卷积学习与图像识别的技术发展
Posted 慧天地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积学习与图像识别的技术发展相关的知识,希望对你有一定的参考价值。
点击图片上方蓝色字体“慧天地”即可订阅
 到了2000年,自20世纪80年代兴起的神经网络热潮已经退去,神经网络再次成为常规科学。托马斯·库恩(Thomas Kuhn)曾将科学革命之间的时间间隔描述为,科学家在一个已经确定的范式或解释框架内进行理论推定、观察和试验的常规工作阶段。1987 年,杰弗里·辛顿去了多伦多大学,并继续着渐进式改进,虽然这些改进都没有像曾经的玻尔兹曼机那样展现出魔力。辛顿在21 世纪头十年成为加拿大高等研究院(Canadian Institute for Advanced Research,简称 CIFAR)神经计算和自适应感知项目(Neural Computation andAdaptive Perception,简称 NCAP)的带头人。该项目由来自加拿大和其他国家的约 25 位研究人员组成,专注于解决机器学习的难题。我是由杨立昆担任主席的 NCAP 顾问委员会的成员,会在每年 NIPS 会议召开之前参加该项目的年会。神经网络的先驱们在缓慢而稳定的过程中探索了机器学习的许多新策略。虽然他们的网络有许多有价值的应用,但却一直没有满足 20 世纪 80 年代对该领域抱有的很高的期望。不过这并没有动摇先驱者们的信念。回想起来,他们一直是在为飞跃性的突破奠定基础。
到了2000年,自20世纪80年代兴起的神经网络热潮已经退去,神经网络再次成为常规科学。托马斯·库恩(Thomas Kuhn)曾将科学革命之间的时间间隔描述为,科学家在一个已经确定的范式或解释框架内进行理论推定、观察和试验的常规工作阶段。1987 年,杰弗里·辛顿去了多伦多大学,并继续着渐进式改进,虽然这些改进都没有像曾经的玻尔兹曼机那样展现出魔力。辛顿在21 世纪头十年成为加拿大高等研究院(Canadian Institute for Advanced Research,简称 CIFAR)神经计算和自适应感知项目(Neural Computation andAdaptive Perception,简称 NCAP)的带头人。该项目由来自加拿大和其他国家的约 25 位研究人员组成,专注于解决机器学习的难题。我是由杨立昆担任主席的 NCAP 顾问委员会的成员,会在每年 NIPS 会议召开之前参加该项目的年会。神经网络的先驱们在缓慢而稳定的过程中探索了机器学习的许多新策略。虽然他们的网络有许多有价值的应用,但却一直没有满足 20 世纪 80 年代对该领域抱有的很高的期望。不过这并没有动摇先驱者们的信念。回想起来,他们一直是在为飞跃性的突破奠定基础。
机器学习的稳步发展
NIPS 会议是 20 世纪 80 年代神经网络的孵化器,为其他可处理大型高维数据集的算法打开了大门。弗拉基米尔·瓦普尼克的支持向量机于1995 年引发了轰动,为 20 世纪 60 年代就被遗弃的感知器网络开辟了一个新篇章。使支持向量机成为功能强大的分类器,并出现在每个神经网络工作者工具包中的,是“内核技巧”(kernel trick),这是一种数学转换,相当于将数据从其采样空间重新映射到使其更容易被分离的超空间。托马索·波吉奥开发了一种名为“HMAX”的分级网络,可以对有限数量的对象进行分类。这表明,网络的性能会随着其深度的增加而提高。
