实现设备上的节能图像识别 — Qualcomm Technologies 的方法
Posted TensorFlow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现设备上的节能图像识别 — Qualcomm Technologies 的方法相关的知识,希望对你有一定的参考价值。
文 / 特邀文章作者,Qualcomm Technologies 的 Chen Feng、Terry Sheng、Jay Zhuo、Zhiyu Liang、Parker Zhang 和 Liang Shen
IEEE LPIRC 挑战赛
低功耗图像识别挑战赛 (LPIRC) 是一年一度的竞赛,主要从准确度、执行时间和能量消耗方面评估计算机视觉技术。今年的竞赛由 Google 和 Facebook 赞助,共分为三个赛道,其中赛道 1 的挑战目标是使用由 Qualcomm Snapdragon 835 移动平台支持的 Pixel 2 智能手机,在 10 分钟的时间限制内处理 20000 张图像,同时最大程度地保证图像分类的准确度。此次竞赛使用大型数据集作为训练数据,其中包含大约 120 万张 JPEG 图像,涵盖 1000 个不同类别,同时使用 Holdout 图像集作为测试数据。
现实世界需要能够在移动设备上实时运行且可准确进行图像分类的神经网络模型,此项公开竞赛正是为此目的而举行。除准确度以外,计算效率对电池供电设备也至关重要。在竞赛中,我们团队将易于量化的 MobileNet V2 架构与先进的量化后方案结合使用,并因绝佳速度和准确度拔得头筹。我们使用每层计算好的最小和最大值插入 FakeQuantization 节点,以修改 TensorFlow 中的图表,并使用 TensorFlow Lite 将图表转化为用于硬件部署的.tflite 文件。
Qualcomm Canada Inc 的团队成员:Parker Zhang、Liang Shen、Chen Feng、Terry Sheng、Jay Zhuo 和 Zhiyu Liang
我们的模型在单个 ARM CPU 上的每次推理中以 28 毫秒识别 20000 张图像时,实现了最高的准确度。
Qualcomm Technologies, Inc. 工程部副总裁 Mickey Aleksic 说:“此次挑战与我们的 AI 战略完美契合,而赢得这次竞赛对于确立 Qualcomm Technologies 在机器学习中的重要地位以及推广设备中的 AI 大有帮助。”
实现设备上的极速图像识别
在边缘设备上准确快速地识别图像需要执行以下步骤:
创建和训练一个神经网络模型,从而以浮点运算对图像进行识别和分类。
将浮点模型转化为定点模型,后者可以在边缘设备上高效运行,而不会出现延迟和准确度问题。
