设计师的AI自学之路:用图像识别玩忍术
Posted 程序猿DD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计师的AI自学之路:用图像识别玩忍术相关的知识,希望对你有一定的参考价值。
来源:人工智能与设计
某日工作室学妹问我,看视频学人工智能好枯燥,有没有实际项目可以实践下?
正巧室友刚做了一个识别剪刀石头布的图像识别程序,于是脑洞大开,改造了一下,做了这个识别结印手势来发动忍术的小游戏。
演示视频:
这里我就把项目整理成教程,让大家都能做脑洞大开的创作。
感谢室友陆玄青提供的简单图像识别源码https://github.com/LuXuanqing/tutorial-image-recognition
改造后的识别手势玩火影忍者忍术源码在这里:
https://github.com/Arthurzhangsheng/NARUTO_game
本项目不要求有人工智能基础,但要有python基础,需要的环境:
tensorflow1.1
keras
opencv
python3
ffmpeg
PIL
pathlib
shutil
imageio
numpy
pygame
一个摄像头
整体流程
下载源码后,用jupyternotebook打开tutorial.ipynb文件,按照里面的教程,一步一步运行,全部运行过后,就得到训练好的能识别手势的神经网络模型文件。运行model文件夹下的predict.py,即可开始试玩。
注意事项
我用的vscode编辑器,把当前工作路径设置为 NARUTO_game 这个主文件夹,并以此设置相关的相对路径,若直接cd到model文件夹来运行predict.py文件,需要手动调整源码中的相对路径。
其实教程具体操作已经全部写在tutorial.ipynb里了,为让大家更直观了解整个操作过程,这里就把tutorial.ipynb里的文字复制搬运到这里来。
Step1 - 采集数据
用手机拍摄视频记录你想要识别的物体。每段视频中只能包含一种物体,时长10~30秒,每个物体可以拍摄多段视频。视频尽量用4:3或1:1的长宽比,分辨率低越好(注意是低)。
进入data/video文件夹,为每种物体(手势)新建一个文件夹,然后把相应的视频导入进去。例如我拍摄了5段关于猫的视频和3段关于狗的视频,就在data/video文件夹下新建dog、cat两个文件夹,然后把把猫的视频全部放进cat文件夹,把狗的视频全部放进dog文件夹,视频的文件名无所谓。
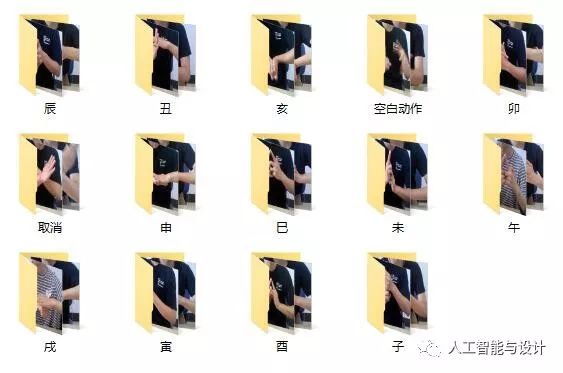
识别结印手势的话我分了14类,12个结印为一类,空白动作为1类,还增加了一个取消动作(虽然这次并没有用到),一共14类。视频文件太大我就没传到github源码上了,大家可以自己用电脑摄像头录一下。
Step2 - 数据处理
在这一步,我们需要把视频转成图片,然后按照60%、20%、20%的比例拆分成训练集(training set)、验证集(validation set)、和测试集(test set)。 为了节省大家时间,我事先已经写好了相关的代码(utils.py),大家只要按照提示进行调用即可完成这一步骤。
import utils#################### 以下是你可以修改的部分 ####################fps = 5 # fps是视频的采样率,即每秒中采集多少张图片,建议设置为5~10# 每张图片的大小,根据你原始视频的比例进行缩放,建议不要超过300x300# 训练所需时间会和图像的像素数量成正比,建议设置得小一点,如160x120width = 160height = 90#################### 以上是你可以修改的部分 ####################utils.process_videos(fps, target_size=(width, height))
Step3 - 数据增强
把一张原始图片经过拉伸、旋转、斜切、反转等操作,可以生产若干新的不同的图片,用以扩充训练集数据量,有助于提高模型的预测准确性。
from keras.preprocessing.image import ImageDataGenerator
from pathlib import Path
# 设置train,val,test的目录
base_dir = Path('data')
train_dir = base_dir/'train'
val_dir = base_dir/'val'
test_dir = base_dir/'test'
# 创建train和val图像生成器,它们会不断地产生出新的图片
#################### 以下是你可以修改的部分 ####################
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=10,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=False,
vertical_flip=True,
fill_mode='nearest')
#################### 以上是你可以修改的部分 ####################
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(height,width))
val_generator = train_datagen.flow_from_directory(val_dir, target_size=(height,width))
# test的时候是模拟真实环境,所以要使用原始图片,不要对图片进行任何操作
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(test_dir, target_size=(height,width))
Step4 - 搭建卷积神经网络
