神经网络模型与AI芯片的军备竞赛
Posted 全球技术前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络模型与AI芯片的军备竞赛相关的知识,希望对你有一定的参考价值。
OpenAI是由Elon Musk(Tesla和SpaceX创始人和CEO),Sam Altman(OpenAI CEO), Ilya Sutskever(OpenAI首席科学家),Greg Brockman(AI科学家),Wojciech Zaremba(AI科学家),John Schulman(AI科学家)于2015年底创立的和以赢利为目的的AI研究实验室,旨在确保通用人工智能(GAI/AGI)技术将造福全人类。
GPT(Generative Pre-Training)非监督训练语言神经网络模型是OpenAI在过去几年一直在开发的大型NLP(自然语言理解)模型,目前已有GPT-1、GPT-2和GPT-3三代,用于自动生成上下文相关的下一个文本段落,与GAN(Generative Adversarial Network, 生成对抗网络)自动生成下一幅相关图像功能类似。GAN已经广泛应用于游戏、动画、视频和电影制作。若干年后,人类将很难用肉眼区分一篇文章或一幅画究竟是出于某人或机器之手。
2019.7,OpenAI宣布与Microsoft达成合作协议,后者向OpenAI投资10亿美元,并获得独家为运行OpenAI所有技术、产品和解决方案提供云服务的权利。当这个合作协议宣布时,网上有很多人质疑Microsoft如何才能将此投资变现。现在从OpenAI发布的GPT-3看,Microsoft很可能是投资了一座拥有巨大潜力的大金矿!
OpenAI于2020年5发表的一篇题为”Language Models are Few-Shot Learners”的研究文章首次介绍了超级NLP(自然语言理解)神经网络模型GPT-3,当时并没有引起人们特别大的注意,毕竟这是AI学术研究领域的最前沿技术,是为了解决GAI/AGI大问题的。但是当OpenAI于七月中开放GPT-3API测试版供申请者试用后, 好评如潮,语言和文学创作的一个新时代即将来临,将对人类的社会和政治生活带来深远的影响!
阿根廷Open Zeppelin的创始人ManuelAraoz在试用GPT-3后惊叹:“OpenAI刚开发的GPT-3可能是比特币以来最大的技术发明/ OpenAI’s GPT-3 may be the biggest thingsince bitcoin!”他并预测: “与它的两个前身(PTB和OpenAIGPT-2)不同,OpenAIGPT-3最终将被广泛地用来伪装文本的作者是一个有兴趣的人,对各个社区产生不可预测的有趣影响。我进一步预测,这将激发有才华的业余爱好者在创意上淘金,以训练相似的模型并使它们适应各种目的,包括:模拟新闻,“新闻研究”,广告,政治和宣传”。
Azuro创始人Sushant Kumar使用GPT-3的接口,写了一个简单的Twitter自动书写https://thoughts.sushant-kumar.com/<任何字>。试用者可将上述URL/链接的<任何字>替换成随便一个字,GPT-3会自动生成一条相关的Twitter信息,人们无法辨别是人工写的还是机器写的。例如,https://thoughts.sushant-kumar.com/AI(回车键)将自动生成“The biggest risk of AI is that people conclude it’s impossible and quit trying todo it, like we’ve reached some fundamental upper limit.”/“AI的最大风险是,人们认为这是不可能的,因此放弃尝试这样做,就像我们已经达到一些基本上限一样。”,而且重复按回车键输入同一个字(AI),GPT-3会生成不同的相关语句。这个程序还仅仅是使用GPT-3API的一个简单的演示, 如果输入一些关键字,则GPT-3会自动写成文章,而人们则会无法辨别是机器(GPT-3)还是人工写的!
