神经网络模型在违约预测中的应用
Posted 数据建模与风控
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络模型在违约预测中的应用相关的知识,希望对你有一定的参考价值。
一、为什么要引入神经网络模型
(1)神经网络与深度学习
深度学习可以用更多的数据或更好的算法来提高学习算法的结果。对于某些应用而言,深度学习在大数据集上的表现比其他机器学习(ML)方法都要好。
性能表现方面,与其他工具相比,深度学习算法更适合无监督和半监督学习,更适合强特征提取,也更适合于图像识别领域、文本识别领域、语音识别领域等。
它不以任何损失函数为特征,也不会被特定公式所限制,这使得该框架模型能以比其他传统机器学习工具更好的方式进行使用和扩展。
(2)神经网络模型基本组成
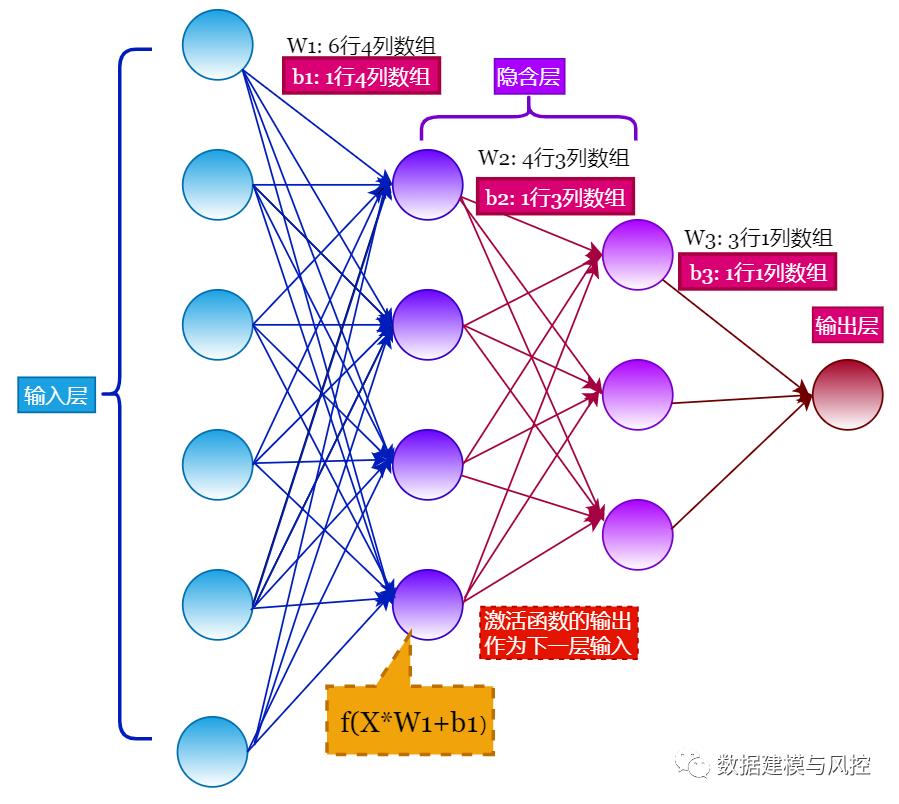
一般地,神经网络模型包括输入层(input layer)、隐含层(hidden layers)、输出层(output layer)。
如上图所示,数据传输是从输入层 -> 隐含层 -> 输出层,这种网络叫做前向传播神经网络(feedforward neural networks),在这种网络中没有环,数据传播总是前向的,从不反向,也就是说输入层会通过隐含层 1、隐含层 2……,间接地影响到输出层。
上面示意图中的输入层有 6 个神经元节点组成,第一个隐含层由 4 个神经元节点组成,第二个隐含层由 3 个神经元节点组成,输出层由 1 个神经元节点组成。
(3)权重参数
每一层中每个神经元节点都指向下一层的每个神经元节点。
如下图,输入层的第一个神经元节点指向第一个隐含层中所有节点,每一条连接线形成一个权重参数 $W$,这就是待学习的参数。
输入层共有 6 个节点,第一个隐含层 4 个节点,形成的权重参数形状为 $(6,4)$ 的数组。第一个隐含层与第二个隐含层形成的权重参数形状为 $(4,3)$ 。第二个隐含层与输出层形成的权重参数形状为 $(3,1)$。
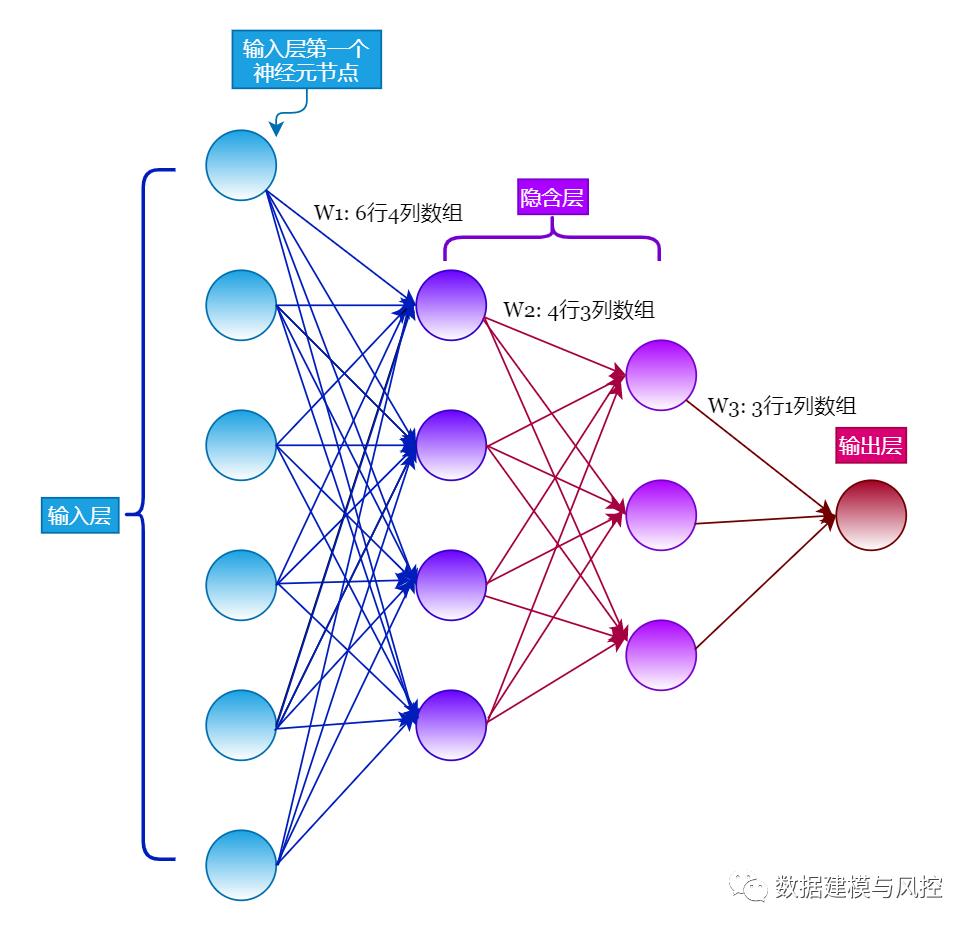
提示:当输出层只有一个神经元节点时,意味着只输出一个值。这个值可以看做是回归问题的一个取值,二分类问题如泰坦尼克乘客获救的可能性等。
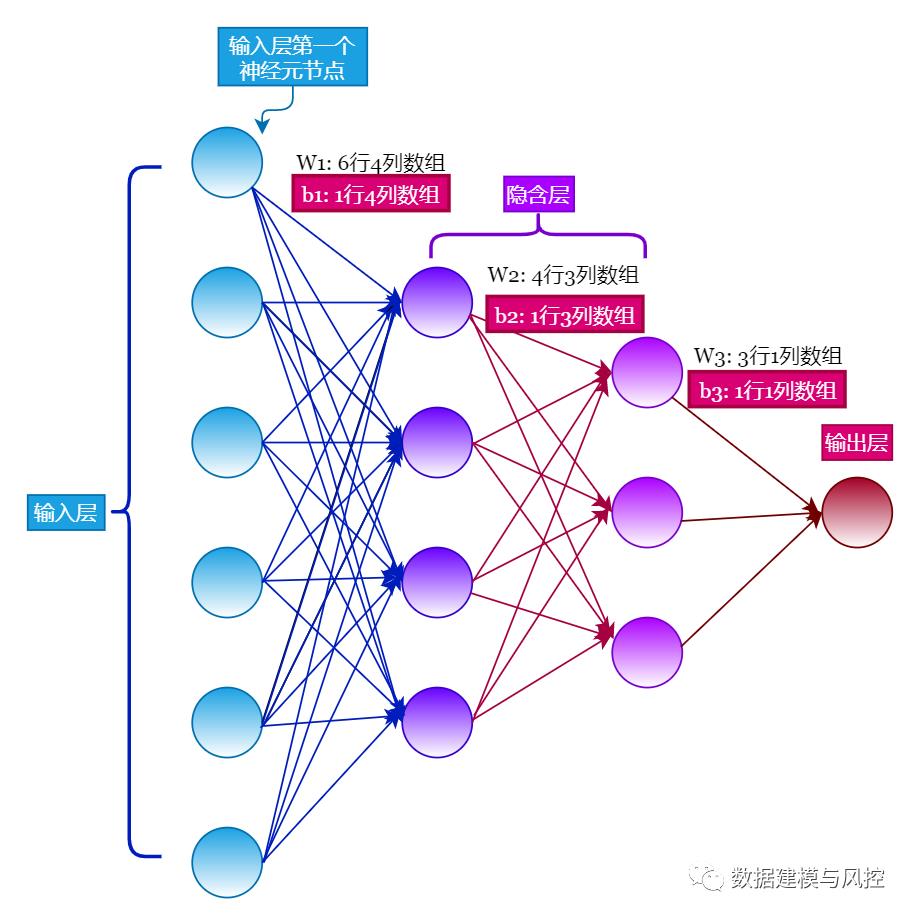
除了层间的权重参数 $W$ 外,每层间的神经元节点还有附加信息需要学习,被称为偏移项 $b$,如下图所示。
二、神经网络的优缺点
神经网络优点:
分类的准确度高
并行分布处理能力强,分布存储及学习能力强
可以用在监督领域(分类、预测)与非监督领域(特征衍生)
神经网络缺点:
神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值
不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度
学习时间过长,甚至达不到学习目的
三、神经网络的正向传播
如果对输入层与第一个隐含层间的参数 $W$ 做一个微小的调整,改变大小为 $Delta W$,这个改变就会层层传播,直到输出层传播结束,如下图所示,这种微从输入层传播到输出层的微小改变的传播调整称为正向传播。
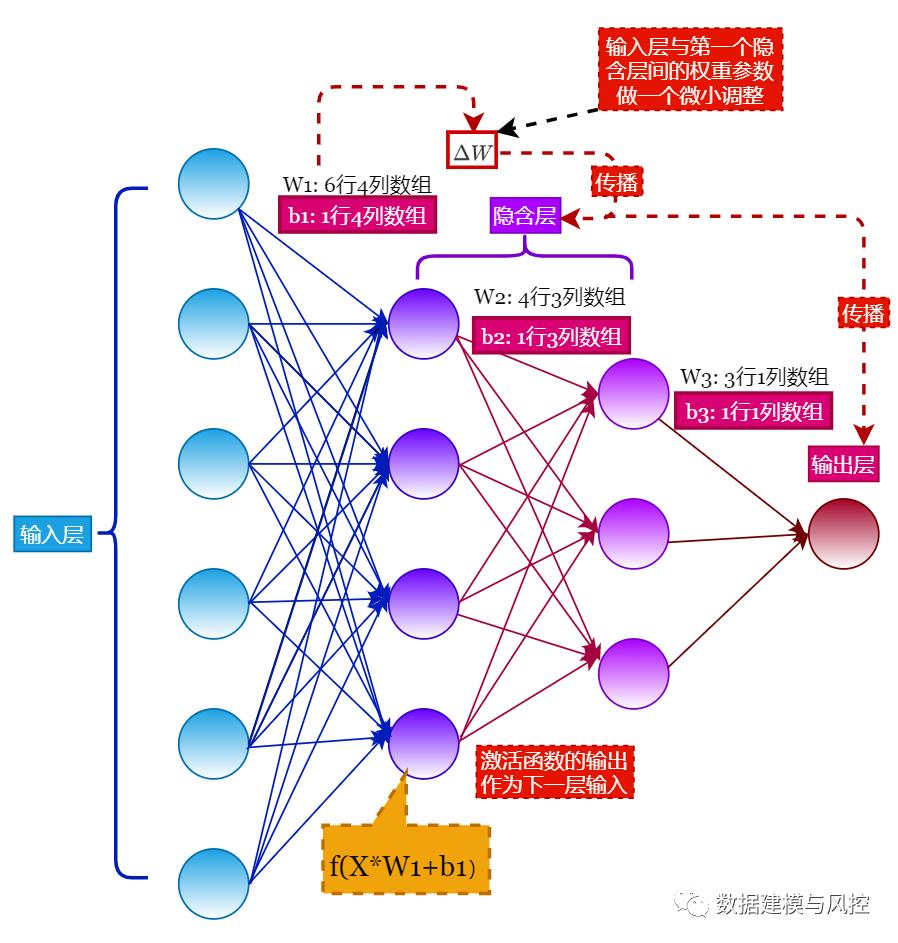
对于有监督学习任务,神经网络的输出层与实际标签值的差值被称为损失函数,这与传统机器学习模型的损失函数理解起来是一样的。
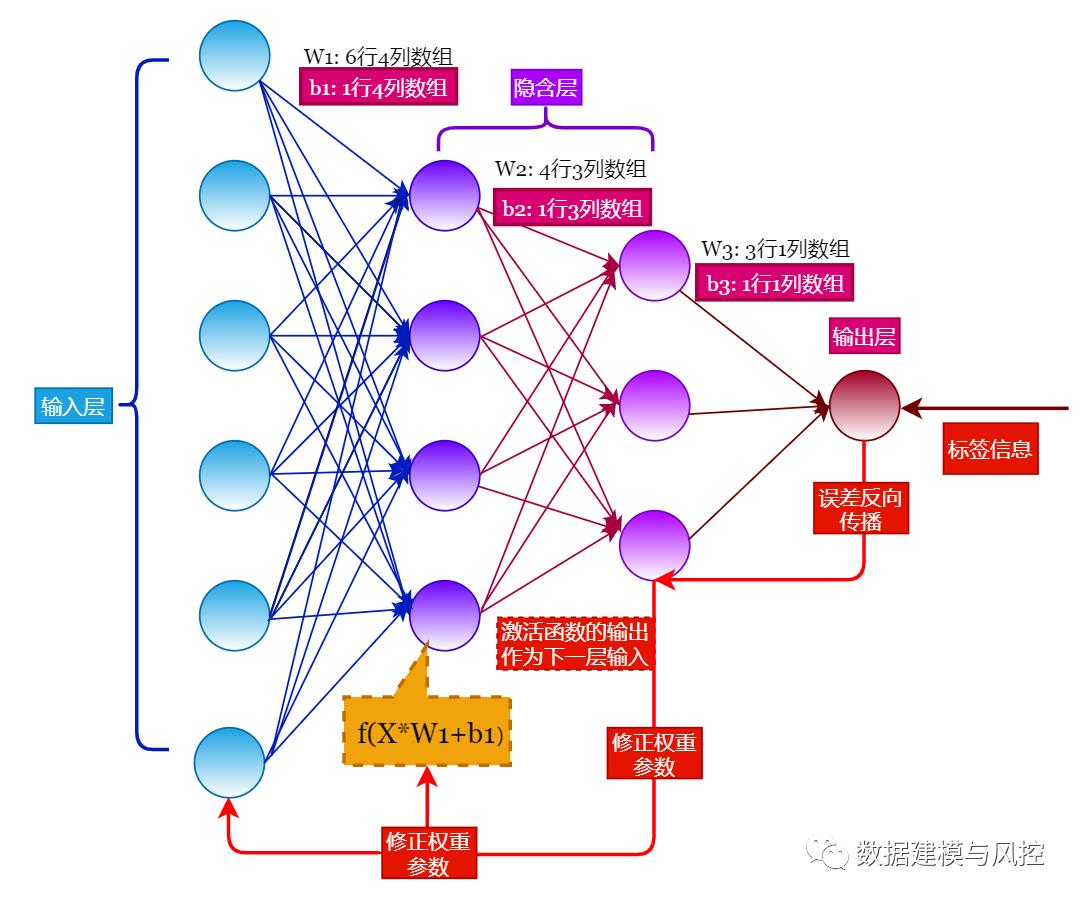
四、神经网络的反向传播
前面介绍参数的正向传播,下面介绍反向传播。反向传播是用来最小化损失函数的一项重要机制,通过反向传播算法,有策略地调整权重参数和偏移项,反复迭代,直到损失函数值达到最小。
五、激活函数
输入层 $X$ 与权重参数 $W_1$ 和偏移项 $b_1$ 运算 $X imes W_1 + b_1$ 后,会经过一个函数 $f$ 处理,这个函数被称为激活函数,它的作用实现非线性,实现拟合任意函数曲线。
如上图,激活函数的输出项会作为下一层的输入。
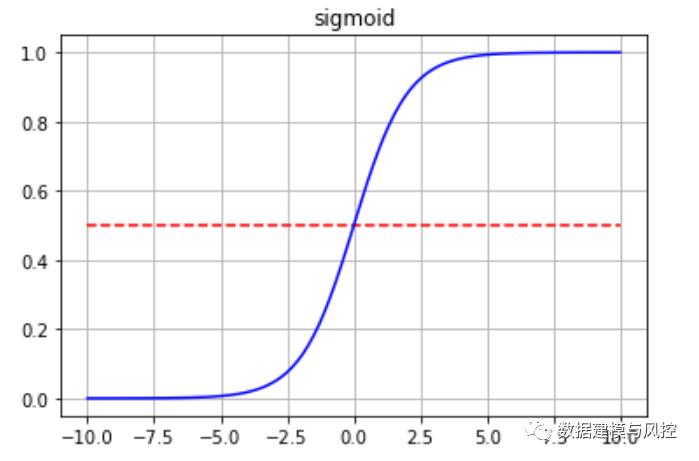
列举目前常用的三种激活函数:Sigmoid 函数、ReLU 函数、Softmax 函数。
下面分别绘制:
import tensorflow as tf # TensorFlow 版本 '2.1.0'
import numpy as np
import matplotlib.pyplot as plt
h = np.linspace(-10,10,100)# Sigmoid 激活函数
y = tf.sigmoid(h)
plt.title('sigmoid')
plt.grid()
plt.plot(h,y,c='blue')
plt.hlines(0.5, -10, 10, colors='red', linestyle='--' ,label='0.5')
plt.show()
绘制 ReLU 激活函数:
h = np.linspace(-10,10,100)
y = tf.nn.relu(h)
plt.title('relu')
plt.grid()
plt.plot(h,y,c='blue')
plt.show()
绘制 Softmax 激活函数:
h = np.linspace(-5,5,100)
y = tf.nn.softmax(h)
plt.title('softmax')
plt.grid()
plt.plot(h,y,c='blue')
plt.show()
六、具体实施步骤
(1)数据处理
Step 1: 特征工程
方法与采用分箱法方法一样,主要采取 特征衍生 方法。
Step 2: 归一化处理
u 对类别型变量:
(one-hot)处理
u 对数值型变量:
归一化(standardized)处理
Step 3: 极端值处理
对极端值进行处理
--以(75%-25%)为一个单位。
判断数值是否超过75%分位点 + 1.5个单位,或者低于25%分位点 -1.5个单位
如果超过则需要进行截断处理。
(2)神经网络参数调优
调优的依据是AUC最大化。
假设有3层隐藏层的情况下,对隐藏层的节点数进行调优。
对best_dropout_prob 连接概率,即每一个隐藏层和每一个隐藏节点,能够被连接或者选举出来的概率,进行调优。
七、输出结果
auc_score = 0.57
八、代码实现
