基于 k8s 的 Jenkins 构建集群实践
Posted DevOps时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 k8s 的 Jenkins 构建集群实践相关的知识,希望对你有一定的参考价值。

本文整理自 Jenkins 北京线下沙龙演讲
在大型团队的 CI 构建里具有丰富最佳实践的经验。今天我给大家分享的更多是聚焦在 Jenkins 本身,结合我在 Jenkins 实际使用过程中和整个 Jenkins Slave 管理演化的过程的案例,这样能给大家带来更好的借鉴和参考体验。
下面是主要要分享的四大内容:
Jenkins分布式构建架构
基于Lable的Slave集群管理
基于Docker插件的容器化实践
基于Kubernetes的容器化实践
一. Jenkins分布式构建架构
1.1 架构图
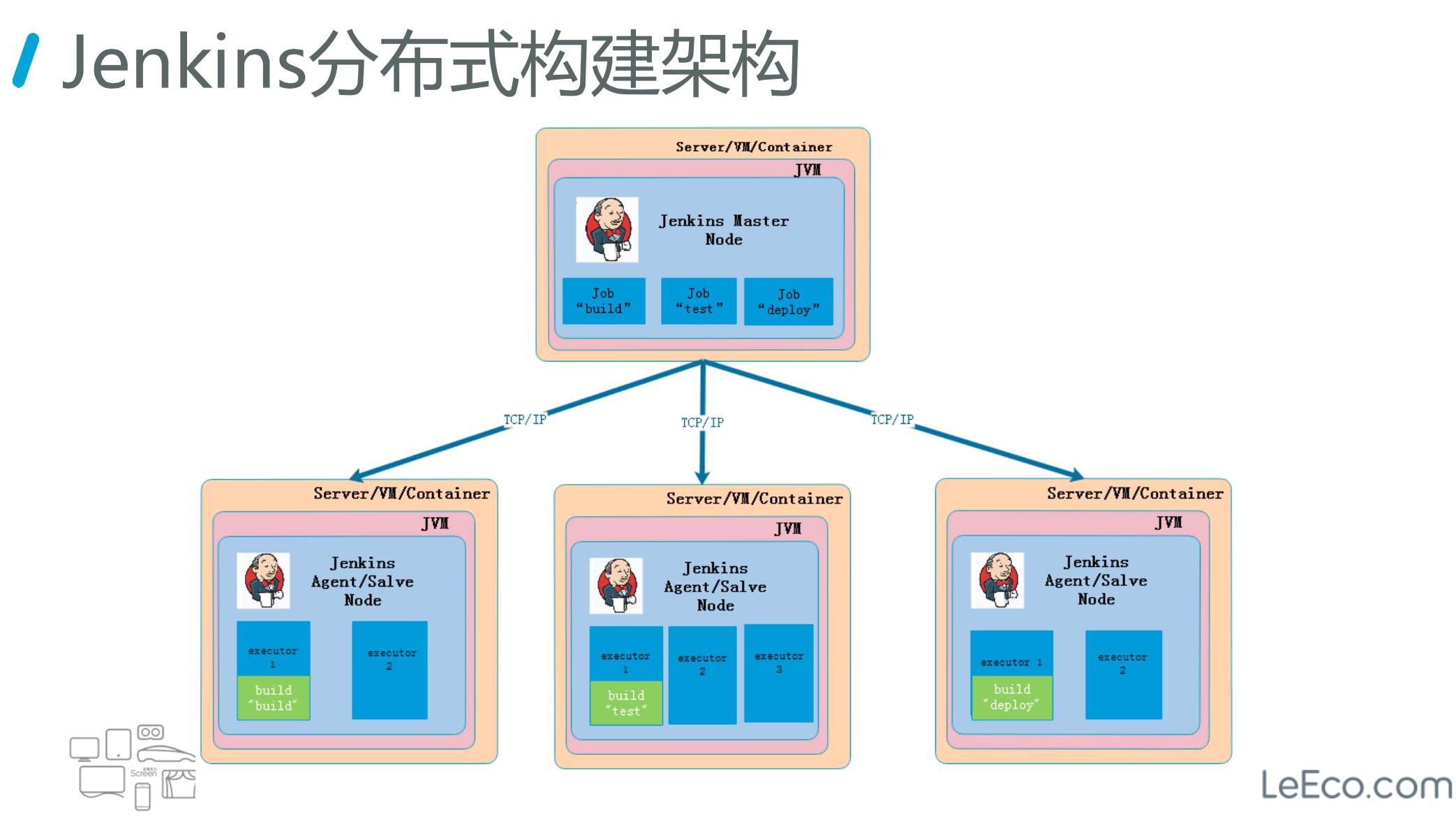
Jenkins 分布式架构一个 Master 和多个 Slave Node 分布式的架构。
在 Jenkins Master 上管理你的项目,可以把你的一些构建任务分担到不同的 Slave Node 上运行,Master 的性能就提高了。
如果单纯的使用 Master 去构建,除了要承担项目上的编译、测试等开销外,还会大大的影响 Jenkins 应用本身占用 memory 和 CPU 资源。
1.2 Jenkins Slave 连接方式
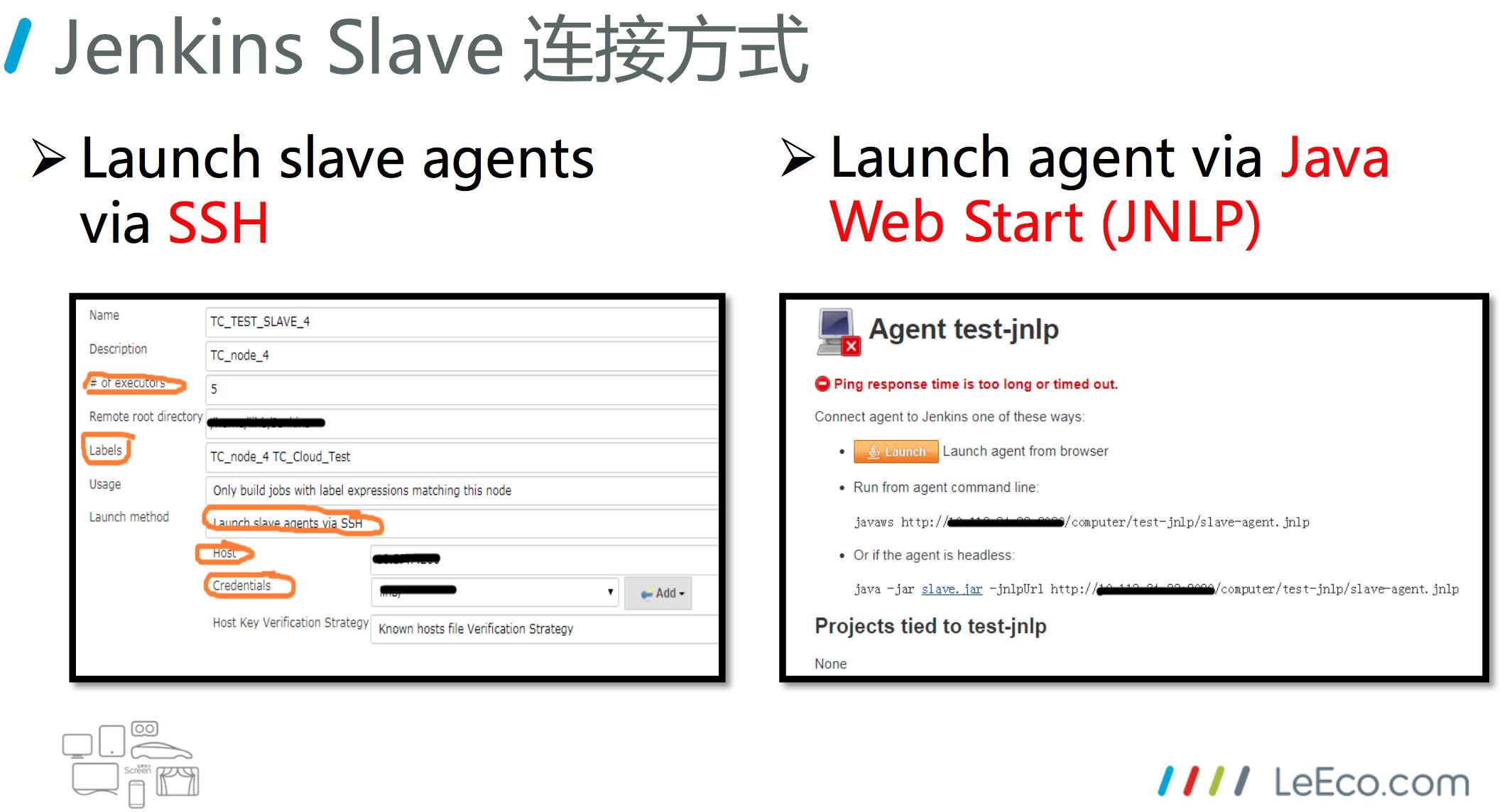
Jenkins Slave 连接方式常使用下面两种:
通过 SSH 启动 Slave 代理
在 Jenkins 上直接配置,相当于从 Master 往 Slave 上连接,从 Master 上主动发起的请求。
通过 JNLP 启动代理
基于 Java Web Start 的 JNLP 的连接,从 Slave 往 Master 主动的方式。
这两种主要的连接方式,在后面的集群 slave 的管理方案中都会涉及到。
1.3 Jenkins 调度策略