Mario Klingemann在Twitter上分享了使用GPT-3文本生成器模仿十九世纪英国作家JeromeK. Jerome的风格,自动书写的文章,其中一篇题为”The “Importance of being on Twitter”(https://twitter.com/quasimondo/status/1284509525500989445)。他只需给出要写的文章的题目、作者名字和文章第一个It字,选择喜欢的作者风格和语言能力程度,以及喜、怒、哀、乐的心情,GPT-3就自动写了一篇洋洋洒洒的六页文章。
自称为”科学与技术启发艺术的制造者”的ZeroCater创始人和前任CEO Arram Sabeti在其个人网站http://arr.arm/上发表了他试用GPT-3自动写的各种风格的小说、文章、诗歌、歌词、电容手册、个人简历等,他的结论是:GPT-3:An AI that’s eerily good at writing almost anything! https://arr.am/2020/07/09/gpt-3-an-ai-thats-eerily-good-at-writing-almost-anything/。
GPT-3的测试版已上线, 人们可申请免费试用, 访问接口为https。OpenAI计划于2020年下半年推出GPT-3的商业版,以订阅的云服务形式提供AI服务。图2是GPT-3Playground的用户介面, 有机会的读者可以试试不同参数对所自动生成的作品的影响。
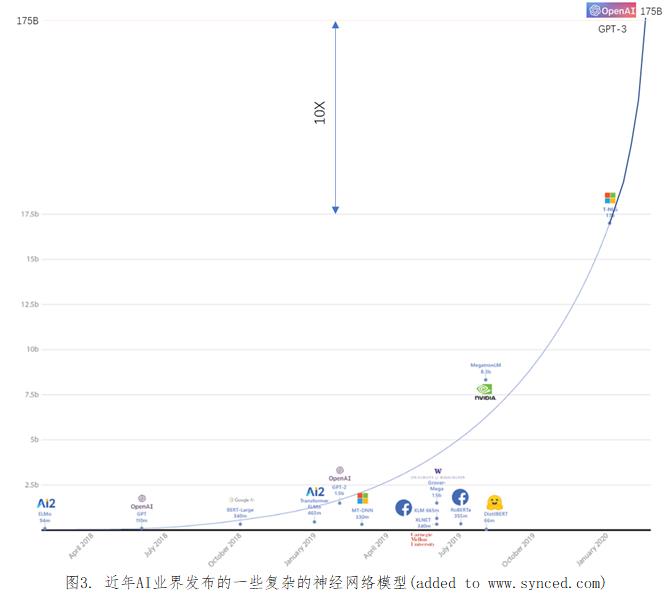
根据OpenAI于2020.5发表的研究报告,GPT-3 NLP神经网络模型有1750亿个参数(参数: 由训练过程确定数值的权重/weights), 是OpenAI于2019年11月发布的15亿个参数的GPT-2模型的117倍,Microsoft 170亿个参数T-NLG模型的10倍, 是Nvidia 83亿个参数的Megatron-LM的20倍。对于基于深度学习的神经网络模型而言, 参数的个数越多就能充分挖掘和利用训练文本数据集中的信息。图3是业界近几年发布的一些复杂神经网络模型, 平均大概是每3.5月模型复杂度(参数个数)翻一倍, 而过去一年则翻了10倍!
