测试数据等)下,KMP 与其变种乃至其他线性复杂度算法,孰优孰劣都无法判断。编译器在设计时考虑到诸多可能的因素,尽可能使不同环境下都能有相对较优的策略来得到结果。因而,在保证结果正确的情况下,与其根据算法原理自行编写,不如直接使用标准库中提供的函数。
同时本次实测也在运行时间角度再次印证 Python 并不适合在算法竞赛中取得高成绩的说法,你们觉得呢?平仑区留下你的看法。
C++拾趣——STL容器的插入删除遍历和查找操作性能对比(ubuntu g++)——删除
相关环境和说明在《C++拾趣——STL容器的插入、删除、遍历和查找操作性能对比(ubuntu g++)——插入》已给出。本文将分析从头部、中间和尾部对各个容器进行删除的性能。(转载请指明出于breaksoftware的csdn博客)
删除
头部删除
元素个数>15000

vector容器性能最差。由于它和其他容器性能差距比较大,我们将其从图中去除。

除了set表现不好之外,其他容器都差不多。其中表现最好的是list和forward_list。
元素个数<4096

由于vector持续的表现的最差,我就没在上图中将其列出。
set在这个场景下表现也很差。deque在元素超过2500左右时,“迎头赶上”,成为第三差的容器。
元素个数<1024