import pandas as pdimport datetimeimport collectionsimport numpy as npimport numbersimport randomimport sysimport pickleimport tensorflow as tffrom tensorflow.contrib.learn.python.learn.estimators import SKCompatfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_scorefrom importlib import reloadfrom matplotlib import pyplot as pltimport operatorreload(sys)#sys.setdefaultencoding( "utf-8")# -*- coding: utf-8 -*-### 对时间窗口,计算累计产比 ###def TimeWindowSelection(df, daysCol, time_windows):''':param df: the dataset containg variabel of days:param daysCol: the column of days:param time_windows: the list of time window:return:'''freq_tw = {}for tw in time_windows:freq = sum(df[daysCol].apply(lambda x: int(x<=tw)))freq_tw[tw] = freqreturn freq_twdef DeivdedByZero(nominator, denominator):'''当分母为0时,返回0;否则返回正常值'''if denominator == 0:return 0else:return nominator*1.0/denominator#对某些统一的字段进行统一def ChangeContent(x):y = x.upper()if y == '_MOBILEPHONE':y = '_PHONE'return ydef MissingCategorial(df,x):missing_vals = df[x].map(lambda x: int(x!=x))return sum(missing_vals)*1.0/df.shape[0]def MissingContinuous(df,x):missing_vals = df[x].map(lambda x: int(np.isnan(x)))return sum(missing_vals) * 1.0 / df.shape[0]def MakeupRandom(x, sampledList):if x==x:return xelse:randIndex = random.randint(0, len(sampledList)-1)return sampledList[randIndex]def Outlier_Dectection(df,x):''':param df::param x::return:'''p25, p75 = np.percentile(df[x], 25),np.percentile(df[x], 75)d = p75 - p25upper, lower = p75 + 1.5*d, p25-1.5*dtruncation = df[x].map(lambda x: max(min(upper, x), lower))return truncation#############################################################Step 0: 数据分析的初始工作, 包括读取数据文件、检查用户Id的一致性等############################################################## folderOfData = '/Users/LiuSiyue/Code/Data Collections/bank default/'folderOfData = 'F:/chen/download/creditcard/Chimerge/cyc/ann/'data1 = pd.read_csv(folderOfData+'PPD_LogInfo_3_1_Training_Set.csv', header = 0)data2 = pd.read_csv(folderOfData+'PPD_Training_Master_GBK_3_1_Training_Set.csv', header = 0,encoding = 'gbk')data3 = pd.read_csv(folderOfData+'PPD_Userupdate_Info_3_1_Training_Set.csv', header = 0)#将数据集分为训练集与测试集all_ids = data2['Idx']train_ids, test_ids = train_test_split(all_ids, test_size=0.3)train_ids = pd.DataFrame(train_ids)test_ids = pd.DataFrame(test_ids)data1_train = pd.merge(left=train_ids,right = data1, on='Idx', how='inner')data2_train = pd.merge(left=train_ids,right = data2, on='Idx', how='inner')data3_train = pd.merge(left=train_ids,right = data3, on='Idx', how='inner')data1_test = pd.merge(left=test_ids,right = data1, on='Idx', how='inner')data2_test = pd.merge(left=test_ids,right = data2, on='Idx', how='inner')data3_test = pd.merge(left=test_ids,right = data3, on='Idx', how='inner')############################################################################################## Step 1: 从PPD_LogInfo_3_1_Training_Set & PPD_Userupdate_Info_3_1_Training_Set数据中衍生特征############################################################################################### compare whether the four city variables matchdata2_train['city_match'] = data2_train.apply(lambda x: int(x.UserInfo_2 == x.UserInfo_4 == x.UserInfo_8 == x.UserInfo_20),axis = 