用户视角
直接使用 slave name,构建使用指定 slave
使用 label,构建多数使用同一个的 slave,偶尔使用其他 slave
系统实现
consistent hashing algorithm (node,available executors,job name)
每一个 Job 都有一个对应所有 Node 的优先级列表
其它插件
Least Load (https://plugins.jenkins.io/leastload)
Commercial plugin (Even Scheduler Plugin)
在使用的过程中,是不是都会经常感觉到下面两种情形:
如果一个项目的构建指定了一个 Slave,那么这个项目所有的每次构建都只用这个Slave构建。
如果使用了label 去管理多个 Slave,给一个项目的构建指定了这个 label,会发现这个项目的多次构建,大多数都是使用同一个 Slave,并没有使用 label 里的其它 Slave。
从 Jenkins 本身的实现角度来说,Jenkins 分配它的调度策略的时候,有一个一致性的哈希算法,会将你添加的 Slave,也可以称为 node 节点,以及 node 上面可用的 executors,包括 job name,最后算出来一个相当于你的 job 和所有 Slave 对应的优先级列表,会选择优先级最高的Slave去构建,当不满足条件或者没有可用的 executors 时,才会选用下一个节点。这个是 Jenkins 默认的调度策略,可通过其它插件来改变这个策略,如 Least Load 插件,选择一个数目最少的最空闲的节点。
二. 基于 Lable 的 Slave 集群管理
2.1 android 产品复杂环境
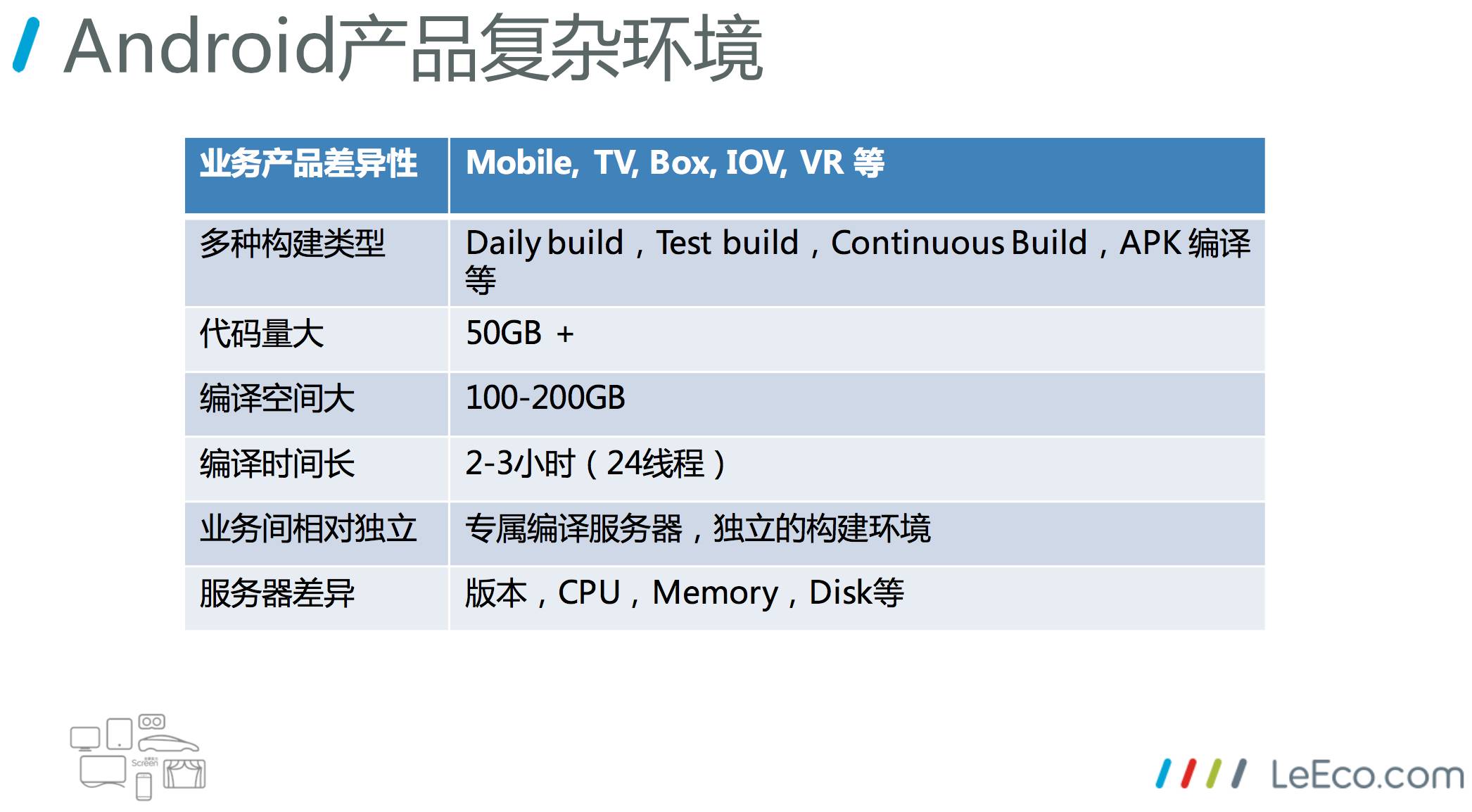
这是乐视安卓产品的环境。
业务产品差异性,要支持多个产品,如手机、电视、车、盒子、VR等,我所在的持续集成部门,全面负责所有生态业务的 CI 环境。
多种构建类型,我们常见的业务场景里面,有 Daily Build,Test Build,Continiuous build,APK 编译等,构建的类型不同。
代码量大,这是安卓产品的一个特点。像每一个TV的代码,源代码整个下下来就是50多GB,和一个普通的互联网应用,真的是差别太大了。
编译空间大,这么大的代码体量去做编译,所需的空间可想而知,一定要比你的代码量还大,编译完整个编译空间能达到100-200GB
编译时间长,代码量大,编译需要的空间多,相应的它的编译时间就很长。我们现在并行的物理机24线程去编,一般2-3个小时完成整个过程。
业务间相对独立。我们有多个产品,业务之间还相对独立,这个独立体现在两个方面,一个是我们不同的产品,比如手机和电视,有自己的专属编译服务器。另一个是服务器上有独立的构建环境,没有统一,这是业务之间的复杂性决定的。
服务器差异,版本、CPU、memory、Disk等配置不一样。
整体来讲,我们所面对的安卓产品的 CI 环境比较复杂,下面的内容也将围绕这个痛点来讲的。
2.2 普遍问题

