用训练好的模型进行图像识别
Posted 某人某生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用训练好的模型进行图像识别相关的知识,希望对你有一定的参考价值。
github有点坑
发现各种深度学习的教程一般都是教怎么训练模型,用了个官方自带的mnist库,写了个训练程序,算出了一组训练数据与真实数据的交叉熵,再进行了一次练习,得到了个98%的准确率... ...然而我只能看到这些总体上的数据,却不知道如何使用。昨日开始找应用的示例,就找到了一个,读取训练好的模型,读取要识别的图片,将Sotfmax输出ID+概率通过label文本转换为人类能读的文字,再取概率最高的前五个。
遂照做。虽然自己有训练的数据,但是那种也不专业,而且用的模型很基础,于是就用github上别人训练好的 Inception-v3 模型。然而出现错误,“损坏的文本”。一开始我以为是以二进制读取文件和普通读取文件的问题,因为好像在Mac,Ubuntu系统上这两者没差别,在Windows上有差异。然而改了这个又出现新的错误,一连下来改了四五个错误,总是有新的错误出现,简直烦死人。我先后有用.strip()函数去空格/t/n什么的,有用.decode('utd-8')函数转换文本为uft-8编码形式的,还有改变文件读取方式,改变读取文件的类等等等等的方法,然而总是报错。从昨晚(应该说是今早)的0:10弄到2:00,困死人还没弄好。于是今天睡到了十点半。
今天继续了解问题出在哪里,直到我看到了训练数据只有40多k,一般这种训练数据都有100MB以上的,而且因为是二进制文件打开应该是乱码,我试着以文本文档的方式打开了这个40多k的pb文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="dns-prefetch" href="https://assets-cdn.github.com">
<link rel="dns-prefetch" href="https://avatars0.githubusercontent.com">
<link rel="dns-prefetch" href="https://avatars1.githubusercontent.com">
<link rel="dns-prefetch" href="https://avatars2.githubusercontent.com">
<link rel="dns-prefetch" href="https://avatars3.githubusercontent.com">
<link rel="dns-prefetch" href="https://github-cloud.s3.amazonaws.com">
<link rel="dns-prefetch" href="https://user-images.githubusercontent.com/">
<link href="https://assets-cdn.github.com/assets/frameworks-4324702744188e5d6edc78c06517458705b8d6596db5054c244444b56c494c99.css" integrity="sha256-QyRwJ0QYjl1u3HjAZRdFhwW41llttQVMJEREtWxJTJk=" media="all" rel="stylesheet" />
<link href="https://assets-cdn.github.com/assets/github-250399801c3e072ee195b70a64fd746472ed96902c78bb5d2cd1b6174d6a1168.css"
..............................等等等等.................................
... ...我靠,这根本不是训练数据啊,这是html啊。这时我才知道原来在github上单单点 右键——另存为 保存下来的文件根本就不是源文件,而是个源文件的html,要保存要点 raw 或者改网址前缀,费了我几小时来找问题,原来最终问题是源于读取的根本不是数据文件,真是让我哭笑不得... ...