在21 世纪的头几年里,图形模型被开发出来,并与被称为“贝叶斯网络”(Bayes networks)的丰富的概率模型相结合,后者是基于18 世纪英国数学家托马斯·贝叶斯(Thomas Bayes)提出的一个定理,该定理允许使用新的证据来更新先前的信念。加州大学洛杉矶分校的朱迪亚·珀尔,在早些时候曾将基于贝叶斯分析的“信念网络”(belief networks)引入人工智能,通过开发能够利用数据在网络中学习概率的方法, 对贝叶斯分析进行了加强和扩展。这些网络以及其他网络的算法为机器学习研究人员打造出了强大的工具。
随着计算机的处理能力继续呈指数增长,训练更大规模的网络成为可能。大家曾普遍认为,具有更多隐藏单元、更宽的神经网络,比具有更多层数、更深的网络的效果更好,但是对于逐层训练的网络来说并非如此,并且误差梯度的消失问题(the vanishing error gradient problem)被发现减慢了输入层附近的学习速度。然而,当这个问题最终被克服的时候,我们已经可以对深度反向传播网络进行训练了,而且该网络在基准测试中表现得更好。随着深度反向传播网络开始在计算机视觉领域挑战传统方法,2012 年的NIPS 大会上出现了这样一句话:“神经信息处理系统”里的“神经”又回来了。
在20 世纪的最后10 年以及21 世纪前10 年的计算机视觉领域,在识别图像中的对象方面取得的稳步进展,使得基准测试(用于比较不同方法)的性能每年能提高百分之零点几。方法改进的速度十分缓慢,这是因为每个新类别的对象,都需要有关专家对能够将它们与其他对象区分开来所需的与姿态无关的特征进行甄别。随后,在 2012年,杰弗里·辛顿和他的两名学生艾力克斯·克里泽夫斯基(Alex Krizhevsky)和伊利娅·苏特斯科娃向 NIPS 会议提交了一篇论文,关于使用深度学习训练 AlexNet 识别图像中的对象,AlexNet 是本章要重点讨论的深度卷积网络。以拥有22 000 多个类别,超过1 500 万个标记过的高分辨率图像的 ImageNet 数据库作为基准,AlexNet 史无前例地将识别错误率降低到了18%。这次性能上的飞跃在计算机视觉社区中掀起了一股冲击波,加速推动了更大规模网络的发展,现在这些网络几乎已经达到了人类的水平。到 2015 年,ImageNet 数据库的错误率已降至 3.6%。当时还在微软研究院的何恺明及其同事使用的低错误率深度学习网络,在许多方面都与视觉皮层十分相似;这类网络由杨立昆最早提出,并最初把它命名为“Le Net”。

图9-1 杰弗里·辛顿和杨立昆是深度学习领域的大师。这张照片是 2000 年左右在加拿大高等研究院的神经计算和自适应感知项目会议上拍摄的,该项目是深度学习领域的孵化器。图片来源:杰弗里·辛顿。
卷积网络的渐进式改进
杨立昆在2003 年去了纽约大学后,仍继续开发他的视觉网络,现在被称为卷积网络(ConvNet)(见图9–2)。这个网络的基本结构是基于卷积的,卷积可以被想象成一个小的滑动滤波器,在滑过整张图像的过程中创建一个特征层。例如,过滤器可以是一个定向边缘检测器,就像第5 章中介绍的那样,只有当窗口对准图像中具有正确方向或纹理的对象的边缘时,才会产生大数值输出。尽管第一层上的窗口只是图像中的一小块区域,但由于可以有多个滤波器,因此在每个图块中都能得到许多特征信息。第一层中与图像卷积的滤波器,与大卫·休伯尔和托斯坦·威泽尔在初级视觉皮层中发现的“简单细胞”类似(见图9–3)。更高层次的滤波器则对更复杂的特征做出响应。