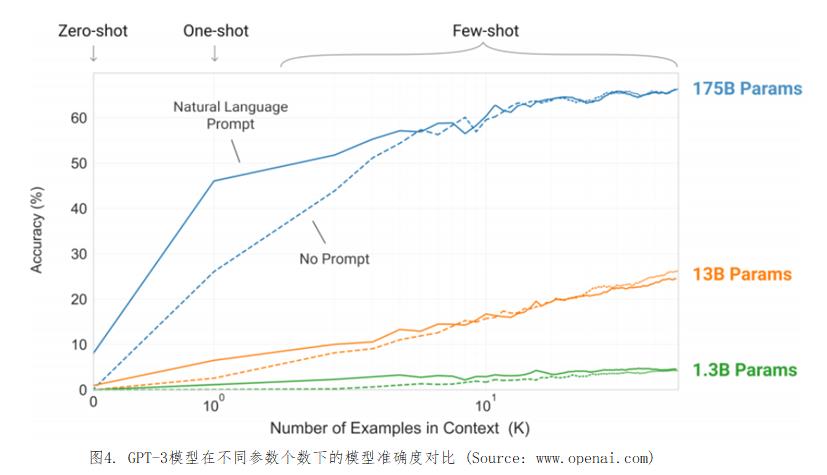
GPT-3是在2019.11月发布的15亿个参数的GPT-2模型的基础上改进的,但功能和准确度都要比GPT-1和GPT-2好的多。图4是OpenAI发表GPT-3与两个较小模型在文本不同样本数量下的精度/准确度。
有了超级神经网络,就需要高性能的计算机系统来训练。如图5所示,OpenAI估计使用3000亿个训练样本(tokens),训练1750亿个参数的GPT-3一遍(one epoch)所需的计算能力为3640 Petaflops-days, 或3.14x1023次浮点运算, 即使用1 Petaflops (1万亿次浮点运算每秒)的超级计算机系统需训练3640天, 或1 Exaflops(100万亿次浮点运算每秒)的超级计算机系统需314000秒/约88小时, 假定现实中不可能达到的100%并行处理加速效率。而Exaflops/百万亿次浮点运算每秒的超级计算系统尚未问世,是全世界争取在2021-2023年达到的目标, 当然这个目标的flops指的是IEEE 64位双精度浮点运算, 而AI/DL神经网络模型训练无需使用64b双精度, 而只需使用32b单精度或更低的浮点精度。

OpenAI在该研究报告中没有介绍他们是在什么系统上训练GPT-3模型的。根据当前云上的V100和A100GPU实例价格估算, 用3000亿个样本训练GPT-3一遍(oneepoch), 大概至少需$5M! 而要达到很高的模型精度, 通常需要训练很多遍, 几百甚至上万遍, 训练100遍就是$500M!目前构建一套Exascale系统大概需要$500M的预算, 耗电30MW-40MW。
因此诸如GPT-3之类的超级复杂模型,且不说所需要的超级人才,就是开源了,也只有财力雄厚的玩家才能玩得起。为了防止被滥用,OpenAI就没有开源前一代GPT-2模型; 对GPT-3,OpenAI也只计划以云服务和httpsAPI形式向用户开放。这种模式估计以后将会成为超大型复杂神经网络开发和运行的商业模式, 如同GPS(全球定位系统)服务, 但要收费。
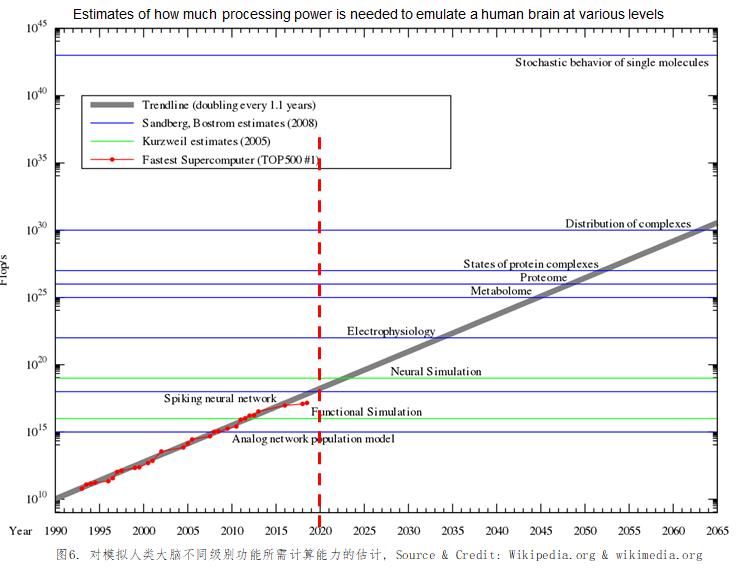
尽管GPT-3模型已经超级复杂了, 但对于人类大脑而言,还仅仅是入门级。下图5为美国发明家和未来学专家Ray Kurzweil、瑞典计算神经科学博士、未来学专家和作家Anders Sandberg、瑞典哲学家Nick Bostrom对在不同级别模拟人脑功能所需要的计算能力的估计。根据Ray Kurzweil的估计, 即使是基于一个简单的神经元开关模型, 一个普通人大脑的计算能力就相当于1016次浮点运算每秒(即10 Petaflops)。这是2011年全世界Top500最快的超级计算机系统才能达到的水平, 即使是基于Nvidia今天最快的624 TFLOPS(FP16或BF16浮点)的A100GPU, 也至少需要16块, 系统耗电至少10KW。由此可见, 人类对自己大脑是如何工作的还是知之甚少, 以目前的计算模型和方法来实现人类大脑的功能(即GAI或AGI的目标)似乎是不可持续的。