表象问题:
Slave 很多,空闲的 Slave 也很多
队列中等待构建任务很多
一些构建失败,暴露 workspace 空间不足问题
原因分析:
业务间,编译环境不统一,不能跨业务共享
业务内,特定 jobs 直接绑定特定 slave,并发量受限于 executor 数目
Slave 上构建 workspace 的遗留,占用大量空间
业务量增大,新建 Jobs 增多,瓶颈出现
我们在使用 Jenkins 过程中暴露出一些问题,我们挂载的 Slave 很多,空闲的也很多,没有被充分利用起来。另外,挂载那么多的 Slave,我们队列中等待构建的还很多,相当于那么多的 Slave 没有解决并发的问题,任务还在等待。还有一些构建失败了,是因为 workspace 空间不足。
为什么会产生上述问题呢?
一个是业务间,编译环境不统一,不能跨业务共享。一台 Jenkins 上挂了那么多 Slave 给不同业务用,相对来说不同的业务只能使用这么多 Slave 中的一些子集。
第二是业务内,有些业务的同学去配置 job 的时候,直接绑定特定的 Slave,相当于直接绑定那个 Slave 的 name,而不是 Lable,这些 job 所有的构建只依赖于这个 Slave,这个并发就受到被绑的 Slave 的 executor 数目限制。
第三,Slave 上构建 workspace 有遗留,占用大量空间。一个 job 构建结束后,编译的空间遗留在 Slave 上,除非在你的 job 里配置了清理规则。
此外,随着业务量增大,新建的 job 也多,慢慢瓶颈就出现了,问题也就都暴露出来了。
在座的同学随着你们公司业务的发展,这些问题可能都会遇到的。
2.3 优化改进
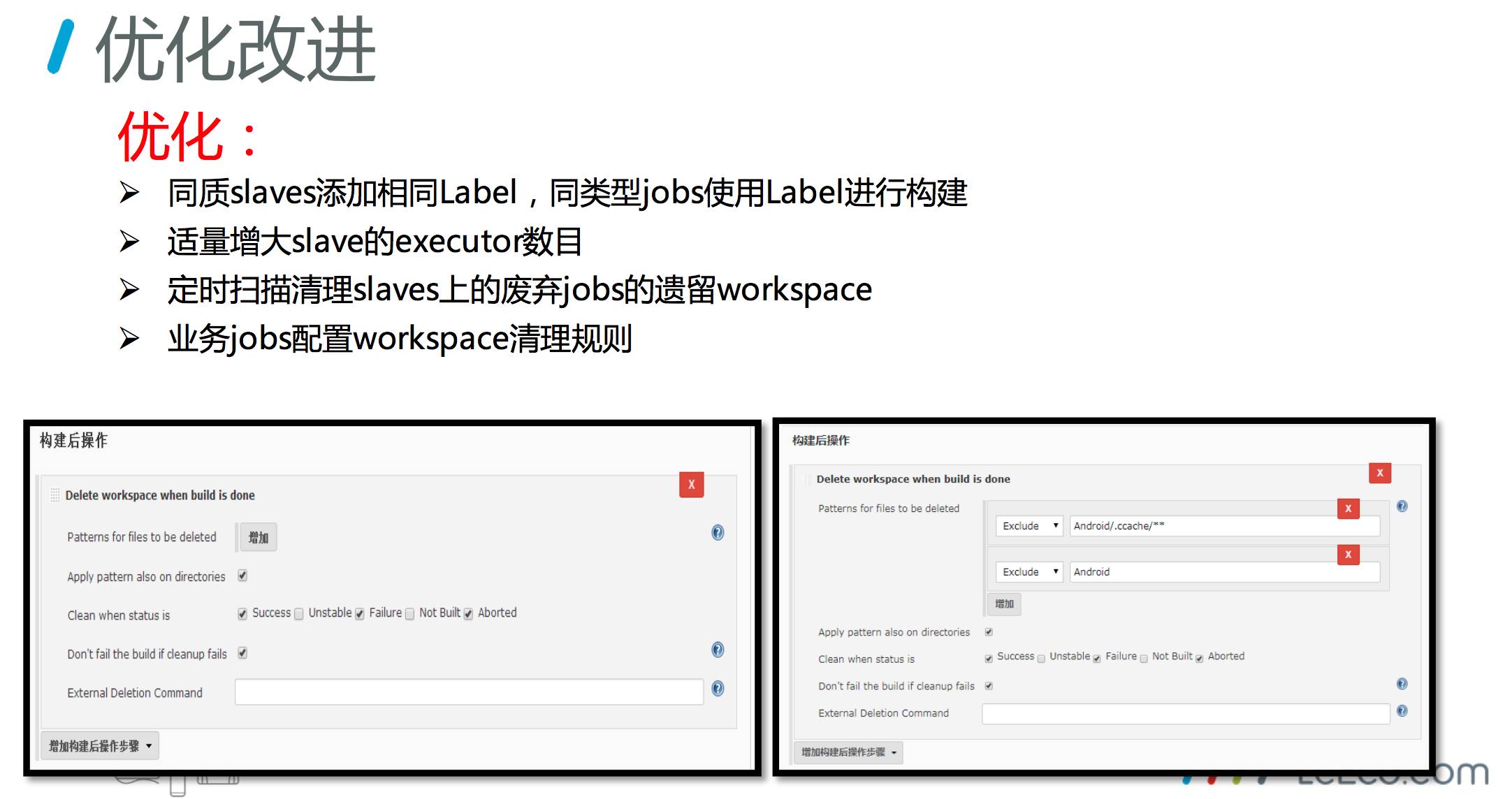
面对上述的问题我们改如何进行优化改进呢?我们做了四个方面的优化:
同质 slaves 添加相同 Label,同类型 jobs 使用 Label 进行构建
适量增大 slave 的 executor 数目
定时扫描清理 slaves 上的废弃 jobs 的遗留 workspace
业务 jobs 配置 workspace 清理规则
下面细说下。
我们把我们同质 Slaves 添加相同 Lable,用 Lable 来管理我的 Slaves,前面有说到我们的业务不同的产品线,相当于我们的编译环境不一样,同一套产品,把同质 Slaves 通过 Lable 使用,同类型 jobs 可以使用 Lable 进行构建。
适量增大 executor 数目,一定会增大并发量。为什么是适量?编译相当于我们用物理机24线程并发去跑,根据业务的场景不同,我们是适量的。比如原来一个物理机只配一个,根据有的产品线的 job 没有消耗那么多的 CPU、memory,编译时间要求不高,有一些 Slave 从一个 executor 增加到两个,就能解决 job 并发量的问题。
第三个要解决 Slaves 上遗留的编译 workspace 的问题,定时扫描 Slave 上的 workspace。有两点要注意,一点是在你使用过程中,可能会频繁的重命名 job,如果把 job 重命名了,原来的编译空间就留下来了,就没有意义了。另外,从业务job配置上,一定要配置相应的 workspace 清理规则。比如说编译结束了,传到版本服务器或者制品仓库,workspace 实际上没有意义,可以在构建结束后就配置相应的清理规则,把 workspace 清理掉,这样你的 Slave 上的空间就被及时释放了,而不会等到下一次构建的时候由于空间不足导致的失败。
在 Jenkins job 里面 Post build Action,有delate workspace 配置,可以针对勾选的构建的状态(成功、失败等),把这个 workspace 清理掉。默认清理的时候会把整个 workspace 都清理掉,一点都不留。
考虑到我们特殊的业务场景和编译的时间特别长,我们中间有一些编译缓存,如 ccache,保留的话对下次构建的编译速度上是有很大提高的。在配置清理规则的时候,我们没有完全清理,而是保留了需要的,其它的都被清理掉。从200GB清理到最后可能只有50GB,这就已经大大释放了空间。
2.4 优化效果
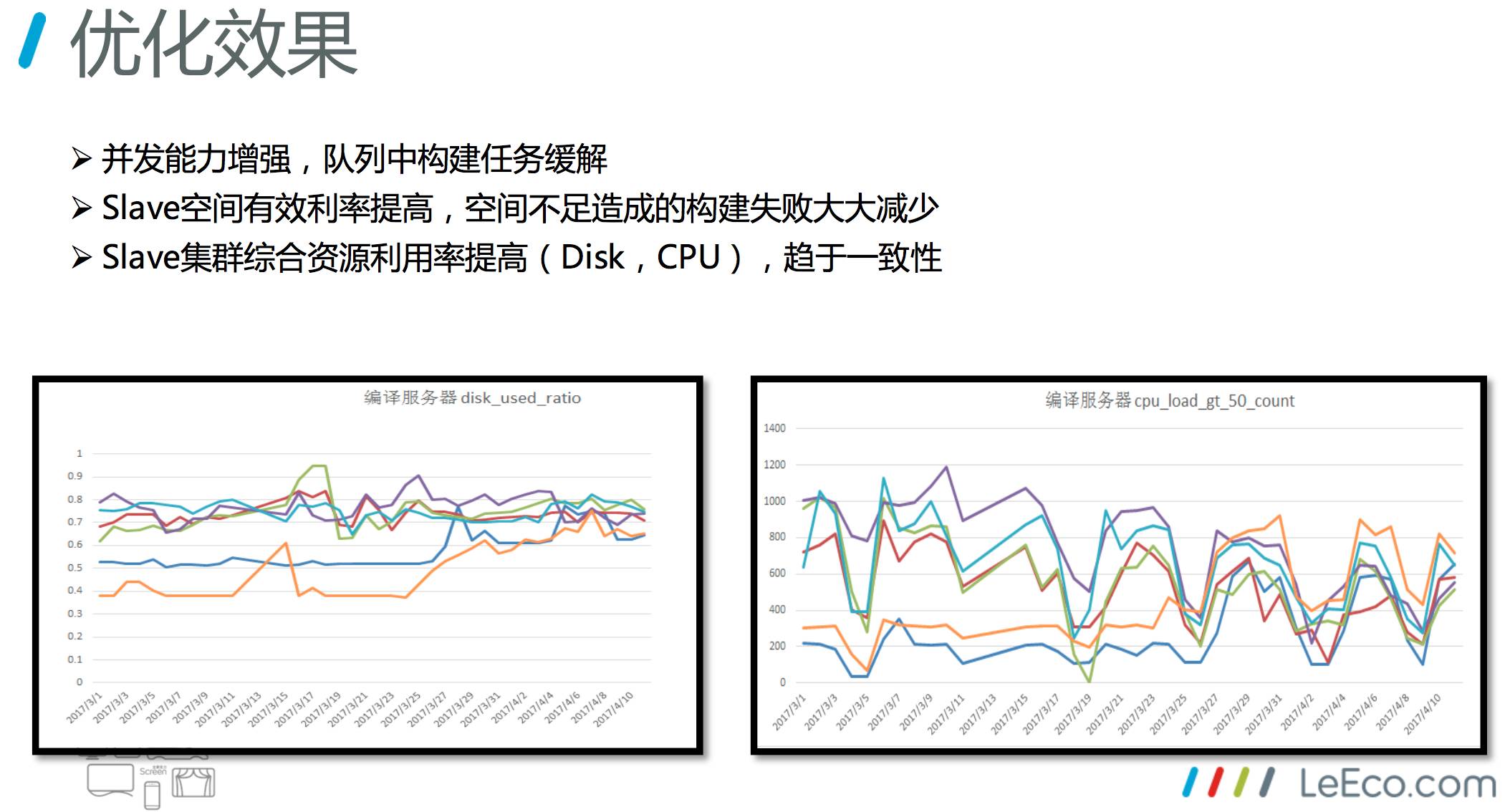
通过上述的优化改进,我们取得了下面三个效果:
并发能力增强,队列中构建任务缓解
Slave 空间有效利率提高,空间不足造成的构建失败大大减少
Slave 集群综合资源利用率提高(Disk,CPU),趋于一致性
并发能力增强,来自于用 Lable 去管理了,本身 Lable 关联了多个Slave,这个就相当于Slave构成了一个资源池,并发能力就提高了。带来的直接效果,并发能力强,队列中构建任务等待的数目就下降了。
Slave 整体的空间利用率有效提高,这方面做了一些清理,空间不足造成的构建失败大大减少。
整个集群,通过 Lable 管理,综合利用率提高了,反应到 Disk 和 CPU 上。上面两个图,左边是编译服务器的 disk,前面每一个 Slave 上它的 disk 使用率是不均衡的,通过使用 Lable 以后,相对来说 job 分到 Slave 上更加均衡,disk 慢慢趋于一致,而且是保持到相对合理的水平。右边这块是从CPU的角度,从前半部分开始看,不同的 Slave 节点上,上半部分这几台编译的时候 CPU 利用率很高,但下半部分这几台非常空。随着加了 Lable 以后,它们的趋势趋于一致。
2.5 Lable 方案反思