在卷积网络的早期版本中,每个滤波器的输出都要通过一个非线性的Sigmoid 函数(输出从 0 平稳地增加到 1),这样可以抑制弱激活单元的输出(见方框7.2 中的Sigmoid 函数)。第二层接收来自第一层的输入,第二层的窗口覆盖了更大的视野区域,这样经过多层之后,就会存在一些能接收整个图像输入的单元。这个最顶层就类似于视觉层级的顶层,在灵长类动物中被称为“下颞叶皮层”,并且具有覆盖大部分视野的感受野。接着,顶层的单元被送入分类层,与其中的所有分类单元连接,再采用反向传播误差的方式训练整个网络,对图像中的对象进行分类。
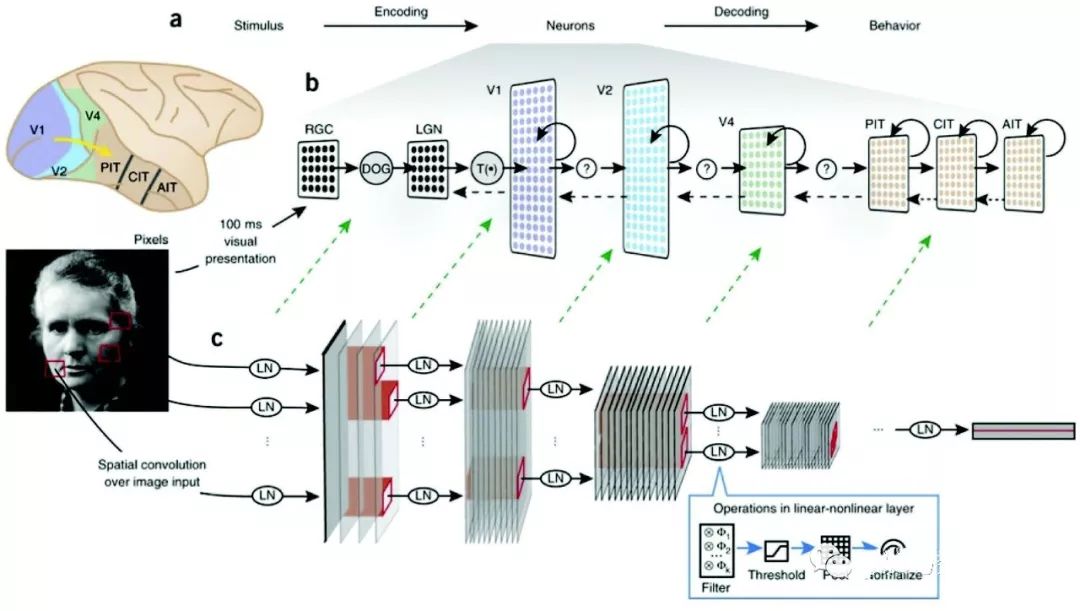
图9-2 视觉皮层与卷积网络在图像对象识别上的比较。(上图)(a,b)视觉皮层中的层级结构,从视网膜输入到初级视觉皮层(V 1),经过丘脑(RGC, LGN)到下颞叶皮层(PIT,CIT,AIT),展示了视觉皮层区域和卷积网络中层次的对应关系。(下图)(c)左侧图像作为输入映射到第一个卷积层,后者由几个特征平面组成,每个特征平面代表一个滤波器,类似在视觉皮层中发现的定向简单单元。这些滤波器的输出经过阈值处理并汇集到第一层,再进行归一化处理,以便在小块区域中产生不变的响应,类似于视觉皮层中的复杂细胞(图中方框:线性—非线性层中的操作)。以上操作在网络的每个卷积层上重复。输出层与来自上一个卷积层的全部输入具有全面的连接(每个输出单元都有上一层全部单元的输入)。图片来源: Yamins and DiCarlo,“Using Goal-Driven Deep Learning Models to Understand Sensory Cortex”,figure 1。

图9-3 卷积网络第一层的滤波器。每个滤波器都作用于视野中的一小块图像区域。顶部三排中滤波器的优选刺激像视觉皮层中的简单细胞一样具有定向性。底部三排显示的优选刺激经过了扩展,并具有复杂的形状。图片来源:Krizhevsky, Sutskever and Hinton,“ImageNet Classication with Deep Convolutional Neural Networks”,figure 3。
卷积网络多年来一直在经历许多渐进式改进。一个重要的补充,是将一个区域上的每个特征聚合起来,叫作“池化”(pooling)。这种操作提供了一种平移不变性(translation invariance)的量度,类似于由休伯尔和威泽尔在初级视觉皮层中发现的复杂细胞,能够通过一个图块对整个视野中相同方向的线做出响应。另一个有用的操作是增益归一化(gain normalization),就是调整输入的放大倍数,使每个单元都在其操作范围内工作,在皮层中是通过反馈抑制(feedback inhibition)实现的。Sigmoid 输出函数也被线性整流函数(rectified linear units,简称ReLUs)取代。在输入达到一个阈值之前这些单元的输出都为零,超过阈值之后则输出和输入呈线性增长。该操作的优点在于:低于阈值的单元被有效地排除在网络外, 这更接近真实神经元中阈值的作用。
卷积网络的每一个性能的改进,其背后都有一个工程师可以理解的计算理由。但有了这些变化,它越来越接近 20 世纪 60 年代我们所了解的视觉皮层的体系结构,尽管当时我们只能去猜测简单和复杂单元的功能是什么,或者层级结构顶部的分布式表征的存在意味着什么。这说明了生物学与深度学习之间存在相得益彰的共生关系的潜力。
当深度学习遇到视觉层级结构