1)del data2_train['UserInfo_2']del data2_train['UserInfo_4']del data2_train['UserInfo_8']del data2_train['UserInfo_20']### 提取申请日期,计算日期差,查看日期差的分布data1_train['logInfo'] = data1_train['LogInfo3'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))data1_train['Listinginfo'] = data1_train['Listinginfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))data1_train['ListingGap'] = data1_train[['logInfo','Listinginfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)### 提取申请日期,计算日期差,查看日期差的分布'''使用180天作为最大的时间窗口计算新特征所有可以使用的时间窗口可以有7 days, 30 days, 60 days, 90 days, 120 days, 150 days and 180 days.在每个时间窗口内,计算总的登录次数,不同的登录方式,以及每种登录方式的平均次数'''time_window = [7, 30, 60, 90, 120, 150, 180]var_list = ['LogInfo1','LogInfo2']data1GroupbyIdx = pd.DataFrame({'Idx':data1_train['Idx'].drop_duplicates()})for tw in time_window:data1_train['TruncatedLogInfo'] = data1_train['Listinginfo'].map(lambda x: x + datetime.timedelta(-tw))temp = data1_train.loc[data1_train['logInfo'] >= data1_train['TruncatedLogInfo']]for var in var_list:#count the frequences of LogInfo1 and LogInfo2count_stats = temp.groupby(['Idx'])[var].count().to_dict()data1GroupbyIdx[str(var)+'_'+str(tw)+'_count'] = data1GroupbyIdx['Idx'].map(lambda x: count_stats.get(x,0))# count the distinct value of LogInfo1 and LogInfo2Idx_UserupdateInfo1 = temp[['Idx', var]].drop_duplicates()uniq_stats = Idx_UserupdateInfo1.groupby(['Idx'])[var].count().to_dict()data1GroupbyIdx[str(var) + '_' + str(tw) + '_unique'] = data1GroupbyIdx['Idx'].map(lambda x: uniq_stats.get(x,0))# calculate the average count of each value in LogInfo1 and LogInfo2data1GroupbyIdx[str(var) + '_' + str(tw) + '_avg_count'] = data1GroupbyIdx[[str(var)+'_'+str(tw)+'_count',str(var) + '_' + str(tw) + '_unique']].apply(lambda x: DeivdedByZero(x[0],x[1]), axis=1)data3_train['ListingInfo'] = data3_train['ListingInfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))data3_train['UserupdateInfo'] = data3_train['UserupdateInfo2'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))data3_train['ListingGap'] = data3_train[['UserupdateInfo','ListingInfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)collections.Counter(data3_train['ListingGap'])hist_ListingGap = np.histogram(data3_train['ListingGap'])hist_ListingGap = pd.DataFrame({'Freq':hist_ListingGap[0],'gap':hist_ListingGap[1][1:]})hist_ListingGap['CumFreq'] = hist_ListingGap['Freq'].cumsum()hist_ListingGap['CumPercent'] = hist_ListingGap['CumFreq'].map(lambda x: x*1.0/hist_ListingGap.iloc[-1]['CumFreq'])'''对 QQ和qQ, Idnumber和idNumber,MOBILEPHONE和PHONE 进行统一在时间切片内,计算(1) 更新的频率(2) 每种更新对象的种类个数(3) 对重要信息如IDNUMBER,HASBUYCAR, MARRIAGESTATUSID, PHONE的更新'''data3_train['UserupdateInfo1'] = data3_train['UserupdateInfo1'].map(ChangeContent)data3GroupbyIdx = pd.DataFrame({'Idx':data3_train['Idx'].drop_duplicates()})time_window = [7, 30, 60, 90, 120, 150, 180]for tw in time_window:data3_train['TruncatedLogInfo'] = data3_train['ListingInfo'].map(lambda x: x + datetime.timedelta(-tw))temp = data3_train.loc[data3_train['UserupdateInfo'] >= data3_train['TruncatedLogInfo']]#frequency of updatingfreq_stats = temp.groupby(['Idx'])['UserupdateInfo1'].count().to_dict()data3GroupbyIdx['UserupdateInfo_'+str(tw)+'_freq'] = data3GroupbyIdx['Idx'].map(lambda x: freq_stats.get(x,0))# number of updated typesIdx_UserupdateInfo1 = temp[['Idx','UserupdateInfo1']].drop_duplicates()uniq_stats = Idx_UserupdateInfo1.groupby(['Idx'])['UserupdateInfo1'].count().to_dict()data3GroupbyIdx['UserupdateInfo_' + str(tw) + '_unique'] = data3GroupbyIdx['Idx'].map(lambda x: uniq_stats.get(x, x))#average count of each typedata3GroupbyIdx['UserupdateInfo_' + str(tw) + '_avg_count'] = data3GroupbyIdx[['UserupdateInfo_'+str(tw)+'_freq', 'UserupdateInfo_' + str(tw) + '_unique']].apply(lambda x: x[0] * 1.0 / x[1], axis=1)#whether the applicant changed items like IDNUMBER,HASBUYCAR, MARRIAGESTATUSID, PHONEIdx_UserupdateInfo1['UserupdateInfo1'] = Idx_UserupdateInfo1['UserupdateInfo1'].map(lambda x: [x])Idx_UserupdateInfo1_V2 = Idx_UserupdateInfo1.groupby(['Idx'])['UserupdateInfo1'].sum()for item in ['_IDNUMBER','_HASBUYCAR','_MARRIAGESTATUSID','_PHONE']:item_dict = Idx_UserupdateInfo1_V2.map(lambda x: int(item in x)).to_dict()data3GroupbyIdx['UserupdateInfo_' + str(tw) + str(item)] = data3GroupbyIdx['Idx'].map(lambda x: item_dict.get(x, x))# Combine the above features with raw features in PPD_Training_Master_GBK_3_1_Training_SetallData = pd.concat([data2_train.set_index('Idx'), data3GroupbyIdx.set_index('Idx'), data1GroupbyIdx.set_index('Idx')],axis= 1)allData.to_csv(folderOfData+'allData_0.csv',encoding = 'gbk')######################################### Step 2: 对类别型变量和数值型变量进行预处理#########################################allData = pd.read_csv(folderOfData+'allData_0.csv',header = 0,encoding = 'gbk')allFeatures = list(allData.columns)allFeatures.remove('target')if 'Idx' in allFeatures:allFeatures.remove('Idx')allFeatures.remove('ListingInfo')#检查是否有常数型变量,并且检查是类别型还是数值型变量numerical_var = []for col in allFeatures:if len(set(allData[col])) == 1:print('delete {} from the dataset because it is a constant'.format(col))del allData[col]allFeatures.remove(col)else:uniq_valid_vals = [i for i in allData[col] if i == i]uniq_valid_vals = list(set(uniq_valid_vals))if len(uniq_valid_vals) >= 10 and isinstance(uniq_valid_vals[0], numbers.Real):numerical_var.append(col)categorical_var = [i for i in allFeatures if i not in numerical_var]#检查变量的最多值的占比情况,以及每个变量中占比最大的值records_count = allData.shape[0]col_most_values,col_large_value = {},{}for col in allFeatures:value_count = allData[col].groupby(allData[col]).count()col_most_values[col] = max(value_count)/records_countlarge_value = value_count[value_count== max(value_count)].index[0]col_large_value[col] = large_valuecol_most_values_df = pd.DataFrame.from_dict(col_most_values, orient = 'index')col_most_values_df.columns = ['max percent']col_most_values_df = col_most_values_df.sort_values(by = 'max percent', ascending = False)pcnt = list(col_most_values_df[:500]['max percent'])vars = list(col_most_values_df[:500].index)plt.bar(range(len(pcnt)), height = pcnt)plt.title('Largest Percentage of Single Value in Each Variable')#计算多数值占比超过90%的字段中,少数值的坏样本率是否会显著高于多数值large_percent_cols = list(col_most_values_df[col_most_values_df['max percent']>=0.9].index)bad_rate_diff = {}for col in large_percent_cols:large_value = col_large_value[col]temp = allData[[col,'target']]temp[col] = temp.apply(lambda x: int(x[col]==large_value),axis=1)bad_rate = temp.groupby(col).mean()if bad_rate.iloc[0]['target'] == 0:bad_rate_diff[col] = 0continuebad_rate_diff[col] = np.log(bad_rate.iloc[0]['target']/bad_rate.iloc[1]['target'])bad_rate_diff_sorted = sorted(bad_rate_diff.items(),key=lambda x: x[1], reverse=True)bad_rate_diff_sorted_values = [x[1] for x in bad_rate_diff_sorted]plt.bar(x = range(len(bad_rate_diff_sorted_values)), height = bad_rate_diff_sorted_values)#由于所有的少数值的坏样本率并没有显著高于多数值,意味着这些变量可以直接剔除for col in large_percent_cols:if col in numerical_var:numerical_var.remove(col)else:categorical_var.remove(col)del allData[col]'''对类别型变量,如果缺失超过80%, 就删除,否则保留。'''missing_pcnt_threshould_1 = 0.8for col in categorical_var:missingRate = MissingCategorial(allData,col)print('{0} has missing rate as {1}'.format(col,missingRate))if missingRate > missing_pcnt_threshould_1:categorical_var.remove(col)del allData[col]allData_bk = allData.copy()'''用one-hot对类别型变量进行编码'''dummy_map = {}dummy_columns = []for raw_col in categorical_var:dummies = pd.get_dummies(allData.loc[:, raw_col], prefix=raw_col)col_onehot = pd.concat([allData[raw_col], dummies], axis=1)col_onehot = col_onehot.drop_duplicates()allData = pd.concat([allData, dummies], axis=1)del allData[raw_col]dummy_map[raw_col] = col_onehotdummy_columns = dummy_columns + list(dummies)with open(folderOfData+'dummy_map.pkl',"wb") as f:f.write(pickle.dumps(dummy_map))with open(folderOfData+'dummy_columns.pkl',"wb") as f:f.write(pickle.dumps(dummy_columns))'''检查数值型变量'''missing_pcnt_threshould_2 = 0.8deleted_var = []for col in numerical_var:missingRate = MissingContinuous(allData, col)print('{0} has missing rate as {1}'.format(col, missingRate))if missingRate > missing_pcnt_threshould_2:deleted_var.append(col)print('we delete variable {} because of its high missing rate'.format(col))else:if missingRate > 0:not_missing = allData.loc[allData[col] == allData[col]][col]#makeuped = allData[col].map(lambda x: MakeupRandom(x, list(not_missing)))missing_position = allData.loc[allData[col] != allData[col]][col].indexnot_missing_sample = random.sample(list(not_missing), len(missing_position))allData.loc[missing_position,col] = not_missing_sample#del allData[col]#allData[col] = makeupedmissingRate2 = MissingContinuous(allData, col)print('missing rate after making up is:{}'.format(str(missingRate2)))if deleted_var != []:for col in deleted_var:numerical_var.remove(col)del allData[col]'''对极端值变量做处理。'''