图像识别 | 道路识别的自动驾驶算法基本原理
Posted 沈浩老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别 | 道路识别的自动驾驶算法基本原理相关的知识,希望对你有一定的参考价值。
前几天看到一篇国外博客文章写关于道路识别的图像算法,实现自动驾驶的基本原理,看看很有感觉,就把大致原理写下来,分享一下,也算普及!
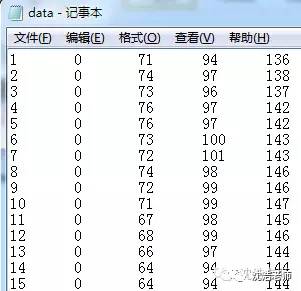
早期的微信公号上,我们写过一篇介绍如何将一张图片转换成数据:坐标点(x、y)和(R、G、B)

ImageJ软件是一款极其强大的对图像进行处理的软件。我们可以通过加载beach.jpg这张图片(沈老师拍的),对其进行如下处理,在Analyze的Tools中选择Save XY Coordinates来获得如下结构的数据,它分别输出数值为X值、Y值、R、G、B。
最终通过tableau可以再次生成彩色图片。
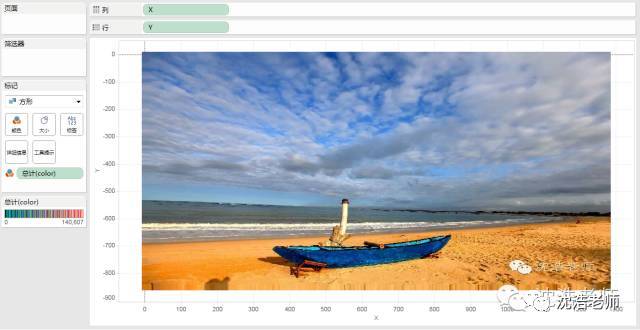
对于自动驾驶汽车实现道路自动识别建模算法模型需要考虑两方面:1)自动驾驶程序,2)自动驾驶硬件。
通过图像识别软件将使用传感器或道路输入数据通过算法生成驾驶指令,硬件控制系统在实际车辆内执行这些驾驶指令。
但是对于大多数人来说,软件如何实现道路图像识别呢?
本篇文章的重点在于通过算法软件达到以下成果:
1、基于道路视频输入,可以确定如何安全有效地引导汽车。
2、基于驾驶环境的视频输入,软件可以识别/分类障碍物(行人,其他车辆等)和路牌等。
3、基于道路的视频输入,软件可以确定如何安全有效地使用汽车的加速和制动机制。
一般在运行任何代码之前,需要确保计算机设置了相应的python库。
特别是,需要为Python安装numpy,matplotlib和OpenCV库,目前很多道路识别软件使用Tensorflow 深度学习python库。

我们来看看如何通过对图像进行处理,实现道路识别。

图像是排列在矩形中的一系列像素点,这个特定的矩形是960像素 540像素。每个像素的值是由红色R,绿色G和蓝色B的一些组合,并且由三个数字组合表示,其中每个数字对应一种颜色的值。每个颜色的值可以在0到255之间,其中0是完全没有颜色,而255是100%强度。
例如,白色可以表示为(255,255,255),相反黑色表示为(0,0,0)。
因此,该输入图像中,共有960×540 = 518,400个点,可以由(0,0,0)到(255,255,255)的数组进行描述。
如何将彩色图片转化为上述像素点的方法也有python代码。
通过这些操作,现在这个图像变为了一个数字的集合,我们可以开始通过数学的方法来使用这些数字。
第一步:灰度图像处理
也就是将彩色图像转换为灰度,有效地将颜色空间从三维降级到一维。只有一维来处理图像要容易得多(而且更有效):一维是像素的“黑暗”或“强度”,0表示黑色,255表示白色,126表示一些中间灰色。
直观地说,预计灰度滤波器只是将红色,蓝色和绿色值平均到一起的灰度输出。例如,这是原始照片中的天空颜色:

它在RGB(红色,绿色,蓝色)空间中表示为(120,172,209)。
简单的计算平均值,这个颜色在灰度空间中为(120 + 172 + 209)/ 3 = 167。

但是,事实证明,当使用上述算法代码将此颜色转换为灰度时,实际输出的颜色为164,与使用简单平均方法生成的颜色167略有不同。

简单平均的方法并不是“有什么”不对的地方,但在计算灰度时常用的方法是计算一个能够更好地匹配我们的眼睛察觉颜色的加权平均值。换句话说,因为我们的眼睛拥有比红色或蓝色的受体更多的绿色受体,绿色值应在计算灰度时有更大的权重。
彩色图片转换为灰度图片,其中比色转换的一种常用方法是使用加权和:
我们的算法中使用加权和为:0.2126红+ 0.7152绿+ 0.0722蓝。
在通过灰度过滤器处理原始图像后,我们得到以下图像:

第二步:高斯模糊
使用高斯模糊算法,使我们上一步得到的图像更为平滑。(高斯分布就是采用正态分布平滑的算法)
通过应用轻微的模糊,我们可以从图像中去除最高频率信息(也称为噪声),这将使我们能够分析“更平滑”的色块。
同样,高斯模糊算法使用的数学原理是非常基本的算法:一个模糊只需要更多的像素平均(这个平均过程是一种内核卷积,要解释清楚也不必要了)。大致步骤:
选择照片中的像素并确定像素值。
找到所选像素的相邻区域的值(我们可以任意定义此“本地区域”的大小,但通常相当小)。
取原始像素和相邻像素的值,并通过某些加权算法将它们平均。
用输出的平均值替换原始像素的值。
对所有像素执行此操作。
对于高斯模糊,我们仅仅使用高斯分布(即正态分布曲线)来确定上面步骤3中的权重。这意味着一个像素越接近所选择的像素,其权重就越大。
这个步骤并不想让图像模糊太多,模糊结果只要足够让我们从照片中删除一些噪音。得到结果如下图:

第三步:Canny边缘检测
通过上述两步,我们得到一个灰色且进行高斯模糊的图像,我们将尝试找到这张照片的所有边缘线。
注意:边缘只是图像中灰度值突然跳跃的一个区域。
例如,灰色道路和虚线白线之间有一个明显的边缘,因为灰色道路可能具有像126这样的值,白线的值接近255,并且这些值之间没有逐渐的过渡。
Canny边缘检测过滤器使用非常简单的数学算法来找到边缘:
选择照片中的像素点
识别所选像素元左侧和右侧的像素元组的值。
计算两组之间的差异。
将所选像素的值更改为步骤3中计算的差值。
对所有像素执行此操作
所以,假设我们只看着所选像素左侧和右侧的一个像素,并且假设这些值是:(左像素,所选像素,右像素)=(133,134,155)。然后,我们计算右和左像素之间的差值,155-133 = 22,并将所选像素的新值设置为22。
如果所选择的像素是边缘,则左和右像素之间的差值将较大(更接近255),因此在输出图像中将显示为白色。如果所选择的像素不是边缘,差值将接近0,并显示为黑色。
当然,上述方法只能在垂直方向找到边缘,所以必须继续完善算法。需要继续比较所选像素的上下相邻的像素,以便在水平方向上找到边缘。
这些差异称为梯度,我们可以通过使用“毕达哥拉斯”定理来计算总梯度,将垂直和水平梯度中各自的权重加总。
换句话说,我们可以说总梯度的平方 =垂直梯度的平方 +水平梯度的平方。
例如,假设垂直梯度等于22,水平梯度等于143,则总梯度= sqrt(22^2 + 143^2)=〜145。
因此,输出结果如下图:

Canny边缘检测过滤器不是只显示所有边缘,而是尝试识别所有重要的边缘。为此,我们设置两个阈值:高阈值和低阈值。假设高阈值为200,低阈值为150。
对于任何具有大于200的高阈值的总梯度,该像素自动被认为是边缘,并
转换为纯白色(255)。对于任何具有小于155的低阈值的总梯度,该像素自动被认为“不是边缘”,并被转换为纯黑色(0)。对于阈值为150到200之间的任何梯度,只有当它直接接触已经被计数为边缘的另一个像素时,该像素才被算作边缘。
这里的假设是,如果这个软边缘连接到硬边缘,它就可能是同一个对象的一部分。在所有像素完成这个过程后,我们将会得到一个看起来像这样的图像,

第四步:掩盖非车道边缘图像
下一步骤非常简单:创建一个掩码,消除图片中所有我们假设不是车道线的边缘。我们得到图:

虽然这个掩码看起来十分粗略,但是却十分有效。
第五步:霍普线
最后一步是使用霍夫变换找到车道线的数学表达式。
霍夫变换背后的数学算法比我们上面所做的加权平均算法稍微复杂一些。
基本概念:
车道线是一个线性方程式:等式为y = mx + b,其中m和b分别表示线的斜率和y截距。
从本质上讲,要使用霍夫变换,我们确定了m和b的二维空间。这个空间代表了m和b的所有组合,我们认为可能会为车道线产生最适合的线。然后,我们总览m和b的这个空间,并且对于每对(m,b),我们可以确定y = mx + b形式的特定方程。
在这一点上,我们想检验这一方程线,我们在照片中找到了这一条线的所有像素,并要求他们投票,如果这是一个很好的预测路线。像素如果是白色(即为边缘的一部分),则投票为“是”,如果为黑色,则投票为“否”。
获得最多投票(或在这种情况下,获得最多投票的两对)(m,b)坐标被确定为两条车道线。
这里是霍夫变换的输出图:
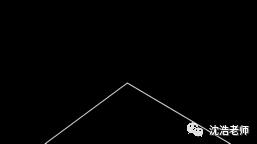
此处跳过而不是使用公式y = mx + b来表示线的部分,即霍夫变换代替使用极坐标/一种角度表示的三角形,使用rho和θ作为两个参数。
这个区别对于我们的理解并不是很重要,因为空间仍然是二维参数化的,逻辑是完全相同的,但是这个三角角度确实有助于表示不完全垂直行的y = mx + b方程。所以一般代码中使用了rho和theta。
最终输出
程序输出两个参数来描述两条车道线。该程序还提供每个车道线的终点的坐标。
车道1号线
斜率:-0.740605727717; 截取:664.075746144
第一点:(475,311)第二点:(960,599)
车道2号线
系数:-0.740605727717; 截取:664.075746144
第一点:(475,311)第二点:(0,664)
在原始图像上叠加这些线,我们看到:已经使用基本的数学运算来有效地识别车道线。

当然实际情况和系统实现要复杂得多,但现在借助云计算和API接口,强大的计算加上辅助识别深度学习算法和AI,可以在非常短的时间计算道路和障碍物,从而实现自动驾驶——大致的原理是这样,玩玩!
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长



欢迎关注:灵动数艺
——数艺智训
欢迎关注:博易智讯(Bizinsight)
——数据艺术家
以上是关于图像识别 | 道路识别的自动驾驶算法基本原理的主要内容,如果未能解决你的问题,请参考以下文章