加州大学圣迭戈分校的帕特里夏·丘奇兰德不仅是心灵哲学家,同时也研究神经哲学。知识最终取决于大脑如何表达知识的说法,显然没有人阻止哲学家认为知识是独立于世界而存在的一种东西,用伊曼努尔·康德(Immanuel Kant)的话来说,就是“Ding an sich”(物自身)。但同样清楚的是,如果我们(和其他动物一样)要在现实世界中生存,背景知识就是必不可少的。经过训练的多层神经网络的隐藏单元之间的活动模式,与被逐次记录下的大量生物神经之间的活动模式存在显著的相似性。受到这种相似性的驱动,帕特里夏和我在1992 年编写了《计算脑》(The Computational Brain)一书,为基于大量神经元的神经科学研究开发了一个概念框架。(该书现在已经出到第二版了,如果你想更多地了解大脑式的运算,这会是一本很好的入门参考。)麻省理工学院的詹姆斯·狄卡罗(James DiCarlo)最近比较了猴子视觉皮层层级结构中不同神经元和深度学习神经网络中的单元,训练它们识别相同图片中的对象,分别观察它们的响应(见图9–2)。他得出结论:深度学习网络中每层神经元的统计特性,与皮层层级结构中神经元的统计特性非常接近。
深度学习网络中的单元与猴子视觉皮层中神经元性能存在相似性,但其原因仍然有待研究,尤其是考虑到猴子的大脑不太可能使用反向传播方式来进行学习。反向传播需要将详细的错误信号反馈给神经网络每层中的每个神经元,其精度比生物神经网络中已知反馈连接的精度要高得多。但其他学习算法在生物学上似乎更合理,例如玻尔兹曼机学习算法,该算法使用了已经在皮层中被发现的赫布突触可塑性。这引出了一个有趣的问题,是否存在一种深度学习的数学理论,能够适用于一大类学习算法(包括皮层中的那些)呢?在第7 章中,我提到了对视觉层级结构的上层分类表面的分析,其决策表面比更低层级的表面更平坦。对决策表面的几何分析可能会引出对深度学习网络和大脑更深入的数学理解。
深度学习神经网络的一个优点是,我们可以从网络中的每个单元提取“记录”,并追踪信息流从一层到另一层的转变。然后可以将分析这种网络的策略用于分析大脑中的神经元。关于技术的一个奇妙之处在于,技术背后通常都有一个很好的解释,并且有强烈的动机来得到这种解释。第一台蒸汽发动机是由工程师根据他们的直觉建造的;解释发动机如何工作的热力学理论随后出现,并且帮助提升了发动机的效率。物理学家和数学家对深度学习网络的分析也正在顺利进行着。
有工作记忆的神经网络
传统的前馈网络将输入传到网络中,一次传播一层网络。结合工作记忆,可以使后续的输入与之前的输入在网络中留下的痕迹进行交互。例如,把法语句子翻译成英文时,网络中的第一个法语单词会影响后续英语单词的顺序。在网络中实现工作记忆的最简单方法,是添加人类皮层中常见的循环连接。神经网络中某一层内的循环连接和之前那些层的反馈连接,使得输入的时间序列可以在时间上整合起来。
这种网络在 20 世纪 80 年代被探索并广泛应用于语音识别。在实践中,它在具有短程依赖性的输入方面效果很好,但当输入之间的时间间隔很长,输入的影响会随着时间的推移发生衰减,网络性能就会变差。1997 年,赛普·霍克莱特(Sepp Hochreiter)和尤尔根·施密德胡博(Jürgen Schmidhuber)找到了一种方法来克服衰变问题,他们称之为“长短期记忆”(long short-term memory,简称 LSTM)。默认情况下,长短期记忆会传递原始信息,而不会发生衰减(这就是猴子前额叶皮层的延迟期中发生的事情),并且它也有一个复杂的方案来决定如何将新的输入信息与旧信息整合。于是,远程依赖关系可以被选择性地保留。神经网络中这种工作记忆版本沉寂了长达 20 年之久,直到它在深度学习网络中再次被唤醒和实现。长短期记忆和深度学习的结合在许多依赖输入输出序列的领域都取得了令人瞩目的成功,例如电影、音乐、 动作和语言。