max_min_standardized = {}for col in numerical_var:truncation = Outlier_Dectection(allData, col)upper, lower = max(truncation), min(truncation)d = upper - lowerif d == 0:print("{} is almost a constant".format(col))numerical_var.remove(col)continueallData[col] = truncation.map(lambda x: (upper - x)/d)max_min_standardized[col] = [lower, upper]with open(folderOfData+'max_min_standardized.pkl',"wb") as f:f.write(pickle.dumps(max_min_standardized))allData.to_csv(folderOfData+'allData_1_DNN.csv', header=True,encoding='gbk', columns = allData.columns, index=False)allData = pd.read_csv(folderOfData+'allData_1_DNN.csv', header=0,encoding='gbk')######################################### Step 3: 构建基于TensorFlow的神经网络模型 #########################################allFeatures = list(allData.columns)allFeatures.remove('target')allFeatures.remove('ListingInfo')with open(folderOfData+'allFeatures.pkl',"wb") as f:f.write(pickle.dumps(allFeatures))x_train = np.matrix(allData[allFeatures])# allFeatures = {list} <class 'list'>: ['Idx', 'ListingInfo', 'UserupdateInfo_7_freq', 'UserupdateInfo_7_unique', 'UserupdateInfo_7_avg_count', 'UserupdateInfo_7_IDNUMBER', 'UserupdateInfo_7_HASBUYCAR', 'UserupdateInfo_7_MARRIAGESTATUSID', 'UserupdateInfo_7_PHONE', 'UserupdateInfo_30_freq', 'UserupdateInfo_30_unique', 'UserupdateInfo_30_avg_count', 'UserupdateInfo_30_IDNUMBER', 'UserupdateInfo_30_HASBUYCAR', 'UserupdateInfo_30_MARRIAGESTATUSID', 'UserupdateInfo_30_PHONE', 'UserupdateInfo_60_freq', 'UserupdateInfo_60_unique', 'UserupdateInfo_60_avg_count', 'UserupdateInfo_60_IDNUMBER', 'UserupdateInfo_60_HASBUYCAR', 'UserupdateInfo_60_MARRIAGESTATUSID', 'UserupdateInfo_60_PHONE', 'UserupdateInfo_90_freq', 'UserupdateInfo_90_unique', 'UserupdateInfo_90_avg_count', 'UserupdateInfo_90_IDNUMBER', 'UserupdateInfo_90_HASBUYCAR', 'UserupdateInfo_90_MARRIAGESTATUSID', 'UserupdateInfo_90_PHONE', 'UserupdateInfo_120_freq', 'UserupdateInfo_120_unique', 'UserupdateInfo_120_avg_count', 'UserupdateInfo_120_IDNUMBER', 'UserupdateInfo_120_HASBUYCAR', 'UserupdateInfo_120_MARRIAGESTATUSID', 'UserupdateInfo_120_PHONE', 'UserupdateInfo_150_freq', 'UserupdateInfo_150_unique', 'UserupdateInfo_150_avg_count', 'UserupdateInfo_150_IDNUMBER', 'UserupdateInfo_150_HASBUYCAR', 'UserupdateInfo_150_MARRIAGESTATUSID', 'UserupdateInfo_150_PHONE', 'UserupdateInfo_180_freq', 'UserupdateInfo_180_unique', 'UserupdateInfo_180_avg_count', 'UserupdateInfo_180_IDNUMBER', 'UserupdateInfo_180_HASBUYCAR', 'UserupdateInfo_180_MARRIAGESTATUSID', 'UserupdateInfo_180_PHONE', 'LogInfo1_7_count', 'LogInfo1_7_unique', 'LogInfo1_7_avg_count', 'LogInfo2_7_count', 'LogInfo2_7_unique', 'LogInfo2_7_avg_count', 'LogInfo1_30_count', 'LogInfo1_30_unique', 'LogInfo1_30_avg_count', 'LogInfo2_30_count', 'LogInfo2_30_unique', 'LogInfo2_30_avg_count', 'LogInfo1_60_count', 'LogInfo1_60_unique', 'LogInfo1_60_avg_count', 'LogInfo2_60_count', 'LogInfo2_60_unique', 'LogInfo2_60_avg_count', 'LogInfo1_90_count', 'LogInfo1_90_unique', 'LogInfo1_90_avg_count', 'LogInfo2_90_count', 'LogInfo2_90_unique', 'LogInfo2_90_avg_count', 'LogInfo1_120_count', 'LogInfo1_120_unique', 'LogInfo1_120_avg_count', 'LogInfo2_120_count', 