然后便开始来测试识别效果了,总体而言很有趣:
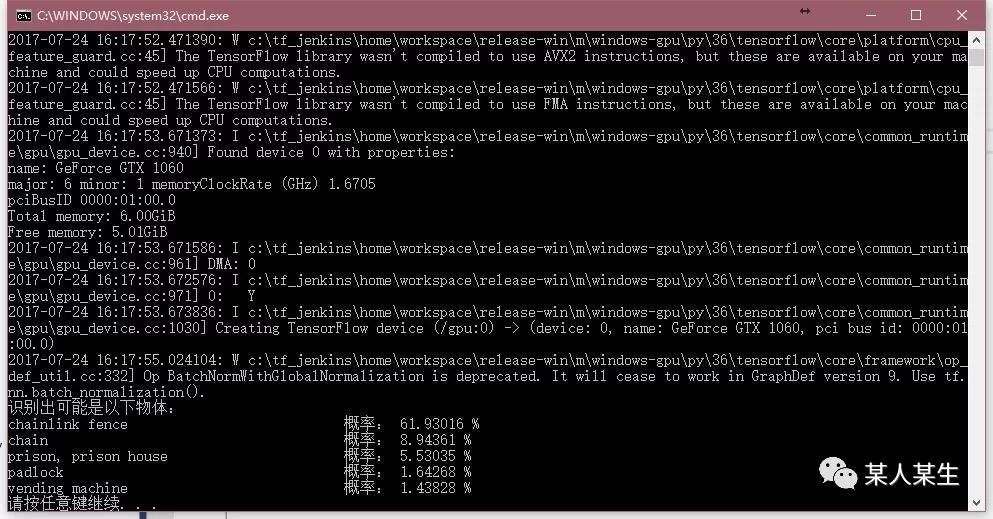
识别出可能是以下物体:
chainlink fence 概率:61.93016 %
chain 概率:8.94361 %
prison, prison house 概率:5.53035 %
padlock 概率:1.64268 %
vending machine 概率:1.43828 %
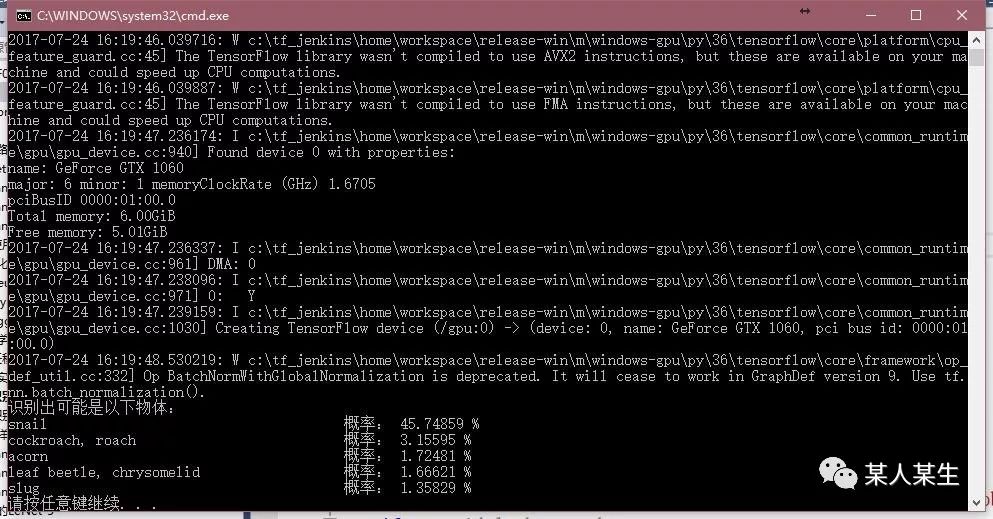
识别出可能是以下物体:
snail 概率:45.74856 %
cockroach, roach 概率:3.15595 %
acorn 概率:1.72481 %
leaf beetle, chrysomelid 概率:1.66621 %
slug 概率:1.35829 %

 识别出可能是以下物体:
识别出可能是以下物体:
daisy 概率:93.18478 %