施密德胡博是位于瑞士南部提契诺州(Ticino)曼诺小镇的 Dalle Molle 人工智能研究所的联合主任。该小镇靠近阿尔卑斯山,周围有一些绝佳的徒步地点。神经网络领域的这位颇具创造性、特立独行的“罗德尼·丹泽菲尔德”相信他的创造力并没有得到足够的赞誉。
因此,在蒙特利尔举办的 2015 年NIPS 会议的一次小组讨论会上,他再次向与会人员介绍了自己,“我,施密德胡博,又回来了”。而在巴塞罗那举行的 2016 年 NIPS 大会上,他因培训宣讲人没有对自己的想法给予足够的关注,而打乱对方的演讲长达 5 分钟。
2015 年,Kelvin Xu 及其同事在用一个深度学习网络识别图像中对象的同时, 还连接了一个长短期记忆循环网络来标注图片。使用来自深度学习网络第一遍识别的场景中所有对象作为输入,他们训练长短期记忆循环网络输出一串英文单词,能够形容一个标注中的场景(见图9–4)。他们还训练了长短期记忆网络来识别图像中的位置,使其对应于标注中的每个单词。该应用令人印象深刻的地方在于,长短期记忆网络从未被训练来理解标注中句子的含义,只是根据图像中的对象及其位置输出一个语法正确的单词串。通过分析长短期记忆网络也许会引出一种新的语言理论,它将阐明网络的工作原理和自然语言的性质。

图 9-4 深度学习为图片做标注。顶部的一组图片说明了分析照片的步骤。ConvNet( CNN)在第一步中标记了照片中的对象,并将其传递给循环神经网络(RNN)。RNN 被训练输出适当的英文单词串。底部的四组图片则阐明了进一步细化的过程,即使用注意力(白色云)来表示照片中单词的指示对象。顶图来源:M. I. Jordan and T. M. Mitchell,“Machine learning: Trends, Perspectives, and Prospects,”Science 349 , no. 6245 (2015): 255–260, 图 2. 底图来源:Xu et al.,“ Show, Attend and Tell,”2015, rev. 2016, figure1 and 3,https://arxiv.org/pdf/ 1502 . 03044 .pdf, Coutesy of Kelvin Xu。
生成式对抗网络
在第7章中,玻尔兹曼机被当作一个生成模型进行了介绍,当输出被钳制到一个它已训练识别的类型中,并且其活动模式向下渗透到输入层时,就可以产生新的输入样本。伊恩·古德费洛(Ian Goodfellow)、约书亚·本吉奥(Yoshua Bengio)和他们在蒙特利尔大学的同事们表示,可以训练前馈网络,在对抗的背景(adversarial context)下生成更好的样本。一个生成卷积网络可以通过尝试欺骗另一个卷积神经网络来训练生成优质的图像样本,后者必须决定一个输入的图像是真实的还是虚假的。生成网络的输出被用来作为一个经过训练的判别卷积网络(discriminative convolutional network)的输入,后者只给出一个单一的输出:如果输入是真实图像,就返回 1,否则返回0。这两个网络会相互竞争。生成网络试图增加判别网络的错误率,而判别网络则试图降低自身的错误率。由这两个目标之间的紧张关系产生的图像,拥有令人难以置信的照片级的真实感(见图9–5)。