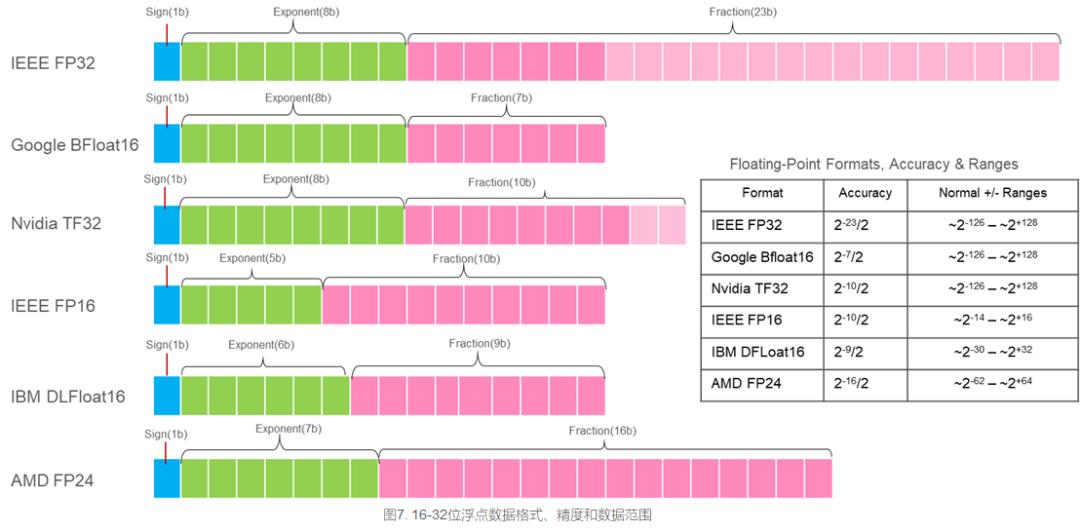
在过去几年基于深度学习(DL,Deep Learning)的AI技术流行之前,比较流行的数据格式有8位整数(INT8)、16位整数(INT16)、32位整数(INT32)、64位整数(INT64)、32位单精度浮点(FP32)和双精度64位浮点(FP64);尽管IEEE-7541985标准也定义了16位半精度浮点(FP16),但用的很少。在浮点数据格式中,FP64在科学计算应用中普遍使用,而FP32则在数字信号处理应用中流行。最初的AI/DL训练使用的是FP32而不需要超级参数(注:超级参数为控制神经网络训练过程并确定网络模型参数值的参数,如每次训练过程的批处理样本个数、学习率等等)调优就可以收敛,不必采用FP64的高精度;而且后来的很多实验表明采用FP16也可以收敛,但是需要调优超级参数, 但是能否保证对所有的网络模型都收敛仍是个问题。进一步的研究和实验表明,大幅度降低FP32的精度,但保持FP32的数据范围,可以达到FP32数据格式同样的收敛速度和模型精度,而且不必调优训练过程的超级参数(注:调优超级参数缩短训练时间与必须调优超级参数才能收敛是两回亊)。这就是Google发明和已被Google TPU、Intel Xeon处理器、Intel FPGA、Nvidia GPU、ARMv8.6-A和TensorFlow接受和实现的BFloat16,简称BF16。
相对于FP32,在同样的计算性能下,BF16可以减少内存带宽要求50%; 或者说,在同样的内存带宽条件下, 可以提高1倍训练性能。除了节省内存访问带宽外,由于小数位的减少,BF16的乘法器比FP32小8倍,比FP16小2倍。同时16b和32b更与内存器件的数据宽度匹配。以GPT-3模型为例,若参数采用FP32格式,则175B个参数就需要700GB超高带宽内存(HBM);若采用BF16,则只需350GB,就有可能将GPT-3模型塞进由16颗超高速互连GPU组成的计算节点(即节点内多个GPU间模型并行,至少512GBHBM内存)。加上数据压缩技术,可进一步减少模型参数对内存的要求。
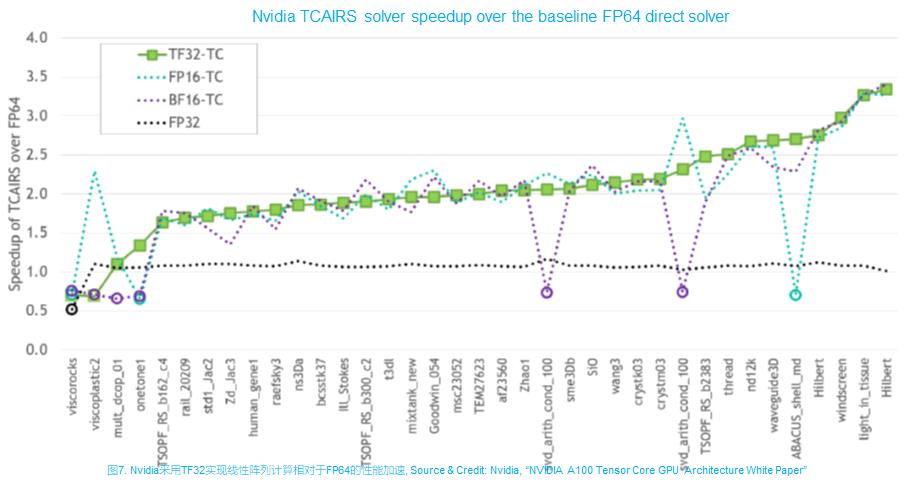
