算法集锦(15)|图像识别| 基于深度学习的机器人跟随算法
Posted 决策智能与机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法集锦(15)|图像识别| 基于深度学习的机器人跟随算法相关的知识,希望对你有一定的参考价值。
“跟随”(Follow Me)在机器人领域里表示识别和跟踪目标。
“跟随”功能是许多有关机器人技术的关键,本文的算法可以扩展到很多的应用领域,比如自动驾驶中的高级巡航管控和工业机器人的协同作业。
在本算法中,我们在虚拟环境下训练了一个深度神经网络,用于识别和跟踪目标。本文中,我们设置了一个叫“hero”的人物,并将她混入人群之中。此外,还设计了一个无人机用来跟随“hero”。
应用卷积神经网络进行物体识别有以下两个优点:
参数共享:利用一部分图像训练出来的特征识别器,应用到其他图像时依然有效;
稀疏连接:在每一层网络中,每个输出值仅仅依赖于哪些能使其保持平移不变性的一小部分输入值。
通常,卷积神经网络由卷积层、池化层、全连接层和Softmax层组成,每一层用RELU函数进行激活。
利用卷积网络进行物体识别时,可以对其框架进行些调整,使其能够进行像素级的网络训练,该技术被称作全卷积网络(Fully Convolution Network)。
全卷积网络
全卷积网络可以在训练过程中保留图像的空间信息,这个特点对于物体识别非要有用。换句话讲,全卷积网络可以接受任意个维度的输入。
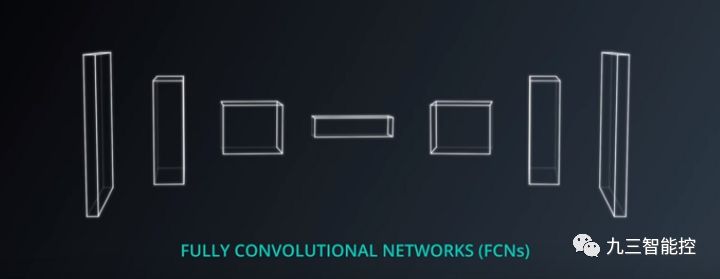
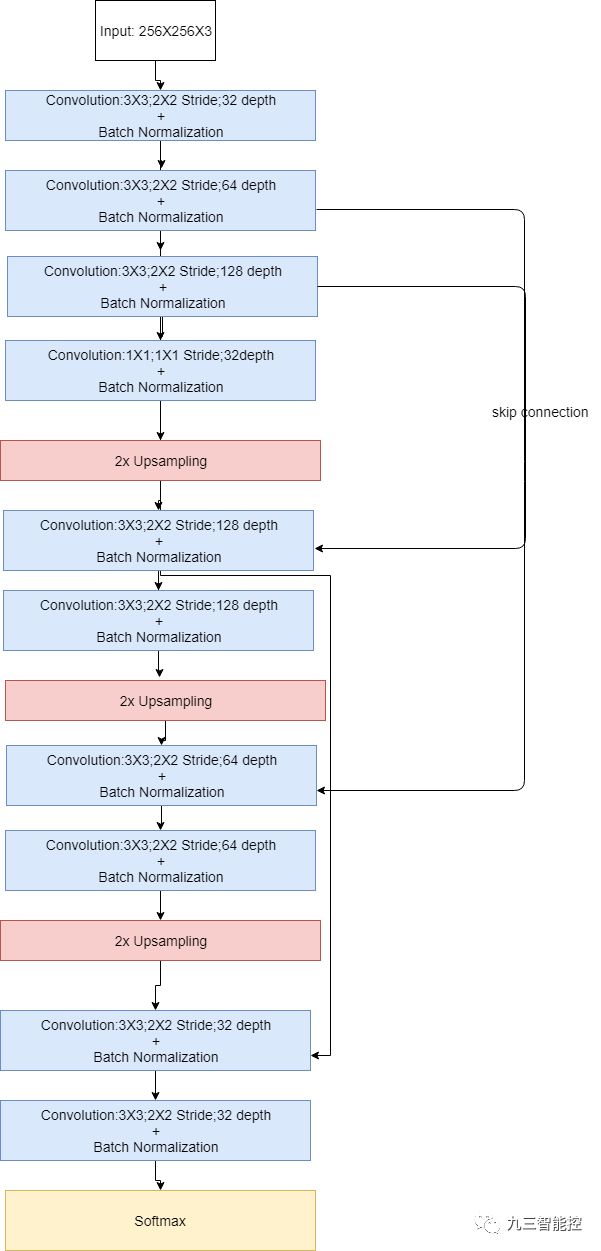
本算法的全卷积网络遵循以下结构:
编码部分(上图中的前三层)
1x1卷积层(上图的第4层)
解码部分(最后3层)
跨层连接
编码部分对应传统的卷积神经网络,其可以通过上采样学习到图像的关键特征,并将其向后传递。通常,通过编码部分就可以实现物体的分割。
接下来是关键的1x1卷积层。1x1的卷积核可以进行降维或者升维,也就是通过控制卷积核(通道数)实现,这个可以帮助减少模型参数,也可以对不同特征进行尺寸的归一化;同时也可以用于不同通道上特征的融合。相比较于传统全连接层,1x1卷积保留了空间信息。
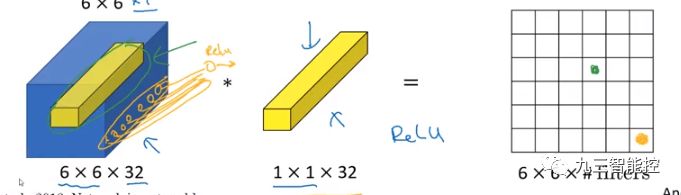