bee 概率:0.44407 %
cabbage butterfly 概率:0.42525 %
picket fence, paling 概率:0.33883 %
greenhouse, nursery, glasshouse 概率:0.19630 %

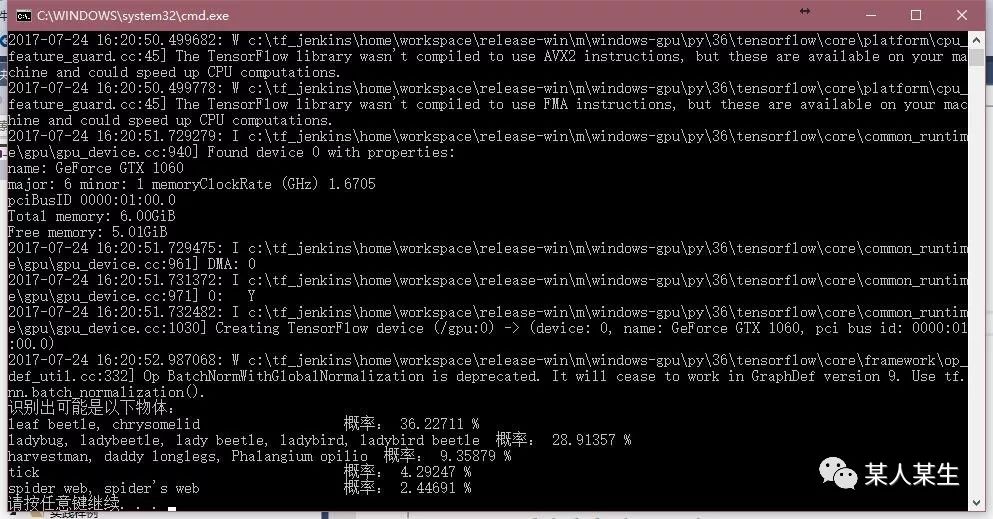
识别出可能是以下物体:
leaf beetle, chrysomelid 概率:36.22711 %
ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle 概率:28.91357 %
harvestman, daddy longlegs, Phalangium opilio 概率:9.35879 %
tick 概率:4.29247 %
spider web, spider's web 概率:2.44691 %
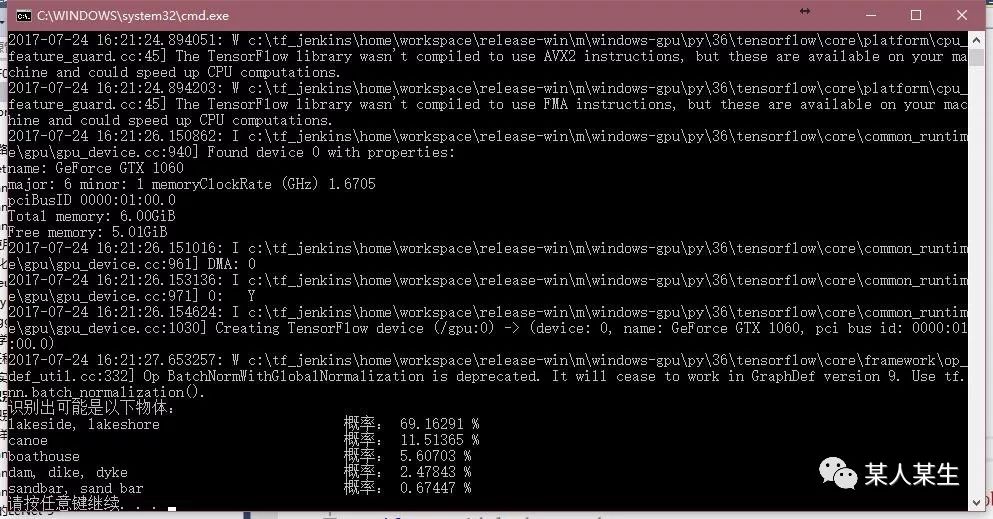