除了BFloat16外,还有Nvidia TF32, AMD FP24和IBM DLFloat16。Nvidia的新一代Ampere GPU已经实现了TF32,AMD的Radeon R300 & R420 GPU则实现了FP24。从数据转换角度,BFloat16和TF32与FP32的转换最简单,直接丢弃最低一些小数位即可。TF32和FP24主要兼顾AI训练和HPC线性方程应用。Nvidia发表的研究测试结果表明,基于TF32的线性方程程序库TCAIS对所测试的37个问题,绝大对数可收敛于FP64的精度且性能比FP32提升50%-250%,但也有少数不收敛;BF16和FP16都有一些不收敛的。如同AI训练一样,自动混合精度对HPC线性方程应用也将会是很有效的解决方法。
为了为复杂神经网络模型的训练提供尽可能高的算力,各大AI芯片公司纷纷推出了号称具有超高计算性能的芯片:
GraphCore总部位于英国,成立于2012年,到目前已融资$460M,并于2018年发布了其第一代MK1IPU芯片(代号Colossus)及系统产品,但在过去几年没有取得什么明显的市场成功。GraphCore于2020.7.15日发布了其声称可于2020年第四季度批量供货的第二代AI芯片Colossus MK2 GC200IPU的规格, 并称之为全世界至今最复杂的芯片,性能比其上一代MK1芯片提升8倍,其主要规格如下:
如何华为、Nvidia、Intel/Habana一样,除了开发AI芯片和软件栈外,GraphCore也和Dell合作,提供基于其芯片的AI服器,如图9。GraphCore的AI服务器基本构建单元为搭载4颗GC200芯片的M2000,使用时通过以太接口挂在一台X86服务器,且最多8台M2000可挂在一台X86,用户通过X86服务器介面使用M2000。M2000规格中的”Upto 450GB Exchange Memory和180TB/sExchange Memory Bandwidth”指标有虚假误导市场之嫌,因为450GB是指挂在IPU-Gateway芯片的两通道DDR4 DIMM容量,其理论带宽不超过2x8x3.2G= 51.2GB/s; 而180TB/s指的则是4块GC200内部SRAM(每块芯片900MB)的总带宽。将两者放在一起,极易让读者以为是180TB/s带宽的450GB内存。
各个厂家声称的AI训练芯片性能,都是理论峰值性能,其内存层次设计在什么样的网络模型及条件下可以支撑其峰值性能,大家大概都没有底。比如说GraphCore声称其芯片相对于其它芯片更适用于超大型模型训练,因为每个节点可支持450GB的交换内存。但是GC200的片上高速内存(SRAM)才900MB,450GB是片外两通道慢速DDR4 DIMM。对于GPT-3这样的超大型网络模型,900MB容量没什么用,450GB的外部内存又太慢, 根本不可能为计算单元提供足够的数据。