我们团队的模型基于 MobileNet v2 构建,但以 “易于量化” 的方式进行了修改。虽然 Google 的 MobileNet 模型通过使用可分离卷积结构成功缩小了参数大小和计算延时,但直接量化预训练的 MobileNet v2 模型可能会造成准确度下降。我们的团队分析并找出了在此类可分离卷积网络中因量化而降低准确度的根本原因,并在不使用量化感知重新训练的情况下解决了此问题。通过量化感知训练,模型可获得良好的准确度,而我们的方法是一种替代方案,能够修改网络架构以解决量化问题,而无需重新训练。另一种更为端到端的方法是使用 Google 的 ML 框架 Learn2Compress,通过优化多个网络架构和同时使用量化及其他技术(如提炼、剪枝和联合训练),直接从头开始训练高效的设备上模型或现有的 TensorFlow 模型。
注:Learn2Compress 链接
https://ai.googleblog.com/2018/05/custom-on-device-ml-models.html
模型架构
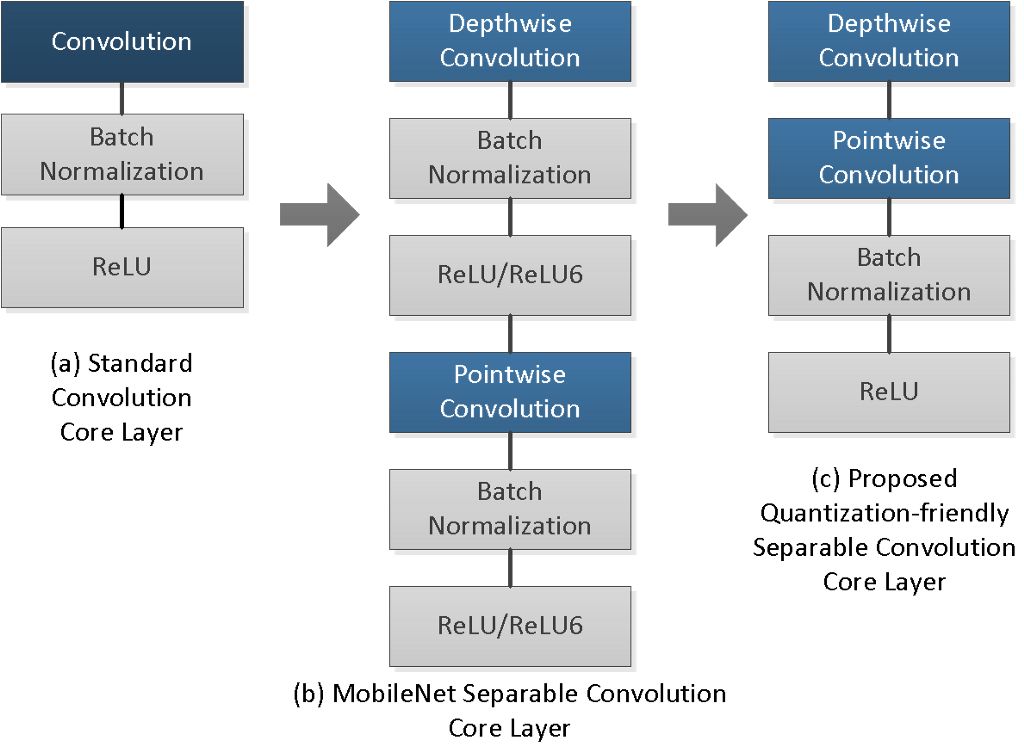
在可分离卷积结构中,我们将深度卷积分别应用于每个通道。但是,用于权重量化的最小和最大值是从所有通道中整体获取的。由于数据范围的扩大,某个通道中的异常值可能会导致整个模型的量化损失。如果未在不同通道中进行数据计算,深度卷积结构可能会在某个通道内产生全零值的权重,而这在 MobileNet v1 和 v2 模型中都很常见。某个通道中的全零值意味着偏差很小。在完成深度卷积后,直接应用批量归一化转换时,预计该特定通道的"缩放"值会较大。这会损害整个模型的表示能力。
我们的团队提出一种易于量化的高效可分离卷积架构作为解决方案,将深度和逐点卷积层之间的非线性操作(批量归一化和 ReLU6)全部移除,让网络学习合适的权重来直接处理批量归一化转换。此外,我们还将所有逐点卷积层中的 ReLU6 替换为 ReLU。在使用 MobileNet v1 和 v2 模型进行的多项试验中,此架构在 8 位量化通道中展示出显著的准确度提升。
量化后技术
定义模型结构后,您便可在数据集上训练浮点模型。在量化后步骤中,我们使用各种不同的输入内容并针对训练数据中各个类别的单张图像运行模型,以收集最小和最大值以及每层输出的数据直方图分布。我们选取最佳 “步长” 和 “偏移” 值(用 ∆ 表示)以用于线性量化,这可以在贪婪搜索期间最大限度地减小量化损失和饱和损失的总量。根据计算出的最小和最大值范围,TensorFlow Lite 提供了将图表模型转化为.tflite 模型的路径,以便在边缘设备上部署模型。
Qualcomm Technologies, Inc 的 Ning Bi(上图右侧中间)代表团队领奖
结论
将计算移至 8 位并保留较高的准确度是在边缘设备上快速高效地运行模型的关键步骤。我们的团队发现了此量化问题,分析并找出其根本原因,然后解决了此问题。之后,我们将这些发现应用于图像分类挑战赛,并看到我们的理论成果变为了现实。您可以在我们发表的论文《适用于 MobileNets 的易于量化可分离卷积架构》(A quantization-friendly separable convolution architecture for MobileNets) 中了解详情 (https://arxiv.org/abs/1803.08607)。
更多 AI 相关阅读:
以上是关于实现设备上的节能图像识别 — Qualcomm Technologies 的方法的主要内容,如果未能解决你的问题,请参考以下文章