识别出可能是以下物体:
lakeside, lakeshore 概率:69.16292 %
canoe 概率:11.51364 %
boathouse 概率:5.60703 %
dam, dike, dyke 概率:2.47843 %
sandbar, sand bar 概率:0.67447 %

识别出可能是以下物体:
pizza, pizza pie 概率:94.96625 %
French loaf 概率:0.07336 %
zucchini, courgette 概率:0.04864 %
book jacket, dust cover, dust jacket, dust wrapper 概率:0.03608 %
file, file cabinet, filing cabinet 概率:0.03408 %

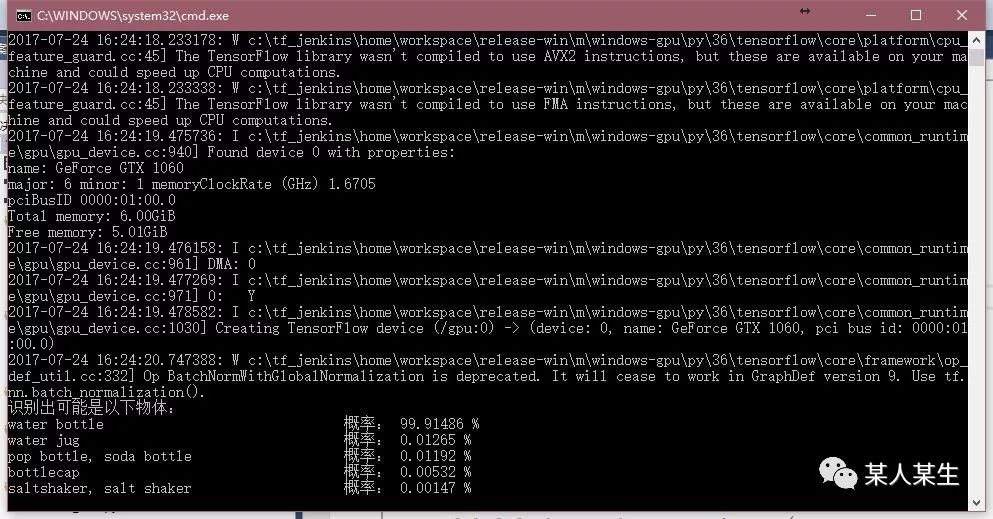
识别出可能是以下物体:
water bottle 概率:99.91486 %