AI训练芯片设计要解决的首要问题是高带宽、大容量内存问题。前者是为了让计算单元有粮吃,不挨饿;后者是为了能够将模型参数等装入片内,因为片外内存带宽对500 TFLOPS及以上的计算部件而言速度太低。业界的主流架构,如华为Ascend 910, Nvidia P100/V100/A100 GPU, Intel/Habana Gaudi等,都采用中小容量SRAM Cache + 大容量HBM内存技术,下一代芯片可望提供64GB以上容量和2TB/s带宽的HBM;GraphCore则采用大容量SRAM+外挂DDR4,但所谓大容量也不到1GB, 外部DDR4又太慢。笔者不看好GraphCore芯片架构的演进前景。
对用户而言,真正有意义的可持续获得的性能,而常用的评价手段是基准测试,但基准测试也有太多局限性,只有参考意义。例如基准程序所测试的神经网络模型规模太小,根本不能反映实用情况, 正如TOP500 HPC系统排名所用的Linpack(HPL)没有什么实用价值一样。即使如此,面向建立AI训练性能基准的MLPerf基准程序自2019.7的0.6版至今,也没有任何更新。
面向AI训练的GPU/AI芯片是业界最复杂的半导体芯片,其性能基准评价也远比通用CPU复杂。影响AI训练芯片实际可获得的性能的因素太多,如内部Tensor核的大小设计在特定神经网络模型时的效率究竟有多高?内存层次及通路设计能否为Tensor核/计算单元提供足够快的数据?芯片间互连是否足够快? 数学算子库和整个软件是否能够充分发挥硬件的性能等等。对用户而言,最有效和最可行的方法是看厂家发布的与自己的应用相同或相似的网络模型的实测性能。
总之, 以深度学习为基础的AI应用才刚刚开始, 但诸如GPT-3之类的模型已复杂到1750亿个参数的惊人复杂程度, 其模型训练处理一遍样本(3000亿个!)所需要的计算性能已达3.14x1023次浮点运算, 而人类还在为实现1x1018次浮点运算每秒的超算系统而努力。GPT-3 NLP神经网络模型已经显示了其强大的语言理解功能,是人类机器语言理解的一个里程碑,或将对人类语言理解、翻译、文学创作和社会生活带来深远的影响。诸如GPT-3之类的超复杂神经网络模型, 只有技术和财力雄厚的企业或国家实验室才能研发得起,以云服务API形式变现成为其商业模式。至于面向深度学习的数据中心AI训练芯片,除了地缘政治因素外, 竞争已经结束了,Intel和GraphCore恐怕很难会抢夺到什么有意义的市场份额,除非出现新的算法/神经网络模型,并且新的优化芯片可以比现有的方案提供若干倍以上的性价比和/或能效比。此外,数据中心AI训练和推理芯片或将走向统一。
以上是关于神经网络模型与AI芯片的军备竞赛的主要内容,如果未能解决你的问题,请参考以下文章
AI简报20220225期这枚仿人脑神经芯片跑AI模型超省电OPPO Find X5系列发布