解码部分由双线性插值层(bilinear upsampling layer)、卷积层和批标准化层(batch-normalization)组成。然后利用跨层连接改善损失的空间特征精度。
双线性插值
双线性插值是插值算法中的一种,是线性插值的扩展。利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,其核心思想是在两个方向分别进行一次线性插值。
比如,对于下图的4个已知的像素点,需要将其扩展为4x4的图像,其过程如下。
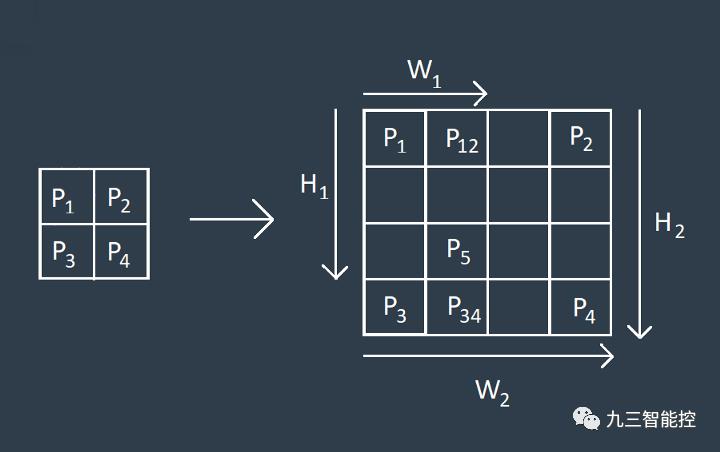
需要指出的是,双线性插值方法不能像转置卷积(transposed convolution)一样创建可学习的层。它会损失一定的细节,但能加快计算的速度。
批标准化
批标准化(Batch-Normalization )简称BN算法,是为了克服神经网络层数加深导致难以训练而诞生的一个算法。根据ICS理论,当训练集的样本数据和目标样本集分布不一致的时候,训练得到的模型无法很好的泛化。
而在神经网络中,每一层的输入在经过层内操作之后必然会导致与原来对应的输入信号分布不同,,并且前层神经网络的增加会被后面的神经网络不对的累积放大。这个问题的一个解决思路就是根据训练样本与目标样本的比例对训练样本进行一个矫正,而BN算法(批标准化)则可以用来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差。
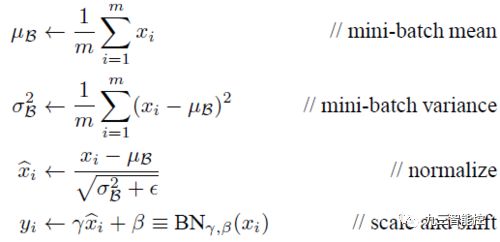
跨层连接
跨层连接(Skip Connection)可以将编码部分的空间信息细节传递给解码部分的卷积层,该方法对于解码部分非常重要,因为上采样过程(双线性插值)并没能恢复图像的全部空间信息。此外,跨层连接技术对于训练ResNet这类的大规模深度网络非常有帮助。
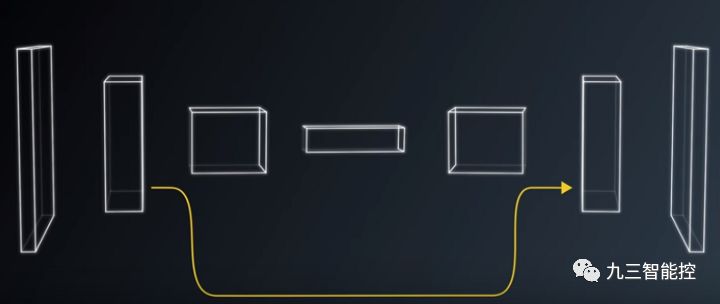
重叠度(IoU)
创建好神经网络框架后,另一个需要解决的问题是:如何来评判我们的物体识别模型的效果?本算法采用重叠度(Inserction Over Union,IoU)来解决该问题。
Intersection over Union是一种测量在特定数据集中检测相应物体准确度的一个标准。我们可以在很多物体检测挑战中,例如PASCAL VOC challenge中看多很多使用该标准的做法。