water jug 概率:0.01265 %
pop bottle, soda bottle 概率:0.01192 %
bottlecap 概率:0.00532 %
saltshaker, salt shaker 概率:0.00147 %
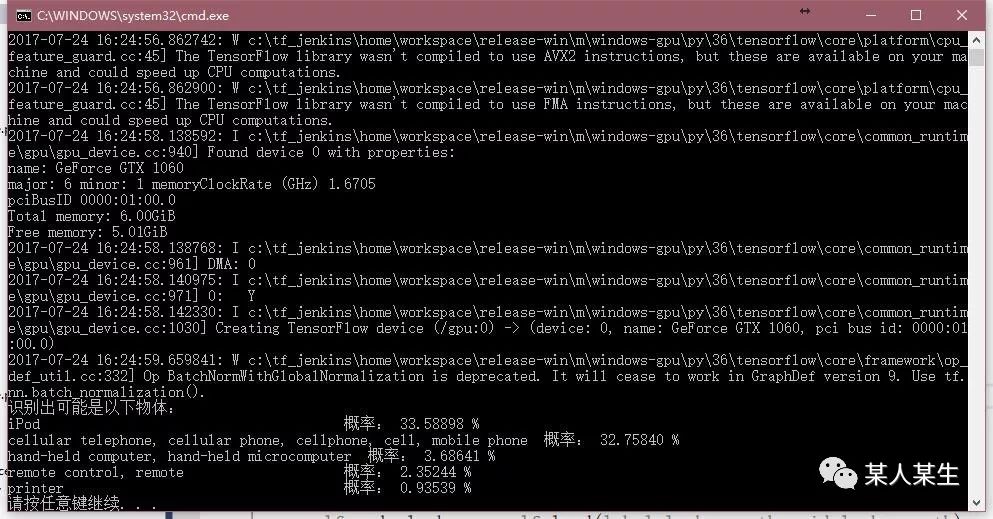
识别出可能是以下物体:
iPod 概率:33.58898 %
cellular telephone, cellular phone, cellphone, cell, mobile phone 概率:32.75841 %
hand-held computer, hand-held microcomputer 概率:3.68641 %
remote control, remote 概率:2.35244 %
printer 概率:0.93538 %
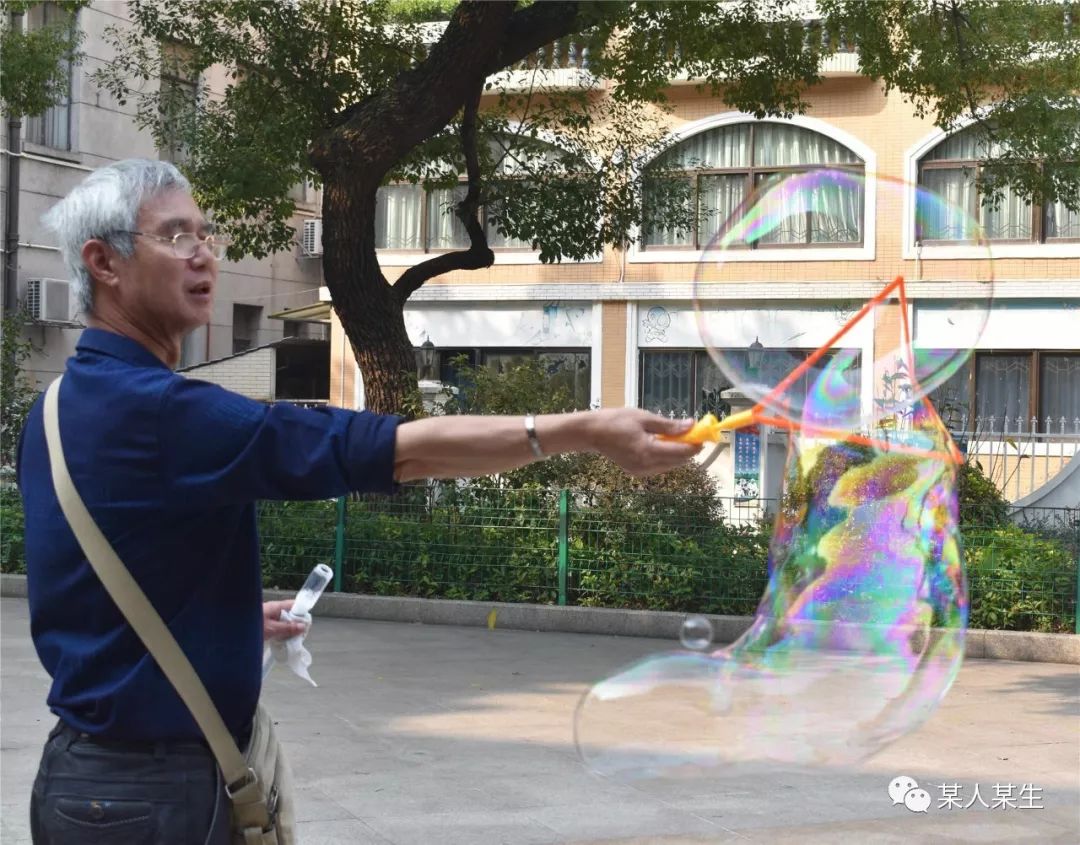
