2018之江杯零样本图像识别|助你离278万更近一步的baseline
Posted 天池大数据科研平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018之江杯零样本图像识别|助你离278万更近一步的baseline相关的知识,希望对你有一定的参考价值。
小天说
“本文来自天池优秀选手高小苏,他针对正在进行的2018之江杯全球人工智能大赛
两道赛题:零样本图像目标识别及视频识别&问答,分别整理了两版baseline+注释,发布后已经获得了5000+的浏览,以及170+的fork,小天今天把高小苏同学整理的baseline分享出来,希望能帮助小天的铁杆粉丝们更好的参加比赛哟,毕竟,这可是总奖池有278万的赛事呢!”
高小苏整理的baseline发布在天池Notebook上的效果
以下是高小苏的baseline原文,感兴趣的同学也可以点击阅读原文查看哦!
Baseline原文+注释
零样本作为迁移学习的一个分支,其实就是借助其他领域预学习的关系做一次关系映射,对这道题而言,通用的设计模式如下图所示,两部分输入:
CNN: Input an image and output deep features for the image.
GCN: Input the word embedding for every object class, and output the visual classifier for every object class. Each visual classifier (1-D weight vector) can be applied on the deep features for classification.
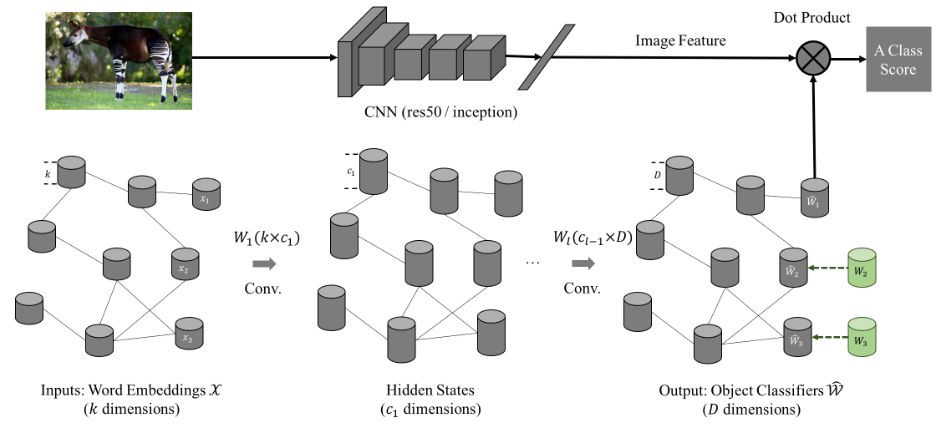
目前声称效果最好的是GCN网络,效果如下:
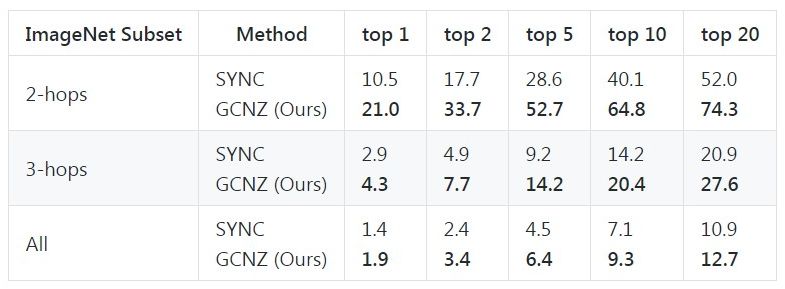
传送门:https://github.com/JudyYe/zero-shot-gcn, 需要注意的是这个模型使用了预训练权重
之江这道题其实格外提供了一个属性表,包括类别、颜色、用途等 其实是降低了难度,那我们可以简单点先做一版 这里baseline仅使用这31维的属性标签做训练,最后对比这31维的向量,用np.linalg.norm计算欧式距离然后从40个新类别中选取最接近的lable 分析这31维的属性其实是分为5个大类若干小类 所以我们用联合训练的方法训练5个分类器出来:
123456789 |
import numpy as npf = open(r'datalab/2217/DatasetA_train_20180813/DatasetA_train_20180813/attributes_per_class.txt')data_per_class = f.readlines()data = []for line in data_per_class: data.append(line.split())print(data) |
1234567891011121314151617181920212223242526272829303132 |
#这里的属性标签其实分为类别、颜色、用途等5类,但是最后一个类别主观太重,估计打标的同学也很为难,我就不用了,还有颜色这个我暂且不用,比如carpancost 这些颜色有点误导吧head = list(['lable', 'animal','transportation','clothes','plant','tableware','device','black','white','blue','brown','orange','red','green','yellow','has_feathers','has_four_legs','has_two_legs','has_two_arms','for_entertainment','for_business','for_communication','for_family','for_office use','for_personal','gorgeous','simple','elegant','cute','pure','naive']) |
123456789101112131415161718192021222324252627 |
#对lable做一次清洗import pandas as pddata = pd.DataFrame(data,columns= head)# data = data.set_index('lable')data_1 = data.loc[:,'animal':'device']data_2 = data.loc[:,'black':'yellow']data_3 = data.loc[:,'has_feathers':'has_two_arms']data_4 = data.loc[:,'for_entertainment':'for_personal']data_1 = (data_1 >= '1') & 1data_1['non_1'] = 1 - data_1.sum(axis = 1)#颜色属性不太好用(比如carpancost),这里就不做复杂处理,模型训练时暂不用data_2 = (data_2 > '0.7') & 1data_2.sum(axis = 1)data_3 = (data_3 >= '1') & 1data_3.sum(axis = 1)data_4 = (data_4 >= '1') & 1data_4.sum(axis = 1)data_new = pd.DataFrame(data['lable'])data_new = pd.DataFrame(np.hstack((data_new, data_1, data_2, data_3, data_4)))data_new.to_csv("test_1.csv", index=None)print("data saved to test_1.csv.") |
output
data saved to test_1.csv.
12345678910111213141516171819202122232425 |
#build modelfrom keras import Model, Sequentialfrom keras.applications import VGG16, VGG19from keras.layers import Flatten, Densefrom keras.preprocessing import imagefrom sklearn.model_selection import train_test_splitbase_model = VGG19(include_top=False, weights=None, input_shape=(64, 64, 3))classes = { 'cla' : 6+1, # 'clo' : 8, #暂且不用 'has' : 4, 'for' : 6 # 'is' : 6 #暂且不用}x = base_model.outputx = Flatten()(x)x = Dense(1024, activation='relu')(x)predictions = [Dense(n, activation='softmax', name=m)(x) for m,n in classes.items()]model = Model(inputs=base_model.input, outputs= predictions)model.compile(optimizer='rmsprop', loss='categorical_crossentropy')model.summary() |
由于微信端代码显示不全,建议同学们点击阅读原文保存网址,然后在PC端查看全文哦!

快点击阅读原文,查看全部baseline!
以上是关于2018之江杯零样本图像识别|助你离278万更近一步的baseline的主要内容,如果未能解决你的问题,请参考以下文章