在这一步我们要搭建神经网络的架构。 图像识别的常见方法是通过卷积操作提取图片中的特征,然后将特征输入到神经网络中,最后神经网络输出结果。所以在这一阶段,我们要分别准备卷积和神经网络两个部分。
4.1 - 卷积部分
迁移学习(transfer learning)
对图像进行卷积操作需要耗费大量计算资源,并且训练需要巨大的数据量,一般个人是搞不定这事的。 好消息是人们发现了一个有趣的现象:训练出来用于识别A物体的卷积神经网络,它的卷积部分也能够很好地被用于识别B物体。 所以我们可以把人家已经训练好的NB的卷积神经网络借来用,这就是迁移学习。
载入VGG16
VGG16是一个非常经典的卷积神经网络,16代表有16个层,前13层是卷积层,后3层是全连阶层。我们需要使用它的前13个卷积层,并且使用这些层的权值,用来从图像中提取特征。然后把提取后的特征输入到我们自己的神经网络中进行识别。
import keras as K
# load pretrained model and weights
conv_layers = K.applications.VGG16(include_top=False, input_shape=(height,width,3))
conv_layers.trainable = False
print('per-trained model has been loaded')
4.2 - 神经网络部分
model = K.models.Sequential()
model.add(conv_layers)#载入VGG16的卷积部分
model.add(K.layers.Flatten())#拉平成一维
n_classes = len(utils.get_child_dir_names(base_dir/'video'))
# 以下是你可以修改的部分
model.add(K.layers.Dense(2048, activation='relu'))
model.add(K.layers.Dropout(0.5))
model.add(K.layers.Dense(2048, activation='relu'))
model.add(K.layers.Dropout(0.5))
# 以上是你可以修改的部分
model.add(K.layers.Dense(n_classes, activation='softmax'))
print('以下是神经网络的架构:')
model.summary()
Step5 - 训练及验证
可以尝试选择不同的优化器和优化器参数(Keras文档),好的优化器能让训练结果尽快收敛并获得更高的准确率。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
print('优化器设置完毕')
下面开始训练,为了节省时间只设置了迭代20次。你可以尝试不同迭代次看看它数对最终结果的影响。
n_epochs = 20
n_train_samples = utils.count_jpgs(train_dir)#训练集图片总数
n_val_samples = utils.count_jpgs(val_dir)#val集图片总数
batch_size = 32
history = model.fit_generator(train_generator, steps_per_epoch=n_train_samples/batch_size, epochs=n_epochs,
validation_data=val_generator, validation_steps=n_val_samples/batch_size, verbose=2)
print('训练完毕')
画图看一下训练效果
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(8,4), dpi=100)
plt.plot(range(n_epochs), history.history['acc'], 'c', label='Training Accuracy', aa=True)
plt.plot(range(n_epochs), history.history['val_acc'], 'darkorange', label='Validation Accuracy', aa=True)
plt.legend()
plt.xlabel('epoch')
plt.ylabel('Accuracy')
plt.ylim(0,1)
plt.grid()
plt.show()
怎么看训练的结果好不好 好的情况 总体上来看,train和val的正确率都随着迭代次数增加而上升,并且最后收敛于某一个比较高的数值。 两种不好的情况:
1.欠拟合(under-fitting)
train和val的正确率都比较低。 造成这种情况的原因有很多,常见的有:数据量不够大、神经网络设计得不合理、优化器选择不合理、迭代次数不够。
2.过拟合(over-fitting)
train的正确率很高,但是val正确率很低。 这种情况代表模型的泛化能力不好,它完全适应了训练集的数据(可以接近100%的正确率),但是不适用于验证集的数据。 解决方法是使用在Dense层后追加Dropout层或是在Densse层的选项中设置regularizer。
Step6 - 测试
如果上面的验证结果还不错,那恭喜你就快要成功了! 最后我们用测试集的数据来测试一下。
n_test_samples = utils.count_jpgs(test_dir)
_, test_acc = model.evaluate_generator(test_generator, steps=n_test_samples/batch_size)
print('测试正确率:{}'.format(test_acc))
Step7 - 拍张照,让程序来判断它是什么