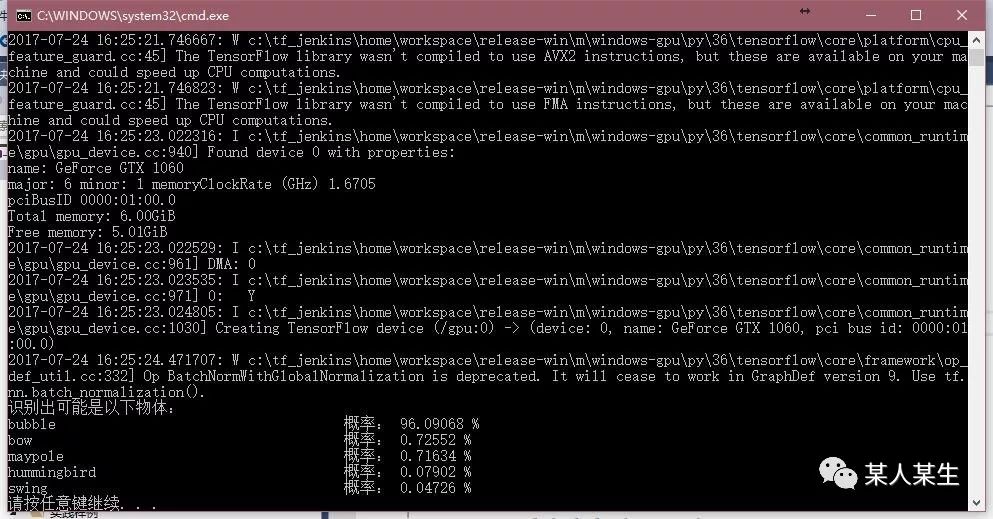
识别出可能是以下物体:
bubble 概率:96.09068 %
bow 概率:0.72552 %
maypole 概率:0.71634 %
hummingbird 概率:0.07902 %
swing 概率:0.04726 %
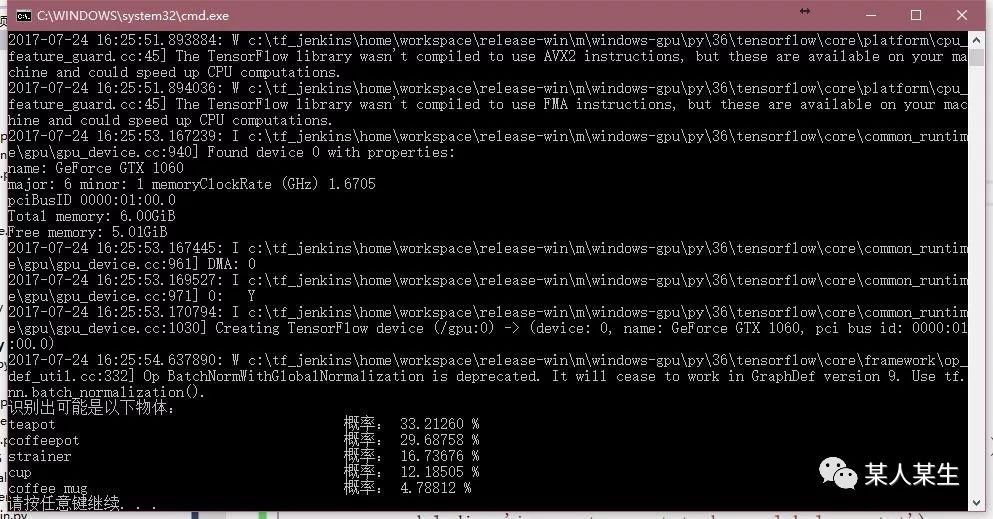
识别出可能是以下物体:
teapot 概率:33.21260 %
coffeepot 概率:29.68758 %
strainer 概率:16.73676 %
cup 概率:12.18505 %
coffee mug 概率:4.78812 %
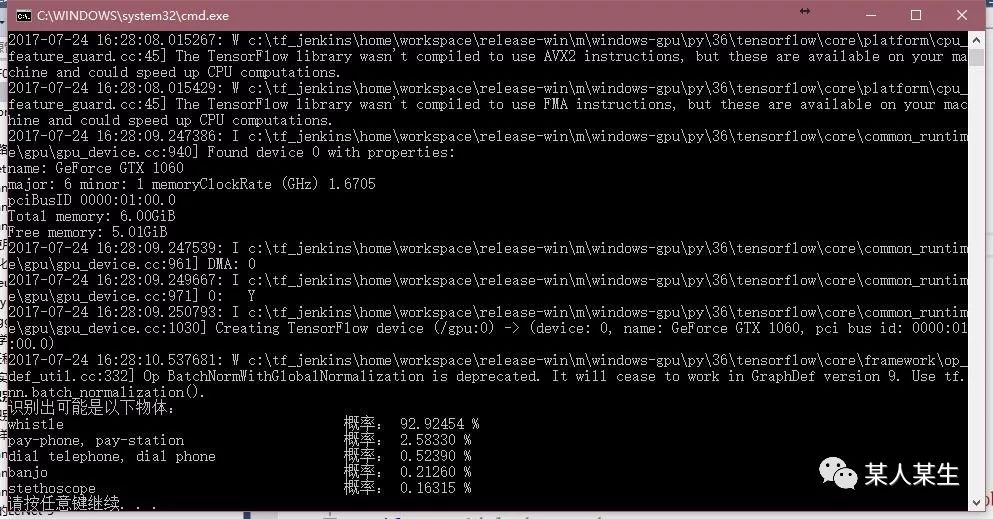
识别出可能是以下物体:
whistle 概率:92.92454 %
pay-phone, pay-station 概率:2.58330 %
dial telephone, dial phone 概率:0.52390 %