可以看到deque的性能在此时是最好的,明显要优于list和forward_list。
元素个数<256

对于小容器,deque、list和forward_list的表现最好。
对比结果:
vector表现最差。
容器元素比较多时,list和forward_list性能最好。
元素少于2500左右时,deque的性能最好。
中间删除
元素个数>15000
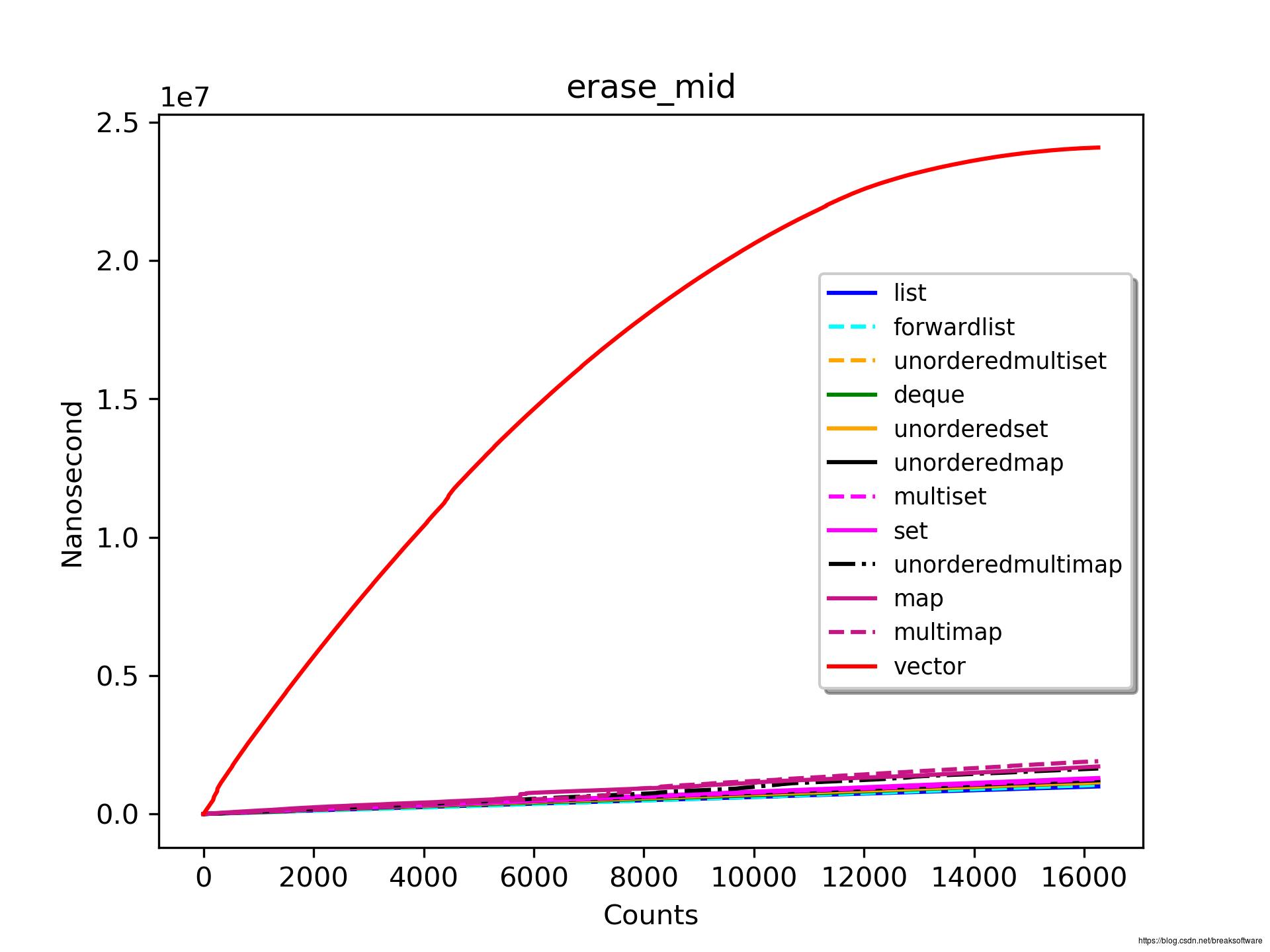
vector的性能最差。
除了vector,表现最差的是map系列的三个容器:multimap、map和unordered_multimap。
表现最好的是list和forward_list。
由于vector表现的太差,之后中间删除的图例都不再列出它。
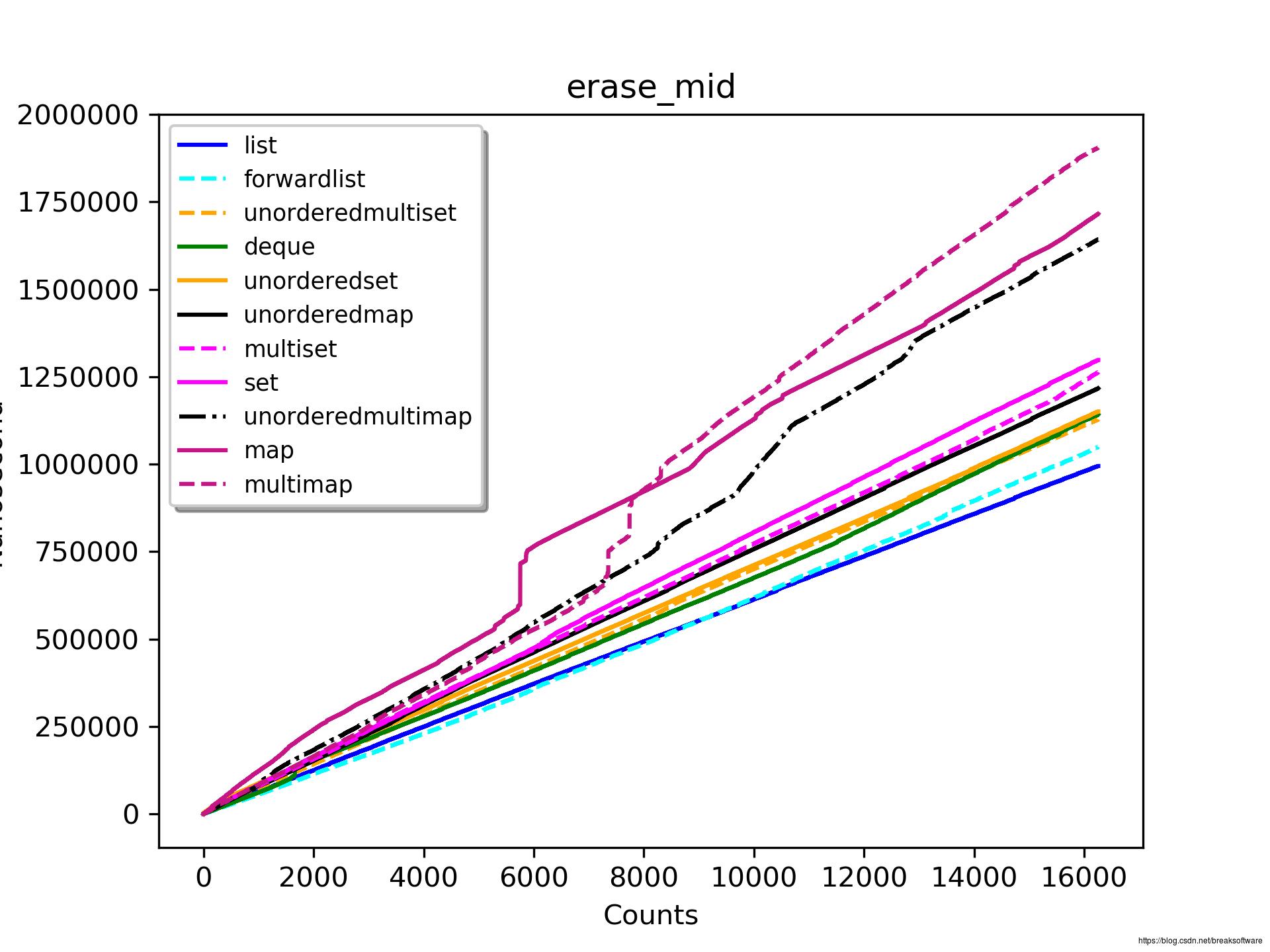
元素个数<4096