这个是对使用 Lable 管理 Slave 的一些总结和反思:
益处:
Slave 资源池化,整体资源利用率提高
并发量增大(受所有 slave 的 executor 数量限制)
Slave 的管理对 Job 配置透明化(Job 配置 Label 使用)
局限性:
Jenkins 内置的调度策略,资源利用不均衡
同一个 job 的多次构建倾向于使用同一个 slave
同一个 job 的并发构建,往往使用同一个 slave,资源竞争造成构建时间增加等
某几个 jobs 构建,往往使用同一个 slave,资源竞争造成构建时间增加等
环境隔离问题
不同类型的 job 资源需求不同,环境复用后资源调度是问题,加大管理成本
环境不统一,业务调整,资源再分配要回炉重构(安装对应的工具系统等)
基础设施一致性问题
多个任务跑在同一台资源上的潜在风险和冲突,不可变基础设施
环境问题导致的CI信任问题,代码没错,是环境问题
这个就不展开来说了,有利有弊,应以实际需求情况来进行合理的趋避。
三. 基于 Docker 插件的容器化实践
3.1 APK 编译需求

APK 编译需求所面临的现状主要有以下几点:
单点编译服务器支持所有 APK 编译构建
服务器性能比较差
环境依赖复杂,工具维护成本高
构建任务并发比较困难
该如何去改进这些问题呢?我们决定使用容器化,基于容器化去构建 Jenkins Slave,直接使用 Docker 插件进行容器化。
业务的需求依然是第一驱动力。
3.2 Docker image 固化编译环境

固化 Docker image 内容,最基本的要有账号和权限,里面要有相应的构建账号,包括权限。因为 Docke image 有可能去下代码,版本仓库等等其他的集成,都需要相应的权限。
使用 Docker 插件去构建,这个就类似于普通的 Jenkins Slave。与用 SSHD方式一样,Docker image 必须用到 JDK 和 SSHD。
另外在业务上,APK 编译的依赖工具,比如不同安卓 SDK/NDK、libs 和工具等。
在固化 Docker image 过程中还有一些要考虑的问题,比如 Docker image 和业务产品以及不同版本工具集的关系。我们是多套产品,怎么去管理呢?是做一个大而全的 Docker image 来涵盖所有的还是每一个产品线做一个 Docker image,每一个产品线里工具有不同的版本。我们现在基本上是按产品线走的,比如手机、电视的,我们给它一套 Docker image。
另外是 Docker image 自动化配套设施,如自动化构建、更新、上传、部署等,这些配套的措施需要额外去维护的,这和普通的 Slave 不一样。
3.3 Jenkins 集成 Docker 插件

