清华自动化系教授张长水:图像识别有风险
Posted MoPaaS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华自动化系教授张长水:图像识别有风险相关的知识,希望对你有一定的参考价值。
注:后台回复“010”下载完整版PPT。
以下为演讲全文:
大家好,我来自清华大学自动化系,主要做机器学习和图像识别的研究。现在人工智能很流行,机器学习也推到风口浪尖上,图像识别已经变成产品,新闻媒体告诉我们AlphaGo、AlphaGo zero已经战胜了人类、皮肤癌的识别超过了大夫、无人车已经上路测试,很快要量产。这些新闻仿佛告诉我们,图像识别的问题已经解决了,然而很多高科技做图像识别公司都还在高薪聘用掌握机器学习的人才。图像识别问题解决了吗?我们看看现在图像识别还有些什么问题。
01
大量数据和样本
现在做图像识别,要求有大量的数据。什么叫大量的数据?比如下图是业界在做图像识别的数据集,包含很多类别的图像,像飞机、鸟、猫、鹿、狗。对于一个物体,需要有不同的表现,需要有不同的外观在不同的环境下的表现,所以我们需要很多照片素材。

数据集
尽管在我们领域里有很多大的数据集,但其实这些数据集远远不能满足我们的实用产品的要求。比如说我们看这样一个文字识别的例子。文字识别比一般的图像识别要简单,因为文字不涉及到三维,它只是一个平面的东西。
我们要识别清华大学的“清”,通常的做法是收集“清”的各种各样的图像,所谓各种各样的图像就是说要包括不同的字体,不同的光照,不同的背景噪声,不同的倾斜等,要想把“清”字识别好,就需要收集上很多这样的样本。那么这么做得困难是什么?

同一个“清”字的不同变形
02
困难
1、样本的获取
当我们应用于实际、设计产品的时候,就会发现不是每一种情况下都有那么多数据。所以,怎么获得丰富的数据是首要的问题。

不同条件下交通标志
上图给大家展示的这一排图像是一个交通标志的识别任务。我们如果需要去识别路上的交通标志,就要在不同的环境下,不同的光照下,比如说早晨、中午、晚上,逆光还是背光,不同的视角,是否有遮挡,所有的因素都要考虑到,来采集数据。经验上每种标识收集上千张或者更多的图像,才能保证识别率到达实际应用的水平。
我们的问题是什么?看类似连续急转标志这样的图像在城市很难见到,除非到山区。这个例子说明,图像获取本身就不容易。
2、样本的标注
现在的图像识别方法是基于标注的数据的,叫做监督学习。图像标注就意味着把图像一张一张抠出来。如果我们开车穿梭在北京市大街小巷,但是交通标志并不是在视频的每一张图片上出现。如果我们需要把视频中交通标志都要标出来,需要花费很多金钱和精力。
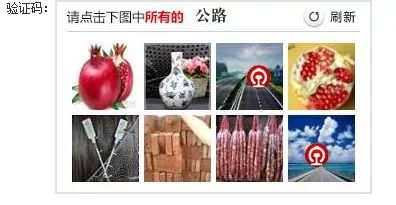
12306安全验证码
做机器学习的人也会关心能不能通过一些更廉价的方法去做数据标注,包括众包这种形式。在12306网站购买火车票,每次让我们勾出相对应的图像,就可以看做是在标注数据。但是众包标注数据也存在一些问题,每个人标注习惯会导致不同的误差。所以我们如何设计学习算法,使得机器学习中,它对错误的标注不敏感,这一问题大概七八年前就开始研究,也不断的有新的文章出现。
那当数据没有那么多的时候,怎么办?机器学习界遇到的另一个问题,就是小样本的数据学习。当样本不多的时候能不能达到和大数据量类似的识别效果?例如上图中只有几张狗的图片的时候,要识别狗,还能从哪里得到狗的信息?思路是从其他的图片中来,比如上边有有鸟,有猫,有鹿,它们的皮毛很像狗等等。换句话说,他从其他的丰富的图像中获取一些信息,把那些信息迁移到这个少量的数据上,从而能够实现对狗的识别。
另外,图片数量是否能降到只有一张?比如清华大学的“清”,只有一个模板图像,是否能够把文字识别做好。更极端的例子,能不能做到一个样本都没有,也就是说,机器在没有见过狗的情况下,是否能把狗识别出来,这都是研究人员关心的事情。
3、大数据量的训练
我们有了大量的数据怎么去做训练?GPU去做训练可以达到特别快的速度,在大的数据量上进行训练和学习叫做Big Learning。Big Learning 关心是否有更快速的方法训练,比如一个月才能训练出来的问题能不能在一天就训练出来?能不能用并行训练?如果数据不能一次存到硬盘里,这个时候怎么学习呢?这些就是企业和机器学习界都关心的事。