拍一张照,上传到 data/x 文件夹中,默认文件名是 myimage.jpg。如果你保存了其它文件名或是其它文件夹,需要修改下方代码中的路径。
先显示一下图片看看对不对
from PIL import Image
path = 'data/test/辰/chen_0.jpg'
img = Image.open(path)
img.show()
让程序来预测试试吧
x = utils.preprocess(img, (width, height))
y = model.predict(x)[0]
class_indices = train_generator.class_indices#获得文件夹名的和类的序号对应的字典
class_indices_reverse={v:k for k,v in class_indices.items()}#反转字典的索引和内容值
utils.show_pred(y,class_indices_reverse)
Optional - 用自己电脑的摄像头做实时预测
先保存训练好的模型文件
model.save('model/NARUTO.h5')
utils.save_confg(class_indices_reverse,input_size=(160,90),fp='model/config.json')
print('保存成功')
然后运行其中model文件夹下的的predict.py即可。
这里有个注意事项:我用的vscode编辑器,把当前工作路径设置为 NARUTO_game 这个主文件夹,并以此设置相关的相对路径,若直接cd到model文件夹来运行predict.py文件,需要手动调整源码中的相对路径
然后predict.py文件里大部分是关于如何根据识别到的图像结果,来做出放音效,放gif特效等操作,就不展开细讲每一步在做什么了,大家可以自己发挥想象力去改造。
用到的一些音效、gif图、字体也都放在源码仓库里了。
# coding=utf-8
from keras import models
import numpy as np
import cv2
import json
import os
from PIL import Image, ImageDraw, ImageFont
import pygame,time
def load_config(fp):
with open(fp,encoding='UTF-8') as f:
config = json.load(f, encoding='UTF-8')
indices = config['indices']
input_size = config['input_size']
return indices, input_size
def decode(preds, indices):
results = []
for pred in preds:
index = pred.argmax()
result = indices[str(index)]
results.append(result)
result = results[0]
return result
def preprocess(arr, input_size):
input_size = tuple(input_size)
# resize
x = cv2.resize(arr, input_size)
# BGR 2 RGB
x = cv2.cvtColor(x, cv2.COLOR_BGR2RGB)
x = np.expand_dims(x, 0).astype('float32')
x /= 255
return x
def put_text_on_img(img,
text='文字信息',
font_size = 50,
start_location = (100, 0),
font_color = (255, 255, 255),
fontfile = 'model/font.ttf'):
'''
读取opencv的图片,并把中文字放到图片上
font_size = 100 #字体大小
start_location = (0, 0) #字体起始位置
font_color = (0, 0, 0) #字体颜色
fontfile = 'model/font.ttf' #字体文件
'''
# cv2读取图片
cv2img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # cv2和PIL中颜色的hex码的储存顺序不同
pilimg = Image.fromarray(cv2img)
# PIL图片上打印汉字
draw = ImageDraw.Draw(pilimg) # 图片上打印
font = ImageFont.truetype(fontfile, font_size, encoding="utf-8") # 参数1:字体文件路径,参数2:字体大小
draw.text(start_location, text, font_color, font=font) # 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体
# PIL图片转cv2 图片
convert_img = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
# cv2.imshow("图片", cv2charimg) # 汉字窗口标题显示乱码
return convert_img
def playBGM():
bgm_path = r'audio/BGM.mp3'
pygame.mixer.init()
pygame.mixer.music.load(bgm_path)
pygame.mixer.music.set_volume(0.2)
pygame.mixer.music.play(loops=-1)
def playsound(action):
sound_path1 = 'audio/test1.wav'