这里是我们使用 Docker 插件的信息,使用的版本是0.15.0,它所支持的连接方式只能是 SSH 的连接方式。从0.16.0版本开始支持JNLP的连接方式。(最新版本已经不是0.16.2了,详细信息请查看官方网站。编者注)
插件的配置有两点值得注意的:
可以添加1个或者多个 Docker host 的信息,Docker 也提供一个 Cloud 集群,这个 Docker host 可以理解成我们原来普通的 Slave。
每一个 Docker host 下面可以添加关联1个或者多个 Docker Template。
3.4 配置示例
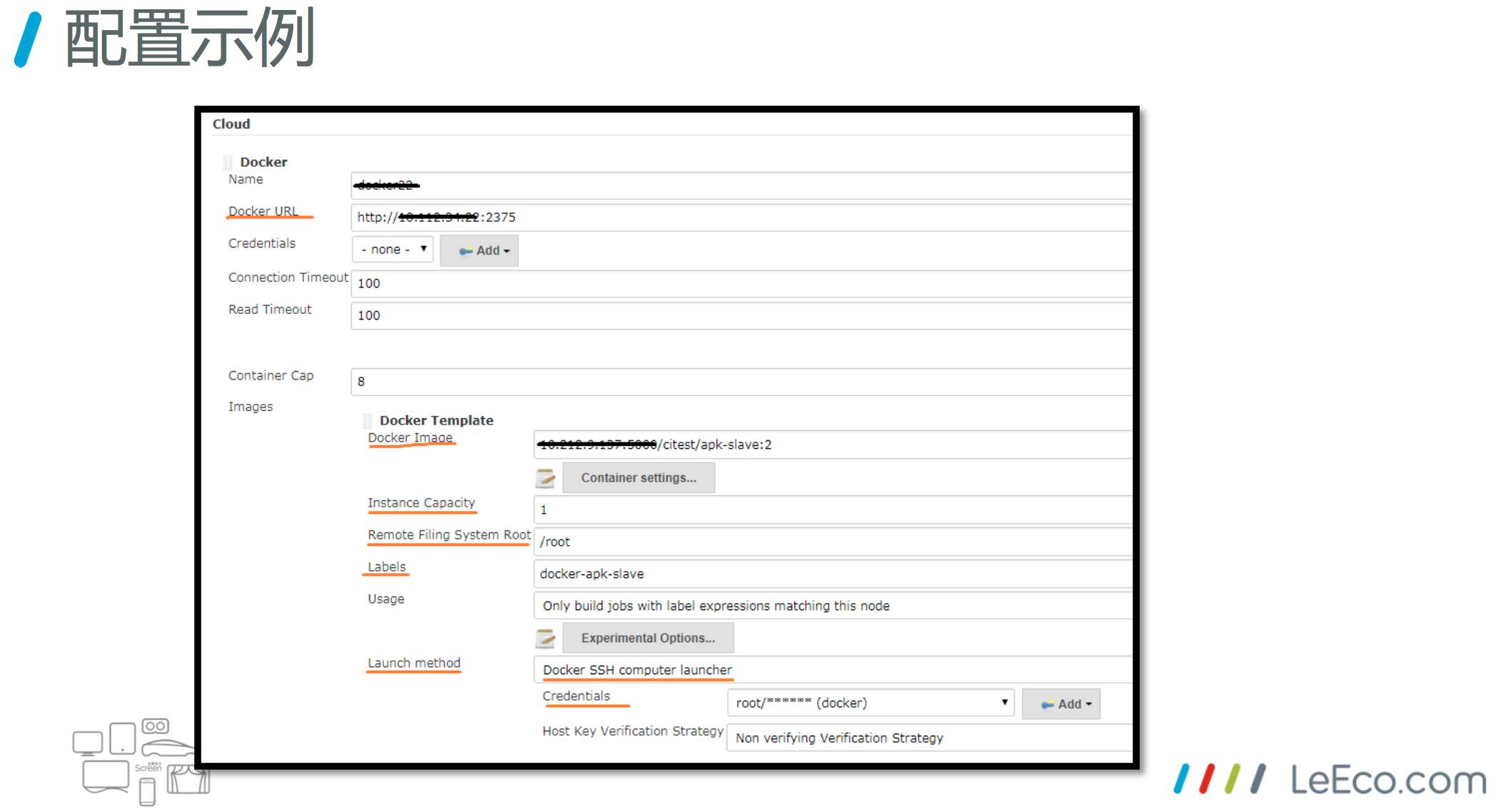
看一下配置示例。
Name 要指定一个 Docker 配置的名字。
Docker URL 是你 Docker 的URL,通过什么样的方式去连接 Docker host。
Container Cap 设置并发数量。
Docker Template 可以添加多个 Docker 模板,这里只是列了一个,每个 Docker 模板实际上是从哪里可以获得你的 Docker image。
Launch method 有一个连接方式,当时这个插件只支持SSH,我们只能通过SSH的方式。
3.5 Docker插件反思

这个是对使用 Docker 插件的一些总结和反思:
益处:
容器化(环境标准化,隔离性,版本,可移植性 等等)
容器 Slave 按需弹性收缩,自动创建,使用,销毁
资源共享
多个 jobs 使用不同容器 slave 可以运行在同个 Docker host
同一 Job 通过使用 label,也可以让构建运行在不同 Docker host 上的容器 slave 上
并发量(插件设定 cloud/template Capacity)
局限性:
插件配置中 Docker host 与 Docker image 的强耦合性,配置不方便
Docker host 数量很多的时候
Docker image 需要配置到多个 Docker host上的时候
使用Jenkins内置的调度策略,资源利用不均衡
相同 Docker image 配置到多个 Docker host上 使用相同 label 的时候
使用这个方案给我们带来了什么样的好处,有没有什么样的局限性呢?
带来的好处有:
第一,容器化。环境标准化、隔离性、本身 Docker image 有版本,相当于对构建有一个版本控制,还有可移植性,构建一次,host都可以去配都可以去使用。
第二,通过 Docker 插件配置了 Cloud Slave 架构,容器的 Slave 就可以弹性进行收缩。一点有了构建需求,它就会去动态的生成一个 Docker 容器挂载为 Jenkins Slave 进行构建。构建结束以后,这个容器就会被自动销毁。所以整个过程不再是原来那种普通的 Slave 长连接的方式挂载,这种往往使用过了,就看不到了,动态销毁了。
第三,资源能得到共享,因为多个 job 我们使用不同的容器 slave,可以运行到同一个 Docker host,也就是说 Docker host 上我们可以配置多个 Docker image,提供不同的模板,不同的 job 都可以使用,很多 job 的构建可以扔到同一各Docker host 上去用。另外同一个 job,通过配置 Lable可以让你的构建运行在不同的 Docker host。每一个容器,你添加 Docker image作为模板的时候,都有一个 Lable,这个和普通的 Slave 一样,你可以添加一个或多个 Lable。
第四,并发量,在插件里设定。整个 Cloud,你可以设定能支持多少个实例。template Capacity 决定了你最大的并发量。每一个模板,每一个 image 也可以控制的。
有好处就有不好的地方,插件中的 Docker host 和 Docker image 是强耦合性,必须在每一个 Docker host 下面配置你需要的应用。在 Docker host 数量很多,Docker image 需要配置到多个 Docker host 上共享的时候,这种配置就很不方便了。
另外,调度还是使用内置的策略,也存在不均衡性。比如有两台 Docker host,上面配置了同一个 Docker image,往往是先仍到第一个 Docker host上构建。
四. 基于 Kubernetes 的容器化实践
前面通过使用 Lable 到 Docker 插件,我们一步步去改进。同时也发现基于 Docker 的容器化,还是存在上面的局限性,并不能满足我们的需求,因此还是需要进一步优化看能不能有更高的提高。
4.1 What is Kubernetes?
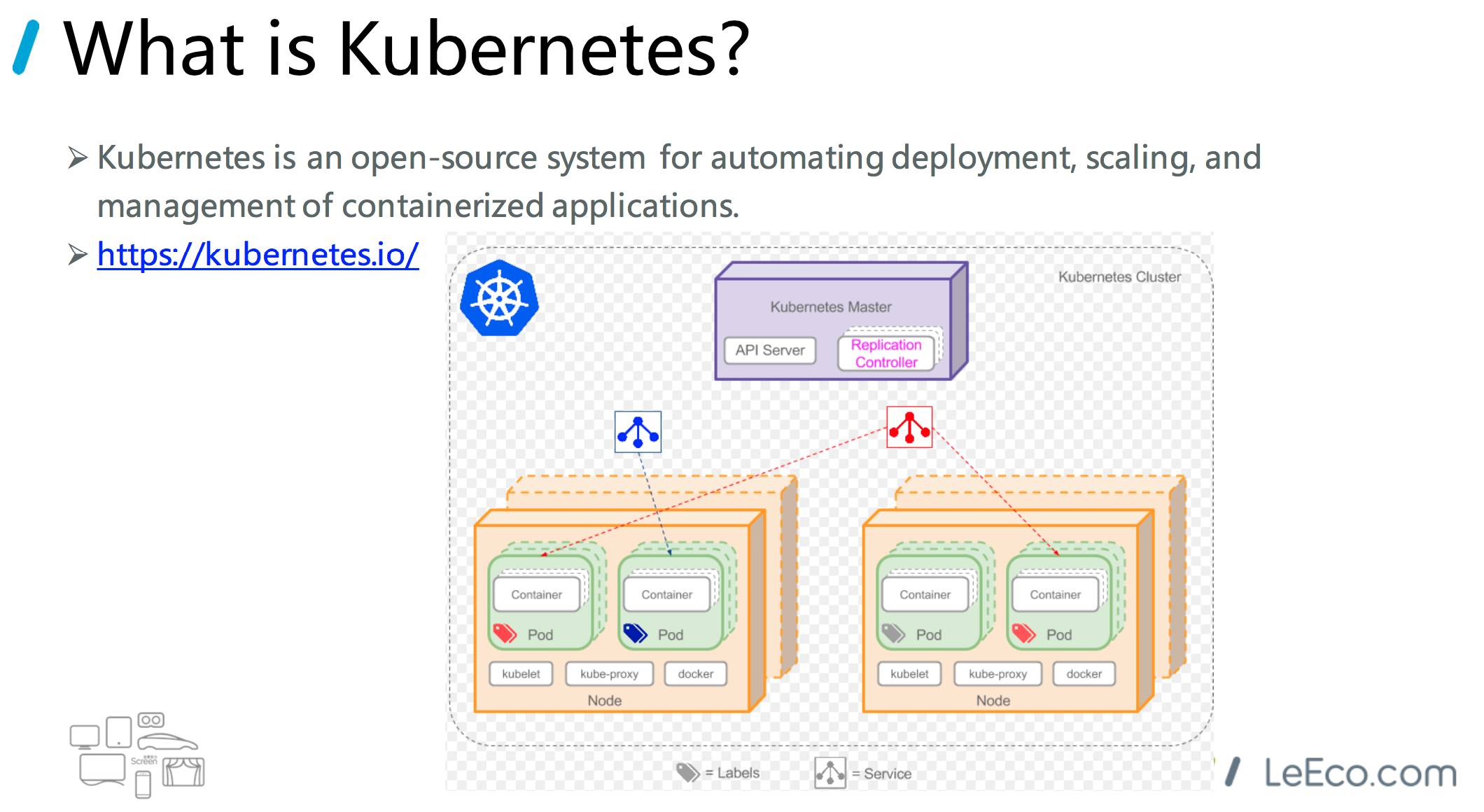
kubernetes,使用过这个容器工具的可能比较熟悉。开源的,可以自动化,容器化一些应用的部署。
这个是它的一个架构图,这里面有一个 pod 的概念,相当于一个 pod 可以有多个 Container。后面我们讲到的 kubernetes 插件就是通过创建一个 pod 来挂载一个容器 slave 的方式。
4.2 业务需求

