图像识别零基础?手把手带你打造一个小狗分类器!
Posted 简说Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别零基础?手把手带你打造一个小狗分类器!相关的知识,希望对你有一定的参考价值。
福利干货,第一时间送达!
阅读文本大概需要 9 分钟。
项目介绍
用“房子的尺寸”预测“房子的价格”
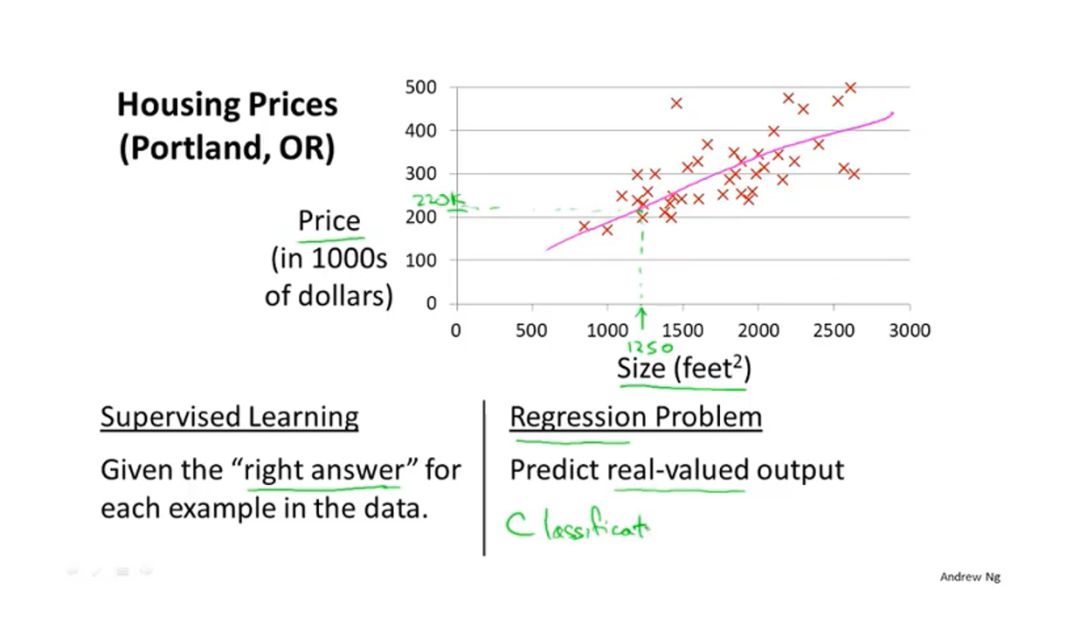
X-房子的尺寸(小狗的图片)
Y-房子的价格(小狗的类别)
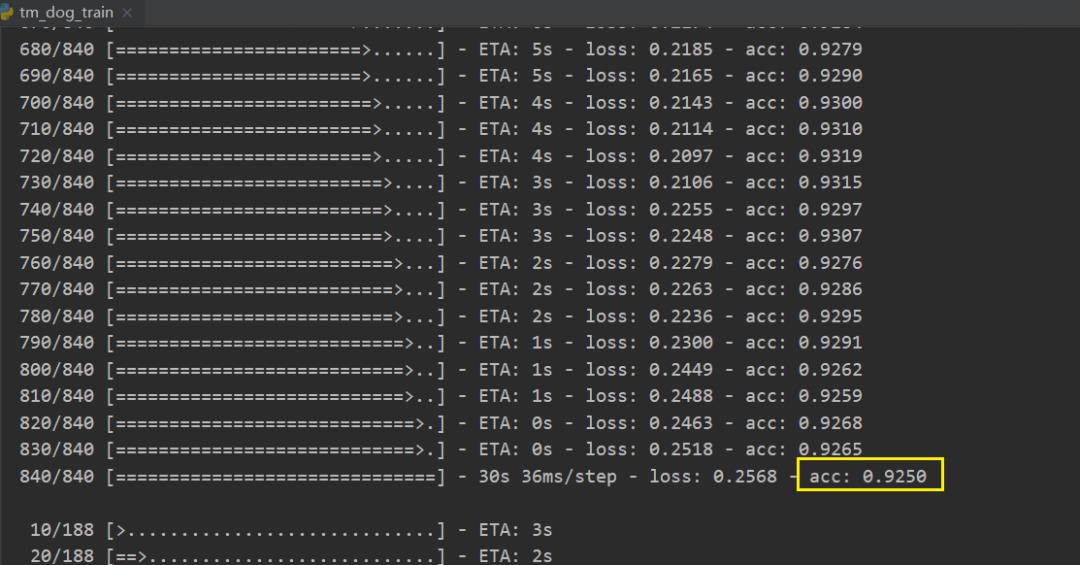
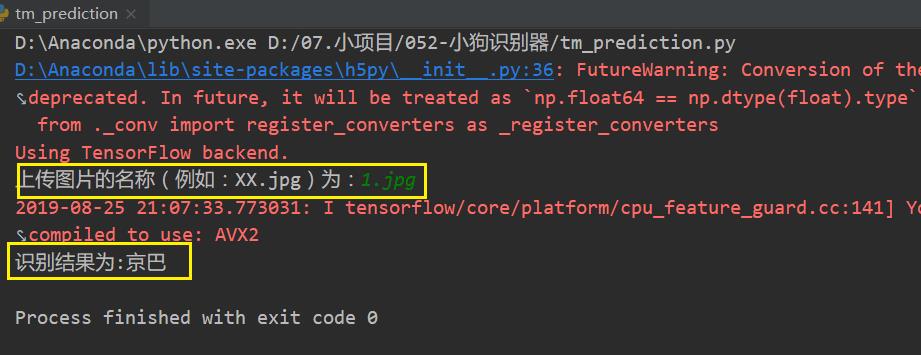
效果展示
编写思路
# 统一尺寸的核心代码
img = Image.open(img_path)
new_img = img.resize((100, 100), Image.BILINEAR)
new_img.save(os.path.join(
'./dog_kinds_after/' + dog_name, jpgfile))
kind =
0
# 遍历京巴的文件夹
images = os.listdir(images_path)
for name
in images:
image_path = images_path +
'/'
os.rename(image_path + name, image_path + str(kind) +
'_' + name.split(
'.')[
0]+
'.jpg')
# 只放了训练集的代码,测试集一样操作。
ima_train = os.listdir(
'./train')
# 图片其实就是一个矩阵(每一个像素都是0-255之间的数)(100*100*3)
# 1.把图片转换为矩阵
def read_train_image(filename):
img = Image.open(
'./train/'
+ filename).convert(
'RGB'
)
return
np.array(img)
x_train = []
# 2.把所有的图片矩阵放在一个列表里 (840, 100, 100, 3)
for
i
in
ima_train:
x_train.append(read_train_image(i))
x_train = np.array(x_train)
# 3.提取kind类别作为标签
y_train = []
for
filename
in
ima_train:
y_train.append(int(filename.split(
'_'
)[
0
]))
# 标签(0/1/2/3)(840,)
y_train = np.array(y_train)
# 我是因为重命名图片为(1/2/3/4),所以都减了1
# 为了能够转化为独热矩阵
y_train = y_train -
1
# 4.把标签转换为独热矩阵
# 将类别信息转换为独热码的形式(独热码有利于神经网络的训练)
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
print(y_test)
x_train = x_train.astype(
'float32'
)
x_test = x_test.astype(
'float32'
)
x_train /=
255
x_test /=
255
print(x_train.shape)
# (840, 100, 100, 3)
print(y_train.shape)
# (840,)
3 搭建卷积神经网络
# 1.搭建模型
(类似于VGG,直接拿来用就行)