sound_path2 = 'audio/test2.wav'
sound_path3 = 'audio/huituzhuansheng.wav'
sound_path4 = 'audio/yingfenshen.wav'
if action == "寅":
sound1 = pygame.mixer.Sound(sound_path2)
sound1.set_volume(0.3)
sound1.play()
elif action == "申":
sound1 = pygame.mixer.Sound(sound_path1)
sound1.set_volume(0.5)
sound1.play()
elif action == '酉':
sound1 = pygame.mixer.Sound(sound_path3)
sound1.set_volume(1)
sound1.play()
elif action == "丑":
sound1 = pygame.mixer.Sound(sound_path4)
sound1.set_volume(1)
sound1.play()
else:
pass
def add_gif2cap(cap, pngimg):
# I want to put logo on top-left corner, So I create a ROI
rows1,cols1,channels1 = cap.shape
rows,cols,channels = pngimg.shape
roi = cap[(rows1-rows)//2:(rows1-rows)//2+rows, (cols1-cols)//2:(cols1-cols)//2+cols ]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(pngimg,cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 180, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi,roi,mask = mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(pngimg,pngimg,mask = mask)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg,img2_fg)
cap[(rows1-rows)//2:(rows1-rows)//2+rows, (cols1-cols)//2:(cols1-cols)//2+cols] = dst
return cap
def add_gif2cap_with_action(action, cap, png_num):
if action == "寅":
pngpath = 'image/shuilongdan/png/action-%02d.png'%(png_num)
pngimg = cv2.imread(pngpath)
pngimg = cv2.resize(pngimg,None,fx=0.8, fy=0.8, interpolation = cv2.INTER_CUBIC)
cap = add_gif2cap(cap, pngimg)
return cap
else:
return cap
def main():
indices, input_size = load_config('model/config.json')
model = models.load_model('model/NARUTO.h5')
cap = cv2.VideoCapture(0)
counter = 0
counter_temp = 0 #计数器
action = "子"
playBGM()
png_num = 1 #用于计数动画图片序号的变量
while True:
_, frame_img = cap.read()
# predict
x = preprocess(frame_img,input_size)
y = model.predict(x)
action = decode(y,indices)
#播放音效,且每次播放间隔50个帧
counter+=1
if counter == 2:
#触发音效
playsound(action)
counter += 1
if counter == 50:
counter = 0
#显示动作名
frame_img = put_text_on_img(
img= frame_img,
text= "當前動作:"+action,
font_size = 50,
start_location = (0, 100),
font_color = (255, 150, 0)
)
#触发动画
if action == "寅":
frame_img = add_gif2cap_with_action(action, frame_img, png_num)
png_num += 1
if png_num >=37:#水龙弹动画有37帧
png_num=0
#show image
cv2.imshow('webcam', frame_img)
#按Q关闭窗口
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()
if __name__ == '__main__':
main()
# playBGM()
写在最后
我自己代码水平不高,可能引起知乎读者不适,因为编程和AI只是上学期才开始自学的 ಠᴗಠ。
真正的专业是工业设计(〃´-ω・),跟知乎人工智能大神没法比,正在努力学习python和AI中。
- END -
近期热文:
……
深入交流、更多福利
扫码加入我的知识星球
点击“阅读原文”,看本号其他精彩内容
以上是关于设计师的AI自学之路:用图像识别玩忍术的主要内容,如果未能解决你的问题,请参考以下文章