这是我们的一个业务需求:
资源收缩严重,业务需要正常运转
容器化/标准化,构建环境隔离
K8s资源限制,调度策略,服务器资源共享
其他考虑因素有:
容器化构建性能对比
版本的选择
Docker registry
Docker image的构建更新自动化
构建环境工具依赖
构建优化(代码 mirror,编译缓存等)
4.3 数据验证可行性
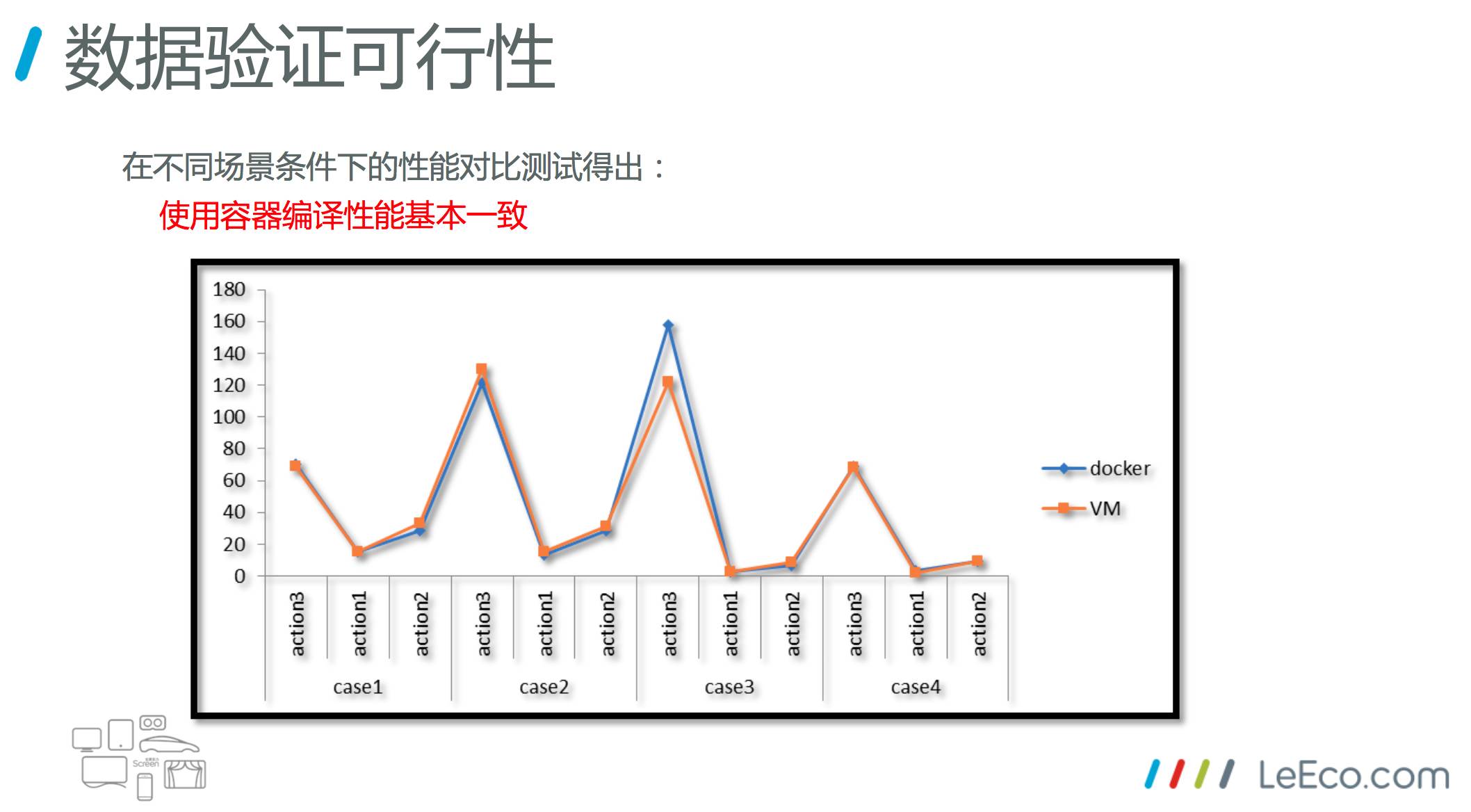
这是我们做的一些数据验证,之前我们是对 APK 编译,就是一个简单的应用。但是我们要对整个安卓产品,比如手机电视,这个量就不一样了。我们必须要做好充分的测试,使用容器去编译性能到底靠不靠谱。
通过使用VM去编译和使用 Docker 容器编译,不同的场景做了一个对比测试,编译性能基本上是一致的。所以才下决心把我们的业务都往这上面去迁移。
4.4 选择版本
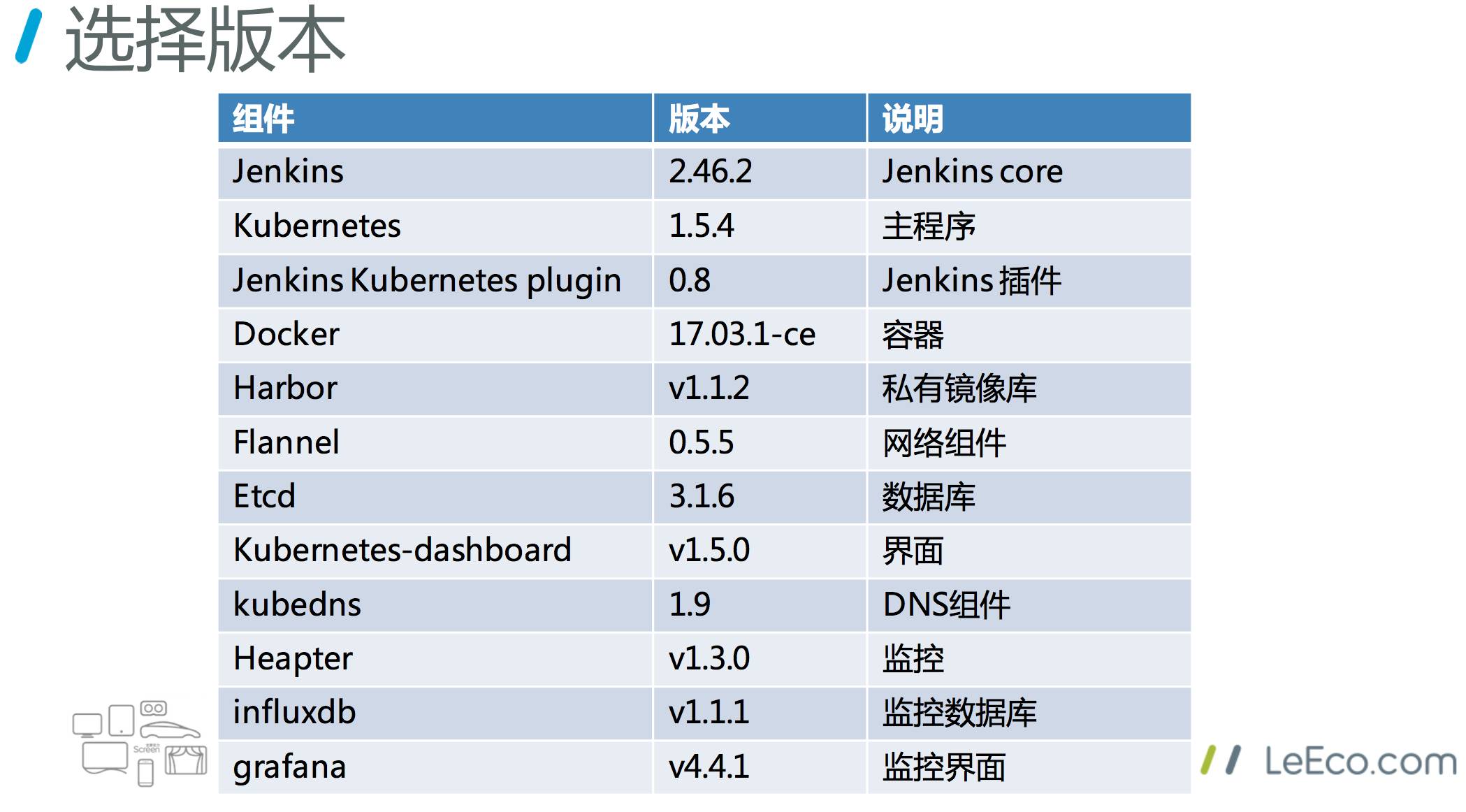
这个是给大家一个参考,我们所使用的一些主要工具或者组件的版本。
4.5 Docker image的构建