model = Sequential()
# 这里搭建的卷积层共有32个卷积核,卷积核大小为3*3,采用relu的激活方式。
# input_shape,字面意思就是输入数据的维度。
#这里使用序贯模型,比较容易理解
#序贯模型就像搭积木一样,将神经网络一层一层往上搭上去
model.add(Conv2D(
32, (
3,
3), activation=
'relu', input_shape=(
100,
100,
3)))
model.add(Conv2D(
32, (
3,
3), activation=
'relu'))
model.add(MaxPooling2D(pool_size=(
2,
2)))
model.add(Dropout(
0.25))
model.add(Conv2D(
64, (
3,
3), activation=
'relu'))
model.add(Conv2D(
64, (
3,
3), activation=
'relu'))
model.add(MaxPooling2D(pool_size=(
2,
2)))
model.add(Dropout(
0.25))
#dropout层可以防止过拟合,每次有25%的数据将被抛弃
model.add(Flatten())
model.add(Dense(
256, activation=
'relu'))
model.add(Dropout(
0.5))
model.add(Dense(
4, activation=
'softmax'))
对上图来说,就是根据数据集,不断的迭代,找到一条最近似的直线(y = kx + b),把参数k,b保存下来,预测的时候直接加载。
# 编译模型
sgd = SGD(lr=
0.01, decay=
1e-6, momentum=
0.9, nesterov=
True)
model.compile(loss=
'categorical_crossentropy', optimizer=sgd, metrics=[
'accuracy'])
# 一共进行32轮
# 也就是说840张图片,每次训练10张,相当于一共训练84次
model.fit(x_train, y_train, batch_size=
10, epochs=
32)
# 保存权重文件(也就是相当于“房价问题的k和b两个参数”)
model.save_weights(
'./dog_weights.h5', overwrite=
True)
# 评估模型
score = model.evaluate(x_test, y_test, batch_size=
10)
print(score)
# 1.上传图片
name = input(
'上传图片的名称(例如:XX.jpg)为:')
# 2.预处理图片(代码省略)
# 3.加载权重文件
model.load_weights(
'dog_weights.h5')
# 4.预测类别
classes = model.predict_classes(x_test)[
0]
target = [
'京巴',
'拉布拉多',
'柯基',
'泰迪']
# 3-泰迪 2-柯基 1-拉布拉多 0-京巴
# 5.打印结果
print(
"识别结果为:" + target[classes])
依赖环境
源码地址
完整Python基础知识要点
给个[在看]
以上是关于图像识别零基础?手把手带你打造一个小狗分类器!的主要内容,如果未能解决你的问题,请参考以下文章
C/C++打造Windows项目教程:任务管理器(Windows操作系统)!手把手带你进行Windows服务器开发
Python零基础(转行)自学天花板,手把手带你进入新风口高薪职业