图9-5 生成式对抗网络(GAN)。顶部的示意图展示了一个卷积网络,用于生成一组样本图像,经过训练后可以欺骗判别卷积网络。左边的输入是 100 维的随机选取的连续值向量,用来生成不同的图像;输入的向量随后激活空间尺度逐层变大的滤波器层。下方的图显示了通过训练来自单个类别照片的生成式对抗网络产生的样本图像。顶图来源:A. Radford, L. Metz, and S. Chintala,“ Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,”图1, arXiv: 1511 .06434 , https://arxiv.org/pdf/ 1511 . 06434 .pdf ,由Soumiyh Chintala 提供;底图来源:A. Nguyen, J. Yosinski, Y. Bengio, A.Dosovitskiy, and J. Clune,“ Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space,” figure 1 , https: //arxiv.org/pdf/ 1612 . 00005 .pdf, 由Ahn Nguyen 提供。
别忘了,这些生成的图像是合成的,它们中的对象并不存在。它们是训练集中未标记图像的泛化版本。请注意,生成式对抗网络是无监督的,这使得它们可以使用无限的数据。这些网络还有许多其他应用,包括清除具有超高分辨率的星系天文图片中的噪声,以及学习表达富有情感的言语。

图9-6 生成式对抗网络中的向量算法。用面部图片训练的生成式网络的输入混合后,产生了输出(左图),然后通过添加或减去选定的输入向量进行输出,就创建出了混合后的图像(右图)。因为混合是在最高的表征层完成的,所以部位和姿势是无缝接合的,并不会经过变形过程中那样的平均处理。图像改编自:A. Radford, L.Metz, and S. Chintala,“ Unsupervised Representation Learning with Deep Convolutional GenerativeAdversarial Networks,” fifigure 7,arXiv: 1511 . 06434 ,https://arxiv.org/pdf/ 1511 . 06434 /。
通过慢慢地改变生成式网络的输入向量,有可能逐渐改变图像,使得部件或零碎物品(如窗户)逐渐显现或变成其他物体(如橱柜)。更值得关注的是,有可能通过添加和减去表示网络状态的向量以获得图像中对象的混合效果,如图9–6 所示。这些实验的意义在于,生成网络对图像中空间的表征,正如我们如何描述场景的各个组成部分。这项技术正在迅速发展,其下一个前沿领域是生成逼真的电影。通过训练一个反复演绎的生成式对抗网络,与类似玛丽莲·梦露这样的演员参演的电影进行对比,应该有可能创造出已过世的演员出演的新作品。

图9-7 2018 年米兰的乔治·阿玛尼春夏男装秀。
这是米兰的时装周,衣着光鲜的模特们带着超凡脱俗的表情在T台上走秀(见图9–7)。时尚界正在经历暗潮涌动:“‘很多工作正在消失,’西尔维娅·文图里尼·芬迪(Silvia Venturini Fendi)在她的时装秀开场前说道,‘机器人会承担旧的工作,但它们唯一无法取代的就是我们的创造力和思维。’”现在想象一下经过训练的新一代对抗网络, 它们可以生产新款式和高级时装,式样几乎无穷无尽。时尚界可能正处于一个新时代的边缘,而许多其他依赖创意的行业也面临着相同的处境。