deque在元素个数达到1800左右执行了高耗时操作。在此之前它要优于list。
元素个数<256

对于小容器,效率最好的依次是:forward_list、deque和list。
对比结果:
vector性能最差。
list和forward_list在各种容器大小时,表现都很好。
deque在元素个数少于1800左右时,表现仅次于forward_list。
尾部删除
元素个数>15000
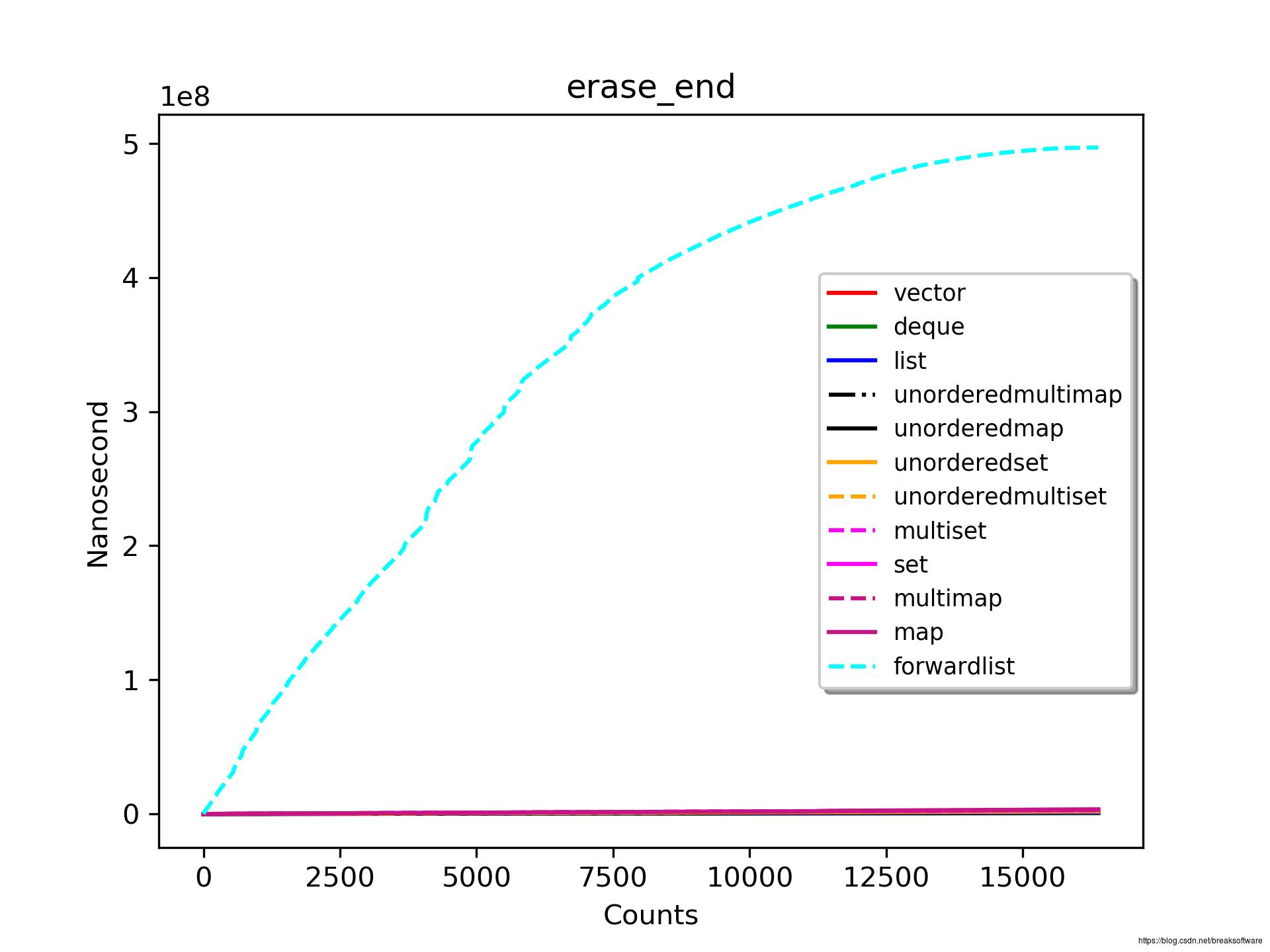
之前各个场景下表现优异的forward_list此时表现的极差。由于差异非常大,之后各个容器大小图例中都将不包含它。

vector表现最优,其次是deque和list。非关联容器的表现都由于关联容器。
元素个数<256

大容器的表现在小容器上也有着相似的体现。
结果对比:
vector的效率最优。其次是deque和list。
forward_list效率最差。
结论:
vector在头部和中间删除时,表现极差;在尾部删除时,表现优异。
forward_list在尾部删除时,表现极差;头部和中间删除时,表现优异。
list在各个场景下表现均较为优异。
deque在元素少于2500左右时,效率比较优秀。元素超过这个阈值后,头部删除效率较差,中间和尾部删除仍然不错。
文中图例可从以下地址获取:https://github.com/f304646673/stl_perf/tree/master/linux
以上是关于Python 和 C++ 下字符串查找速度对比,你觉得Python适合算法竞赛吗的主要内容,如果未能解决你的问题,请参考以下文章
C++拾趣——STL容器的插入删除遍历和查找操作性能对比(ubuntu g++)——遍历和查找