技术篇 | 基于神经网络模型的网页信息智能抽取
Posted 携宁技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术篇 | 基于神经网络模型的网页信息智能抽取相关的知识,希望对你有一定的参考价值。
背 景
网页信息抽取技术近年来发展迅速,常见的网页抽取方法为基于正则或CSS选择器或xpath的网页抽取,这些都属于基于包装器(wrapper)的网页抽取,这类抽取算法的通病就在于:对于不同结构的网页,要制定不同的抽取规则。对于需要监控大量异构网站的系统,便需要编写并维护相应数量套抽取规则,效率低、成本高。
携宁的网页信息智能抽取是一种基于神经网络模型的机器学习方法,让程序在不需要人工制定规则的情况下从网页中提取所需的信息,并且只需要少量的数据,便能够在保证识别准确率的基础上具有极高的识别速度。
本文将致力于分享我们是如何基于神经网络模型实现对网页信息的智能抽取,并在保证准确率的基础上显著减少整个方案所需的数据量,从而提高模型的识别收敛速度及鲁棒性等多方面的性能。
基于神经网络模型的网页信息
智能抽取
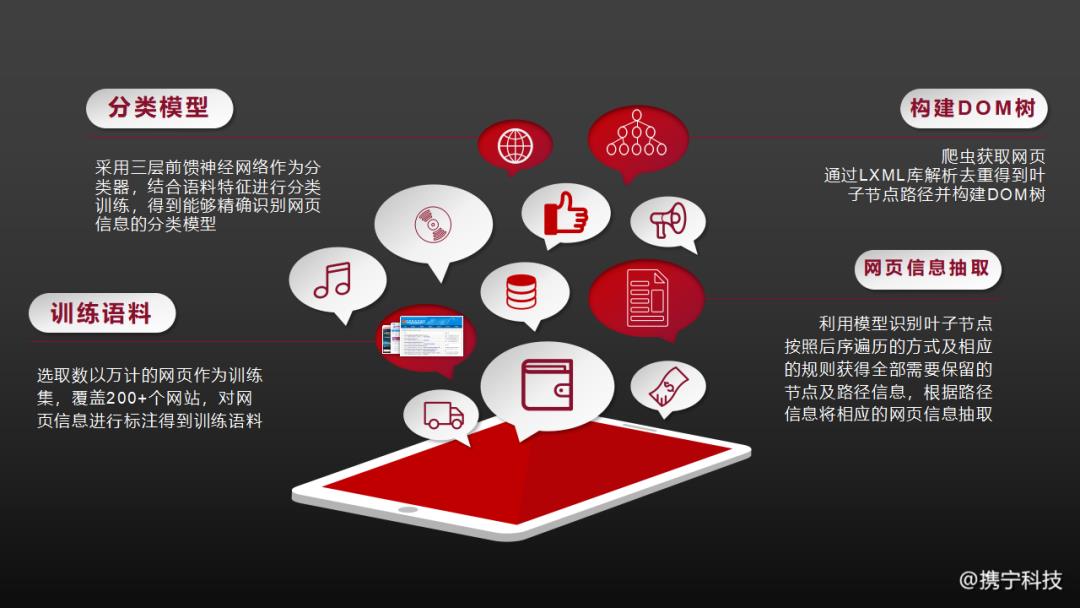
携宁的基于神经网络模型的网页信息智能抽取是一种基于分类器的网页抽取算法,选取数以千计的网页作为训练集,覆盖了200+个网站,对网页信息进行标注得到训练语料;模型采用词嵌入模型作为输入层,采用三层前馈神经网络作为分类器,并结合语料特征来进行分类训练,得到能够精确识别网页信息的神经网络模型。
在进行网页信息智能抽取时,通过LXML库对爬虫获取到的网页进行解析去重得到叶子节点路径并构建DOM树,再利用神经网络模型识别得到需要保留的叶子节点,并按照后序遍历的方式及相应的规则获得全部需要保留的节点及路径信息,最后根据路径信息将相应的网页信息抽取。
在基于神经网络模型实现网页信息智能抽取的整个过程中,由于只需要对叶子节点进行识别判断,模型各方面所需的数据量都显著降低,从而模型各方面的属性都得到极大增幅。
三大核心技术:
接下来介绍基于神经网络模型的网页信息智能抽取中的三大核心技术:DOM树构建、词嵌入模型、前馈神经网络分类器。
1
●
DOM树构建
网页是包含html标签的纯文本文件,网页内容的布局被称为网页结构,对网页的内容进行规划就是在创建网页结构。网页的组成元素包括标题、正文、来源、时间、广告、噪音、推荐、图片、链接、超链接等,网页信息抽取的目的就是从海量网页类文本中抽取特定区域的特定信息。为了方便获得网页信息的Xpath路径,将每一个网页转化成一颗DOM树,DOM树是以层次结构组织的节点或信息片段的集合。
通过爬虫获取网页的HTML源码,再利用Beautiful Soup库得到网页的全部叶子节点路径,利用LXML库获取到每个叶子节点包含的信息,包括节点标签、节点属性、节点文本,从而构建具有叶子节点信息的DOM树。
2
●
词嵌入模型
本文中的词嵌入模型为Tag Embedding和Class Embedding,用于将HTML编码的标签和属性进行数值化表示。词嵌入模型是word嵌入式自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。
词嵌入模型一般分为以下方式:
①One-hot:用一个词典D的大小长度的向量来表示一个词,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引,但是这种词嵌入模型表示有个显著缺点:维度很大,容易造成维度灾难,词与词的相关性无法度量。
②分布式词嵌入模型:通过训练将某种语言中的每一个词映射成一个固定长度的向量,所有这些向量构成一个词嵌入模型空间,而每一向量则可视为该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的相似性。
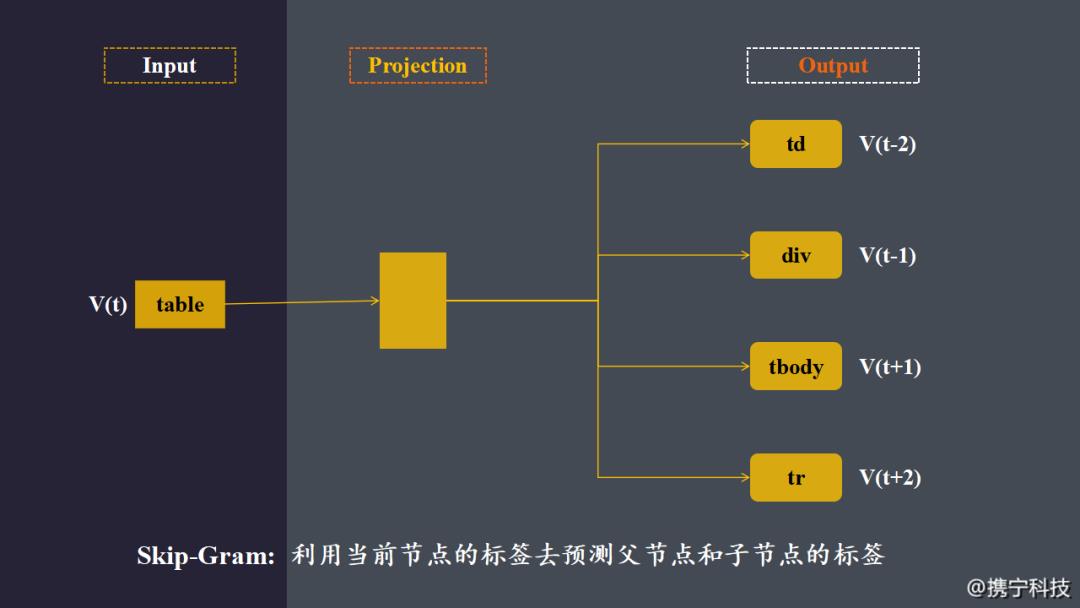
网页信息智能抽取中的Tag Embedding和Class Embedding借鉴了word2vec中的Skip-Gram,利用当前节点的Tag去预测父节点和子节点的Tag,word2vec采用的是分布式词嵌入模型。输入当前词的One-hot Embedding,经过一层不带激活函数的隐藏层,通过Softmax激活函数输出,损失函数为:(其中vj...vk分别为vn的父节点和子节点)
携宁采用了Gensim库来训练词嵌入模型,通过Hierarchical Softmax和负采样来提高训练的速度,训练得到Tag Embedding和Class Embedding。
3
●
前馈神经网络分类器
前馈神经网络是人工智能领域中最早发明的简单人工神经网络类型,各神经元分层排列,每个神经元只与前一层的神经元相连。前馈神经网络的内部参数从输入层经过隐含层单向传播,各层之间没有反馈。
携宁采用三层前馈神经网络作为分类器,输入层为Embdding层,包括父节点的Tag Embedding以及Class Embedding,叶子节点的Tag Embedding、Class Embedding和文本长度,再经过两层激活函数为Relu的隐藏层,输出层采用激活函数为Sigmoid。
携宁采用的三层前馈神经网络分类器模型结构简单,在保证训练获得的神经网络识别模型准确率的基础上,有效避免了网络过于复杂造成的过拟合现象,从而提升了神经网络识别模型的鲁棒性;并通过采用S型函数对神经网络训练模型中的输出层进行激活,从而有效降低了训练过程中的计算难度和复杂度。
特点:
收敛速度快:在CPU训练的情况下共60个Epoch,Loss值为0.03,用时20分钟;
泛化能力强:可以实现多种网页信息的特定识别抽取,包括标题、正文、来源、时间、广告、噪音等;测试100+网站,准确率高达95%;
准确率高:本模型语料来自200多个网站,包括新闻,公告,资讯等;人工标注量1w+条,分类器便经能达到很好的准确率,训练准确率达96%,且训练时间短。
模型轻量:由于模型训练所需数据仅包括叶子节点相关信息,删减了部分无关信息,数据量相比而言显著降低;
识别速度快:由于模型轻量,进行模型识别时只需获取叶子节点相关信息,无需对所有节点进行识别,识别速度显著提高。
总 结
本文介绍了基于神经网络模型的网页信息智能抽取,提供了一种全新的网页信息抽取方案,采用了将词嵌入模型和前馈神经网络分类器组合的方式构建得到网页信息智能抽取的神经网络模型,在保证网页信息智能抽取准确的基础上大幅度减少模型训练及模型识别过程中所需的数据量,使得模型各方面的性能均得到显著提升,利于海量数据情形下的对网页信息的快速智能识别抽取。
以上是关于技术篇 | 基于神经网络模型的网页信息智能抽取的主要内容,如果未能解决你的问题,请参考以下文章