应对现实社会的复杂性
当前的大多数学习算法是在 25 年前开发的,为什么它们需要那么长的时间才能对现实世界产生影响呢? 20 世纪 80 年代的研究人员使用的计算机和标记数据,只能证明玩具问题的原理。尽管取得了一些似乎颇有前景的成果,但我们并不知道网络学习及其性能如何随着单元和连接数量的增加而增强,以适应现实世界问题的复杂性。人工智能中的大多数算法缩放性很差,从未跳出解决玩具级别问题的范畴。我们现在知道,神经网络学习的缩放性很好,随着网络规模和层数的不断增加,其性能也在不断增强。特别是反向传播技术,它的缩放性非常好。
我们应该对此感到惊讶吗?大脑皮层是哺乳动物的一项发明,在灵长类动物,尤其是人类中得到了高度发展。随着它的扩展,更多的功能慢慢出现,并且更多层次被添加到了关联区域,以实现更高阶的表征。很少有复杂系统可以实现如此高级的缩放。互联网是为数不多的已经被扩大了100 万倍的工程系统之一。一旦通信数据包协议建立起来,互联网就会开始进化,正如DNA 中的遗传密码使细胞演化成为可能一样。
使用相同的一组数据训练许多深度学习网络,会导致生成大量不同的网络,它们都具有大致相同的平均性能水平。我们想知道的是,所有这些同等优秀的网络有哪些共同之处,而对单个网络进行分析并不能揭示这一点。理解深度学习原理的另一种方法是进一步探索学习算法的空间;我们只在所有学习算法的空间中对几个位置进行了抽样尝试。从更广泛的探索中可能会出现一种学习计算理论,该理论与其他科学领域的理论一样深奥,可能为从自然界中发现的学习算法提供更多的解释。
蒙特利尔大学的约书亚·本吉奥(见图9–8),和杨立昆一起,接替杰弗里·辛顿, 成为CIFAR 神经计算和NCAP 项目的主任,该项目在通过十年评估后更名为“机器学习和大脑学习”项目(Learning in Machines and Brains)。约书亚率领蒙特利尔大学的一个团队,致力于应用深度学习来处理自然语言,这将成为“机器学习和大脑学习” 项目新的研究重点。在十多年的会议中,这个由20 多名教师和研究员组成的小组开启了深度学习的研究。过去5 年来,深度学习在过去难以解决的许多问题上取得了实质性进展,这些进展归功于小组成员的努力,他们当然只是一个更庞大社区中的一小部分人。

图9-8 约书亚·本吉奥是 CIFAR“机器学习和大脑学习”项目的联合主任。这位在法国出生的加拿大籍计算机科学家,一直是应用深度学习处理自然语言问题这个领域的领导者。杰弗里·辛顿、杨立昆和约书亚·本吉奥所取得的进展,为深度学习的成功奠定了基础。图片来源:约书亚·本吉奥。
尽管深度学习网络的能力已经在许多应用中得到了证明,但如果单靠自身,它们在现实世界中永远都无法存活下来。29 它们受到了研究者的青睐,后者为其提供数据,调整超参数,例如学习速度、层数和每层中的单元数量,以改善收敛效果,还为其提供了大量计算资源。另一方面,如果没有大脑和身体的其他部分提供支持和自主权,大脑皮层也无法在现实世界中存活。在一个不确定的世界中,这种支持和自主权是一个比模式识别更难解决的问题。
来源:算法与数学之美(版权归原作者及刊载媒体所有)
欢迎大家关注《慧天地》同名新浪微博
微博ID:慧天地_geomaticser

荐读
点击下文标题即可阅读
编辑 / 王兆喆 审核 / 张艺洪 孙浩南
指导:万剑华教授
以上是关于卷积学习与图像识别的技术发展的主要内容,如果未能解决你的问题,请参考以下文章