通过 Dockerfile 自动化构建我们的 Docker image。另外,我们使用 Ansible 来批量部署管理环境。我们的CI构建环境做得非常不错的,这个地方沿用了我们的优势,基于 Ansible playbook 的基础上来构建我们的容器。上面是 Dockerfile 的一个示例。
4.6 构建环境依赖

外部工具
单一可信数据源,单独服务器管理, Ceph存储
所有k8s Node 通过NFS挂载
容器通过 volume 使用
代码 mirror
所有 k8s Node 本地目录
容器通过 volume 使用
Jenkins job 自动化更新部署
编译 cache
所有 k8s Node 本地目录
容器通过 volume 使用
命中率统计和多基线复用
4.7 Jenkins 集成 k8s 全景
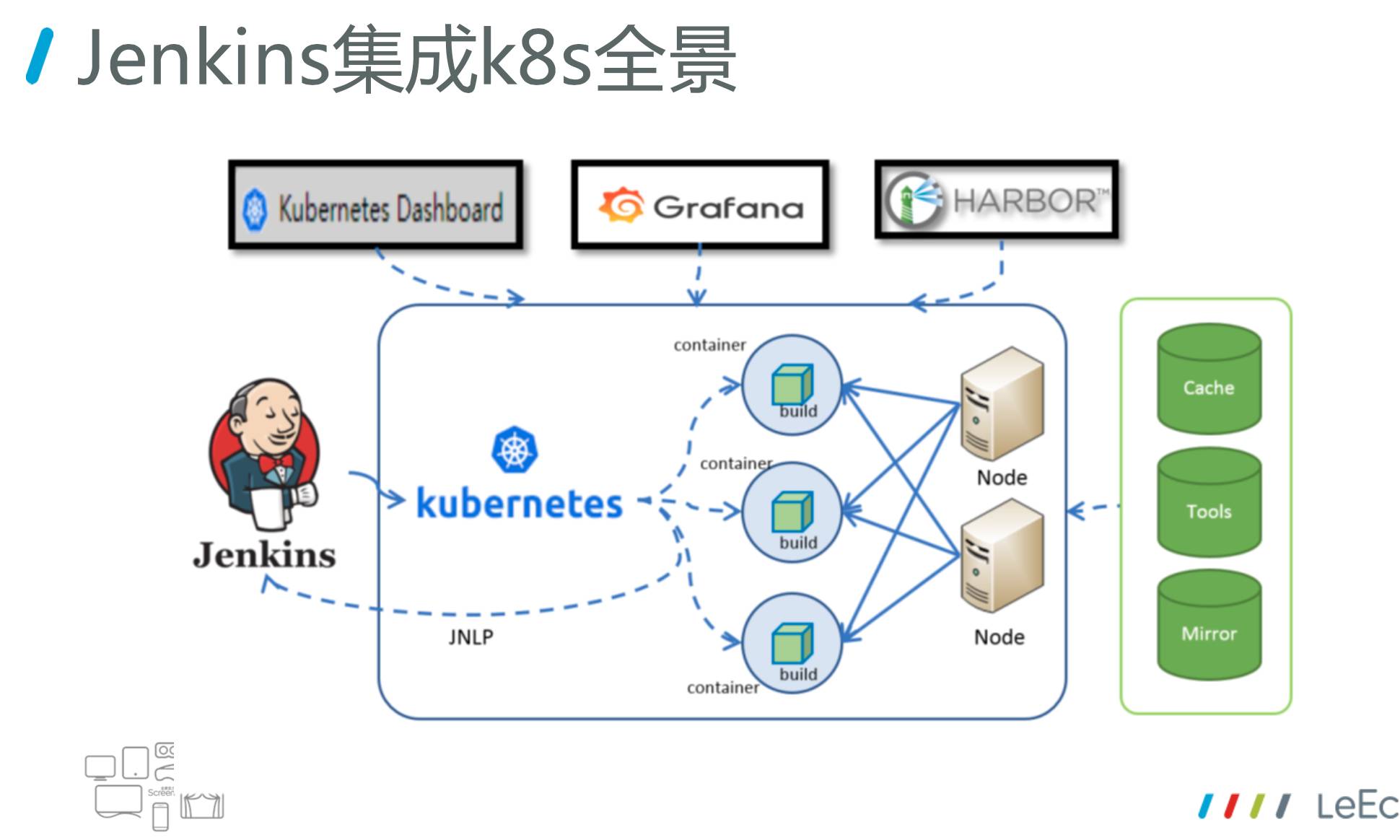
这里是一个全景图。Jenkins 里有k8s的插件,中间这块是k8s集群,多台物理机做k8s的节点,我们所有的编译构建实际上都是通过插件在 Node 上建了一个容器,这个容器挂载为 Jenkins 的一个 Slave。右边和上面这块是外部的依赖,比如 cache、Tools、Mirror、HARBOR、Grafana等等。
4.8 实现效果
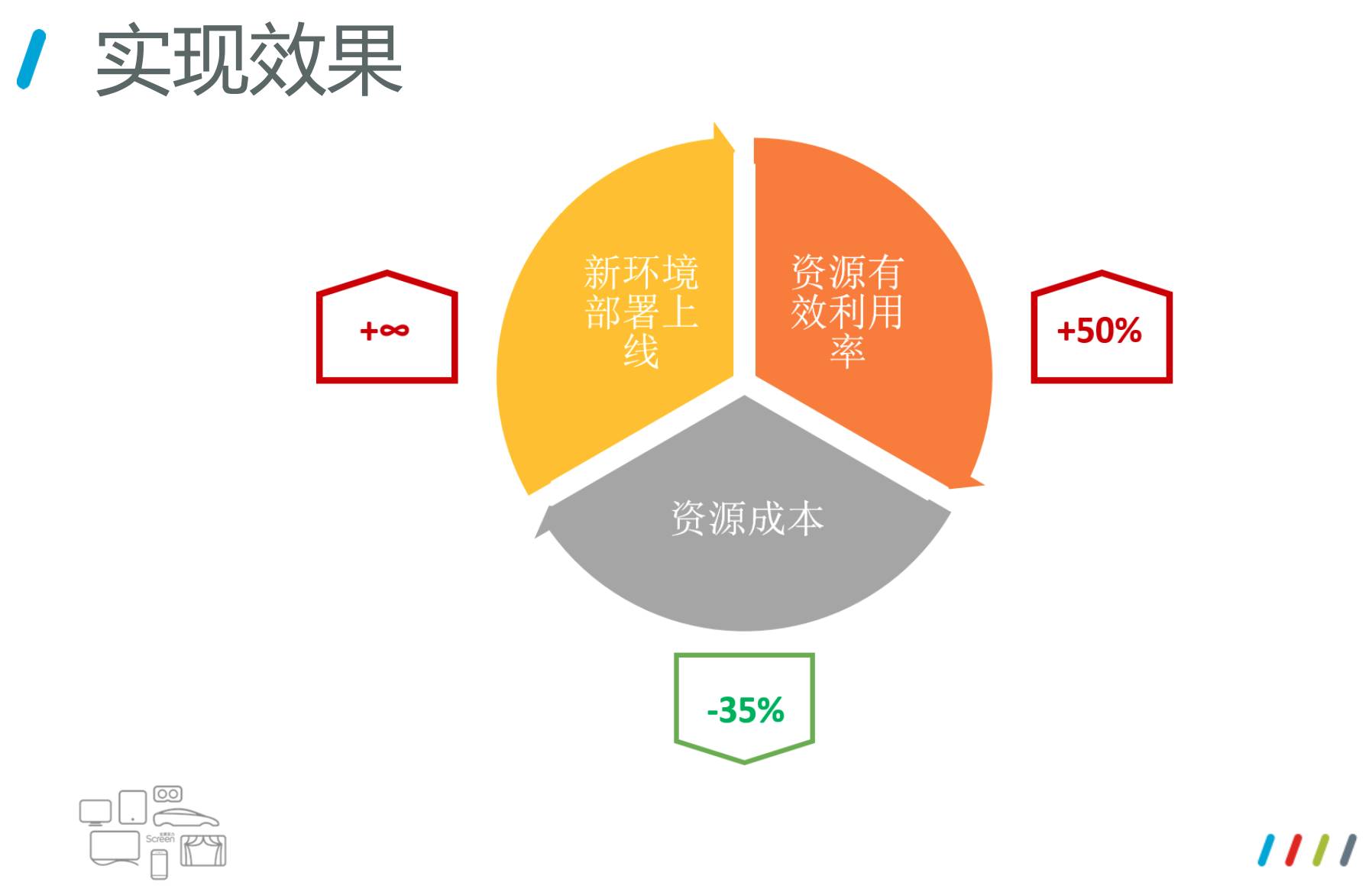
迁移到容器化以后,我们整个资源利用率有50%以上的提升,资源成本也下降了35%,另外是新业务新环境上线,这个带来的好处没法统计,相对来说是很大的。
4.9 Kubernetes插件