'LogInfo2_120_unique', 'LogInfo2_120_avg_count', 'LogInfo1_150_count', 'LogInfo1_150_unique', 'LogInfo1_150_avg_count', 'LogInfo2_150_count', 'LogInfo2_150_unique', 'LogInfo2_150_avg_count', 'LogInfo1_180_count', 'LogInfo1_180_unique', 'LogInfo1_180_avg_count', 'LogInfo2_180_count', 'LogInfo2_180_unique', 'LogInfo2_180_avg_count']# x_train = np.matrix(allData[['Idx', 'ListingInfo', 'UserupdateInfo_7_freq', 'UserupdateInfo_7_unique', 'UserupdateInfo_7_avg_count', 'UserupdateInfo_7_IDNUMBER', 'UserupdateInfo_7_HASBUYCAR', 'UserupdateInfo_7_MARRIAGESTATUSID', 'UserupdateInfo_7_PHONE']])# x_train = np.matrix(allData[['Idx', 'UserupdateInfo_7_freq', 'UserupdateInfo_7_unique']]) good #bad: 'ListingInfo'# x_train = np.matrix(allData[['Idx', 'UserupdateInfo_7_freq', 'UserupdateInfo_7_unique', 'UserupdateInfo_7_avg_count', 'UserupdateInfo_7_IDNUMBER', 'UserupdateInfo_7_HASBUYCAR', 'UserupdateInfo_7_MARRIAGESTATUSID', 'UserupdateInfo_7_PHONE', 'UserupdateInfo_30_freq', 'UserupdateInfo_30_unique', 'UserupdateInfo_30_avg_count', 'UserupdateInfo_30_IDNUMBER', 'UserupdateInfo_30_HASBUYCAR', 'UserupdateInfo_30_MARRIAGESTATUSID', 'UserupdateInfo_30_PHONE', 'UserupdateInfo_60_freq', 'UserupdateInfo_60_unique', 'UserupdateInfo_60_avg_count', 'UserupdateInfo_60_IDNUMBER', 'UserupdateInfo_60_HASBUYCAR', 'UserupdateInfo_60_MARRIAGESTATUSID', 'UserupdateInfo_60_PHONE', 'UserupdateInfo_90_freq', 'UserupdateInfo_90_unique', 'UserupdateInfo_90_avg_count', 'UserupdateInfo_90_IDNUMBER', 'UserupdateInfo_90_HASBUYCAR', 'UserupdateInfo_90_MARRIAGESTATUSID', 'UserupdateInfo_90_PHONE', 'UserupdateInfo_120_freq', 'UserupdateInfo_120_unique', 'UserupdateInfo_120_avg_count', 'UserupdateInfo_120_IDNUMBER', 'UserupdateInfo_120_HASBUYCAR', 'UserupdateInfo_120_MARRIAGESTATUSID', 'UserupdateInfo_120_PHONE', 'UserupdateInfo_150_freq', 'UserupdateInfo_150_unique', 'UserupdateInfo_150_avg_count', 'UserupdateInfo_150_IDNUMBER', 'UserupdateInfo_150_HASBUYCAR', 'UserupdateInfo_150_MARRIAGESTATUSID', 'UserupdateInfo_150_PHONE', 'UserupdateInfo_180_freq', 'UserupdateInfo_180_unique', 'UserupdateInfo_180_avg_count', 'UserupdateInfo_180_IDNUMBER', 'UserupdateInfo_180_HASBUYCAR', 'UserupdateInfo_180_MARRIAGESTATUSID', 'UserupdateInfo_180_PHONE', 'LogInfo1_7_count', 'LogInfo1_7_unique', 'LogInfo1_7_avg_count', 'LogInfo2_7_count', 'LogInfo2_7_unique', 'LogInfo2_7_avg_count', 'LogInfo1_30_count', 'LogInfo1_30_unique', 'LogInfo1_30_avg_count', 'LogInfo2_30_count', 'LogInfo2_30_unique', 'LogInfo2_30_avg_count', 'LogInfo1_60_count', 'LogInfo1_60_unique', 'LogInfo1_60_avg_count', 'LogInfo2_60_count', 'LogInfo2_60_unique', 'LogInfo2_60_avg_count', 'LogInfo1_90_count', 'LogInfo1_90_unique', 'LogInfo1_90_avg_count', 'LogInfo2_90_count', 'LogInfo2_90_unique', 'LogInfo2_90_avg_count', 'LogInfo1_120_count', 'LogInfo1_120_unique', 'LogInfo1_120_avg_count', 'LogInfo2_120_count', 'LogInfo2_120_unique', 'LogInfo2_120_avg_count', 'LogInfo1_150_count', 'LogInfo1_150_unique', 'LogInfo1_150_avg_count', 'LogInfo2_150_count', 'LogInfo2_150_unique', 'LogInfo2_150_avg_count', 'LogInfo1_180_count', 'LogInfo1_180_unique', 'LogInfo1_180_avg_count', 'LogInfo2_180_count', 'LogInfo2_180_unique', 'LogInfo2_180_avg_count']])y_train = np.matrix(allData['target']).T#进一步将训练集拆分成训练集和验证集。