熊猫图
除此之外,我们发现深度学习模型很容易被攻击。如上图左边是一只熊猫,我们已经训练好网络能够识别出这是一只熊猫。如果我在这张图像上加了一点点噪声,这个噪声在右图你几乎看不出来,我再把这个叠加后的图像给网络,它识别出来的不是熊猫,是别的东西。而且它以99.3%的信心说这不是熊猫,甚至你可以指定他是任何一个东西。这件事情的风险在什么地方?如果只是娱乐一下,也没什么大关系。但是如果把它用于军事或者金融后果就比较严重了。因此我们一直在关心这个问题怎么解决,就是希望算法能够抗攻击性强一点,但目前只是缓解而没有彻底解决。
而且研究中会发现这个问题,相当于去研究分类器的泛化性能。泛化性能这件事在机器学习里是理论性很强的问题,是机器学习圈子里面非常少的一些人做的事情。换句话说,这个问题看起来很应用,其实它涉及了背后的一些很深理论。为什么会出现这样的情况?因为我们对深度学习这件事没有太好的理论去解释它,我们没有那么好的方法去把所有的问题解决。
识别的错误率问题
我们再说风险,图像识别中我们会把一个学习问题往往形式化一个优化问题,然后去优化这个函数,使这个函数最小。我们把这个函数叫做目标函数。有的时候我们会把这样的函数叫做损失函数,物体识别有错就带来损失。就是说在整个过程我们希望不要有太多的损失。其实,风险函数可能是更合适的词。因为你识别错了,其实是有风险的。一般来说目标函数对应于错误率,把狗识别成猫错了一张,把猫识别成狗又错了一张,都影响错误率,而错误率足以反映算法的性能。
但是在不同的问题里,识别错误的风险是不一样的。比如我们做一个医学上的诊断,本来是正常人,你判别说他有癌症,这种错误就导致虚惊一场。还有一种情况是他患有恶性肿瘤,算法没有识别出来而导致了延误治疗。这样的错误风险就很大。因此我们在优化的时候,这个目标函数其实是应该把这样的决策错误和风险放到里面去,我的目标是优化这个风险。但优化风险又和应用、和我们的产品设计相关。所以不同的产品设计,它的决策风险不一样。所以我们在设计产品的时候,需要考虑。
苹果宣称他们的人脸识别错误率是百万分之一,如果别人来冒充你去用这个手机是百万分之一的可能性,就是说,别人冒充你是很难的;但是人脸识别还有一种错误,就是:我自己用我的手机,没有识别出是我,这个错误率是10%。换句话说,你用十次就会有一次不过。在用手机这个问题上不明显,但是如果用于金融,这个事就有风险。我们设计产品的时候,你就要考虑风险在哪,我们怎么样使得整个风险最小,而不是只考虑其中一边的错误率。
有公司会宣传说错误率可以降到百万分之一,让人误以为人脸识别的问题已经解决了,然而我们在CAPR、ICCA这样的学术会议上仍然能看到怎么去做文字的检测,怎么去做人脸识别的研究。换句话说这件事还没有到那么容易使用的地步。所以我们做图像识别的产品有风险,产品设计要考虑风险,我们做这件事就要考虑用技术的时候,用对地方很重要,用错地方就会很大的风险。
机器学习是一个和应用紧密结合的学科,虽然有很多高大上的公式,其实都是面向应用,希望能解决实际问题。实际应用给我们提出很多需求,图像识别遇到的问题给我们提出了挑战。最后,感谢各位的聆听。


清华大学自动化系教授、博士生导师
张长水,清华-青岛数据科学研究院二维码安全技术研究中心主任,智能技术与系统国家重点实验室学术委员会委员,清华大学自动化系教授、博士生导师,IEEE Fellow 。主要从事机器学习与人工智能、计算机视觉等研究工作。
MoPaaS 源于硅谷、扎根中国, MoPaaS 是中国领先的企业云平台服务提供商。MoPaaS作为企业持续创新平台,提供高效的应用持续交付,云服务的SRE智能化运维,以及灵活的应用场景支持。MoPaaS 有超过四年的PaaS实施和运维经验。特别是MoPaaS以业务场景为主导,提供包括物联网和工业云平台,人工智能实训和创新平台,以及SRE智能化运维平台和服务,以满足制造、能源、交通、金融、运营商、教育和政务等行业用户的业务场景需求。MoPaaS助力企业快捷地实现数字化转型。
MoPaaS 致力于打造全方位开放云服务生态圈,更好的为用户提供丰富灵活的服务。MoPaaS 产品和服务基于自主的专利技术“智能化PaaS云平台系统”,其领先性和竞争力也得到了广泛的认可,特别是国际知名市场调研公司 Forrester 先后将MoPaaS评为中国企业级云平台市场的强劲表现者,并对MoPaaS Docker容器云解决方案给出高度的评价。MoPaaS作为成长型企业成功入选微软加速器(北京)第九期,另外MoPaaS也是阿里云“云合计划”的PaaS和容器云领域的合作伙伴。
以上是关于清华自动化系教授张长水:图像识别有风险的主要内容,如果未能解决你的问题,请参考以下文章