配置 Kubernetes API URL
添加1个或多个kubernetes pod template (image)
kubernetes pod template 的启动命令间接使用JNLP
kubernetes pod template 可以配置资源限制, 主要是CPU和Memory资源
4.10 配置示例
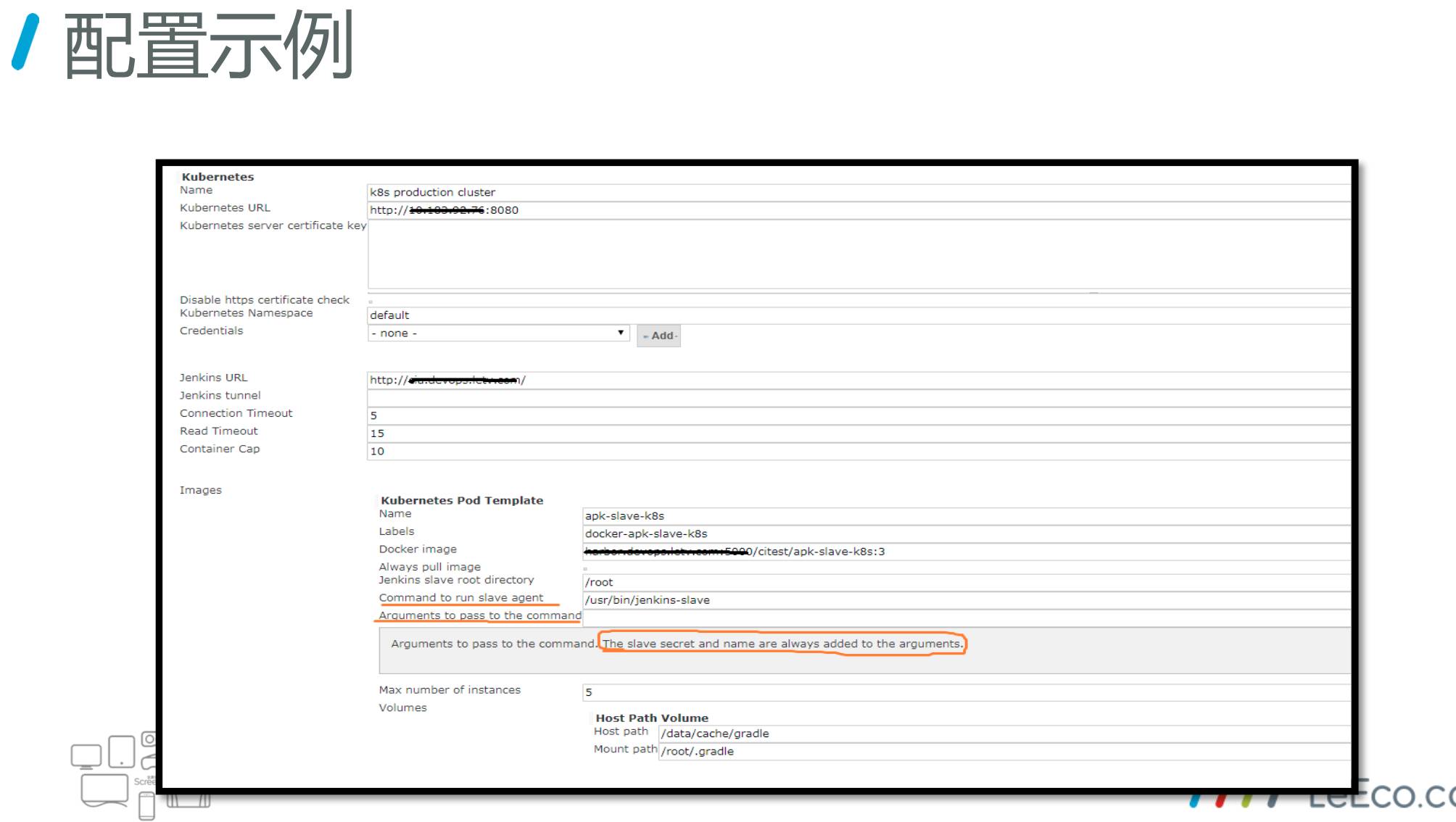
这是一个配置示例,注意划线部门。
4.11 资源限制配置示例

这是一个资源限制配置示例。对CPU、memory做一些资源限制。
4.12 容器启动脚本示例

容器启动脚本示例,这上面两个参数 SECERT、SLAVE_NAME,这是k8s插件默认传递过来的启动参数。JENKINS_URL默认 设置为POD的环境变量。
4.13 Kubernetes插件反思

每一个方案我们最后都要去做一个反思和总结。
k8s插件的益处:
容器化(环境标准化,隔离性,版本,可移植性 等等)
容器Slave 按需弹性收缩,自动创建,使用,销毁
资源共享(所有的容器slave可以共享 Kubernetes cluster)
并发量(插件设定Cloud/Template Capacity)
k8s插件的局限性:
Kubernetes Cluster 的高可用性
单master,这个Master要挂了所有构建集群都挂了
需要用户实现HA方案
4.14 持续改进
持续改进方面:
Jenkins master容器化
Jenkins Job脚本化
流水线驱动持续交付
4.15 总结
| 方案 | 效果 | 注意点 |
|---|---|---|
| Lable | 1.Slave资源池化,整体资源利用率提高 2.构建并发量 3.Slave的变动对Job配置透明化 |
1.环境一致性,相同label下slave要求同质 2.Slave上jobs构建遗留workspace问题 3.Jenkins默认调度策略的不完美性 |
| Docker | 1.容器化带来的好处(环境标准化,隔离 性,版本,可移植性 等等) 2.容器Slave按需弹性收缩,自动创建, 使用,销毁 3.服务器资源共享 4.构建并发量设置 |
1.Docker host与Docker image的强耦合性,插件配置不方便性 2.使用Jenkins默认调度策略 3.Docker registry、image管理等配套工作 |
| Kubernetes | 1.Docker插件相同的优点 2.资源申请限制等配置,满足不同构建需求 3.使用Kubernetes调度策略 |
1.Kubernetes Cluster的高可用性问题 2.监控的重要性 3.Kubernetes、Docker registry、image管理等配套工作 |
这个是上面三种方案的一个总结。每一个方案都有好的效果和注意点,不同的方案都有各自不同的优缺点,谁优谁劣取决于具体实施场景。应根据业务实际情况来选取适合的方案。
END
更多相关文章阅读
Jenkins 创始人、Apple 和微软等专家邀您一起参加
国内首届【Jenkins用户大会】

独乐乐不如众乐乐,DevOps 时代社区长期欢迎原创作者投稿,DevOps 时代社区愿陪伴您共同成长。投稿邮箱:liuce@greatops.net
点击阅读原文参与大会报名
以上是关于基于 k8s 的 Jenkins 构建集群实践的主要内容,如果未能解决你的问题,请参考以下文章