在新训练集上进行参数估计,在验证集上决定最优的参数x_train, x_validation, y_train, y_validation = train_test_split(x_train, y_train,test_size=0.4,random_state=9)#Example: select the best number of units in the 1-layer hidden layerno_hidden_units_selection = {}feature_columns = [tf.contrib.layers.real_valued_column("", dimension = x_train.shape[1])]for no_hidden_units in range(50,101,10):print("the current choise of hidden units number is {}".format(no_hidden_units))# 节点数是前面节点数 - 10。共有3层的隐藏层clf0 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,hidden_units=[no_hidden_units, no_hidden_units-10,no_hidden_units-20],n_classes=2,dropout = 0.5)clf = SKCompat(clf0)clf.fit(x_train, y_train, batch_size=256,steps = 100000)#monitor the performance of the model using AUC score# 调优的依据是使AUC最大化clf_pred_proba = clf._estimator.predict_proba(x_validation)pred_proba = [i[1] for i in clf_pred_proba]auc_score = roc_auc_score(y_validation.getA(),pred_proba)no_hidden_units_selection[no_hidden_units] = auc_scorebest_hidden_units = max(no_hidden_units_selection.items(), key=operator.itemgetter(1))[0] #80print("best_hidden_units = ", best_hidden_units )#Example: check the dropout effectdropout_selection = {}feature_columns = [tf.contrib.layers.real_valued_column("", dimension = x_train.shape[1])]print("np.linspace(0,0.99,20) = ",np.linspace(0,0.99,20))cyc_i = 0 # 连接概率调优for dropout_prob in np.linspace(0,0.99,20):cyc_i = cyc_i+1print("cyc_i = ", cyc_i)print("dropout_prob = ", dropout_prob)print("the current choise of drop out rate is {}".format(dropout_prob))clf0 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,hidden_units = [best_hidden_units, best_hidden_units-10,best_hidden_units-20],n_classes=2,dropout = dropout_prob)clf = SKCompat(clf0)clf.fit(x_train, y_train, batch_size=256,steps = 100000)#monitor the performance of the model using AUC scoreclf_pred_proba = clf._estimator.predict_proba(x_validation)pred_proba = [i[1] for i in clf_pred_proba]auc_score = roc_auc_score(y_validation.getA(),pred_proba)dropout_selection[dropout_prob] = auc_scorebest_dropout_prob = max(dropout_selection.items(), key=operator.itemgetter(1))[0] #0.0print("best_dropout_prob = " , best_dropout_prob )#the best model isclf1 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,hidden_units = [best_hidden_units, best_hidden_units-10,best_hidden_units-20],n_classes=2,dropout = best_dropout_prob)print("begin to action1")clf1.fit(x_train, y_train, batch_size=256,steps = 100000)# clf1.fit(x_train, y_train)print("begin to action2")clf_pred_proba = clf1.predict_proba(x_train)print("begin to action3")pred_proba = [i[1] for i in clf_pred_proba]auc_score = roc_auc_score(y_train.getA(),pred_proba) #0.569print("auc_score = ", auc_score)
以上是关于神经网络模型在违约预测中的应用的主要内容,如果未能解决你的问题,请参考以下文章