banjo 概率:0.21260 %
stethoscope 概率:0.16315 %

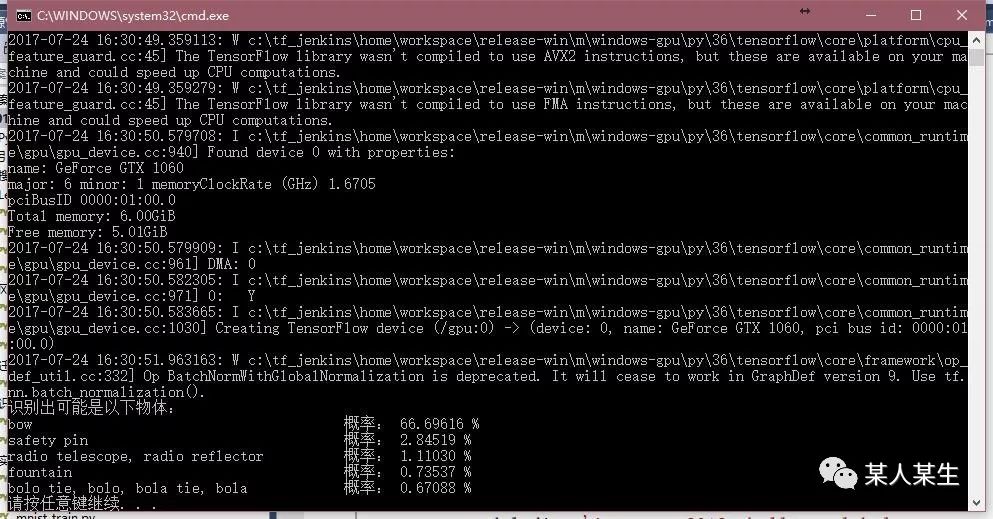
识别出可能是以下物体:
bow 概率:66.69613 %
safety pin 概率:2.84519 %
radio telescope, radio reflector 概率:1.11030 %
fountain 概率:0.73537 %
bolo tie, bolo, bola tie, bola 概率:0.67089 %
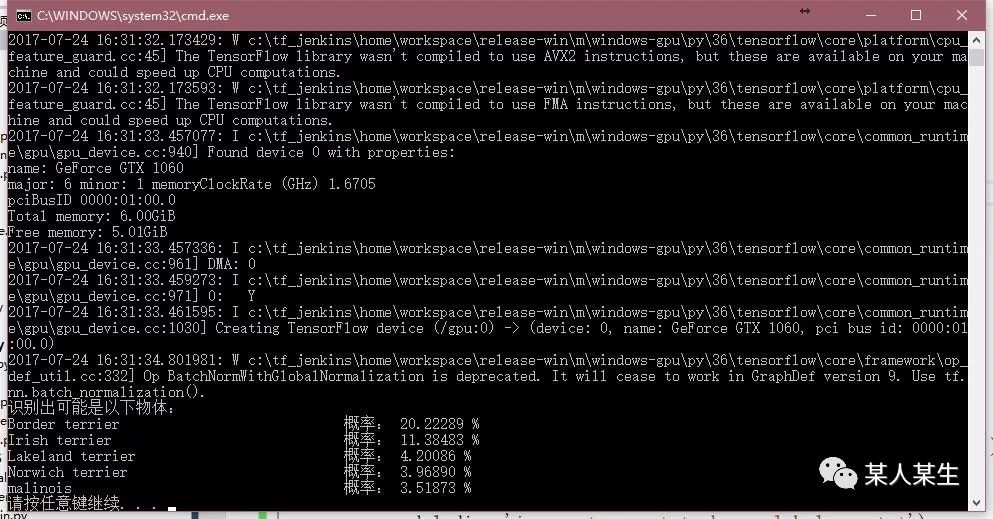
识别出可能是以下物体:
Border terrier 概率:20.22291 %
Irish terrier 概率:11.38482 %
Lakeland terrier 概率:4.20086 %
Norwich terrier 概率:3.96890 %