通常我们在 HOG + Linear SVM object detectors 和 Convolutional Neural Network detectors (R-CNN, Faster R-CNN, YOLO, etc.)中使用该方法检测其性能。注意,这个测量方法和你在任务中使用的物体检测算法没有关系。
IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
1、 ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围);
2、我们的算法得出的结果范围。
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。
如下图:
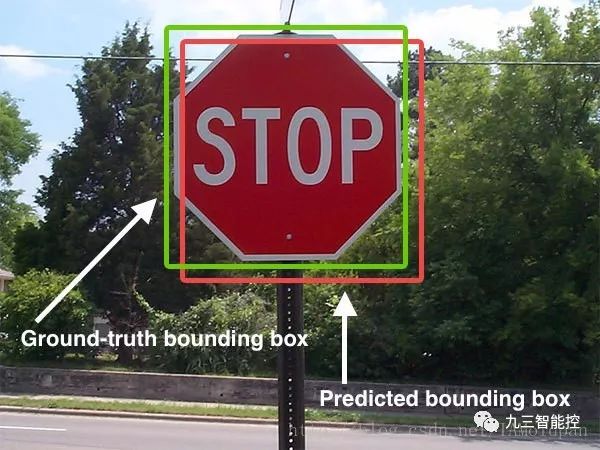
下图展示了ground-truth和predicted的结果,绿色标线是人为标记的正确结果,红色标线是算法预测出来的结果,IoU要做的就是在这两个结果中测量算法的准确度。
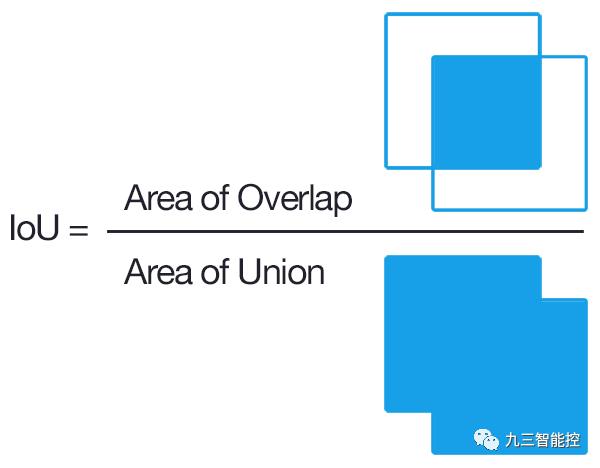
如上图,很简单,IoU相当于两个区域重叠的部分除以两个区域的集合部分得出的结果。
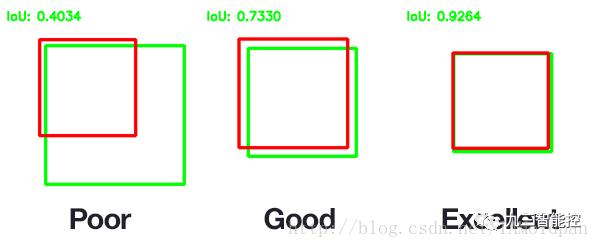
一般来说,这个score > 0.5 就可以被认为一个不错的结果了。
算法结果
本文的算法包括以下三个主要步骤:
从模拟环境中创建图像并进行前处理
创建神经网络模型
训练并评估模型
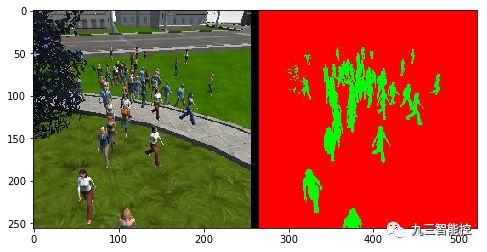
前处理过程将图像由普通模式转换成Binary Mask形式,使其更适于神经网络训练。
最终的神经网络框架如下。
最终的训练结果我们用IoU来评估,本算法的最终结果为0.49。对于物体识别,通常IoU值大于0.5才认为结果是可信的。但本算法是在Udacity环境下进行分析,所以可以将标准阙值将为0.4。
参考资料
https://blog.csdn.net/iamoldpan/article/details/78799857
微信群&交流合作
投稿、交流合作请留言联系。
以上是关于算法集锦(15)|图像识别| 基于深度学习的机器人跟随算法的主要内容,如果未能解决你的问题,请参考以下文章