malinois 概率:3.51872 %
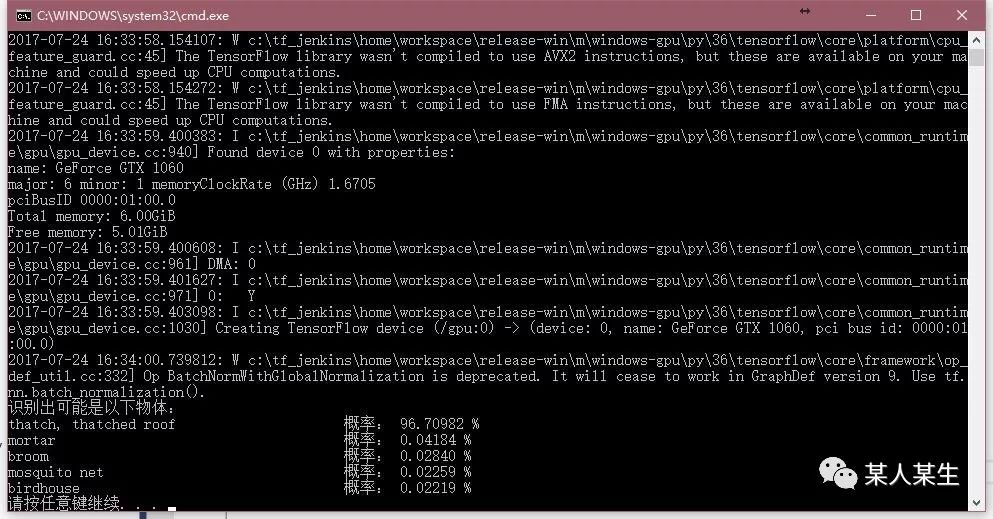
识别出可能是以下物体:
thatch, thatched roof 概率:96.70984 %
mortar 概率:0.04184 %
broom 概率:0.02840 %
mosquito net 概率:0.02259 %
birdhouse 概率:0.02219 %
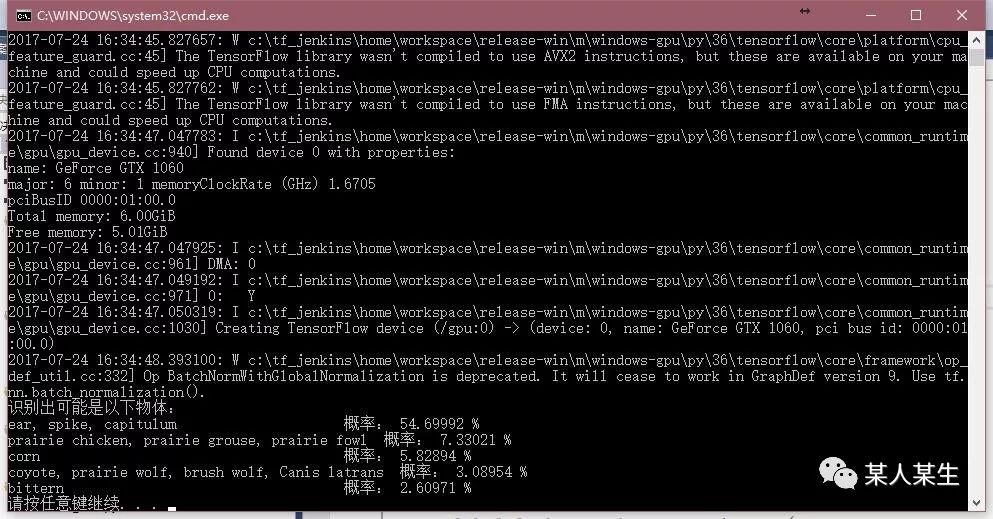
识别出可能是以下物体:
ear, spike, capitulum 概率:54.69990 %
prairie chicken, prairie grouse, prairie fowl 概率:7.33020 %
corn 概率:5.82894 %
coyote, prairie wolf, brush wolf, Canis latrans 概率:3.08954 %
bittern 概率:2.60971 %
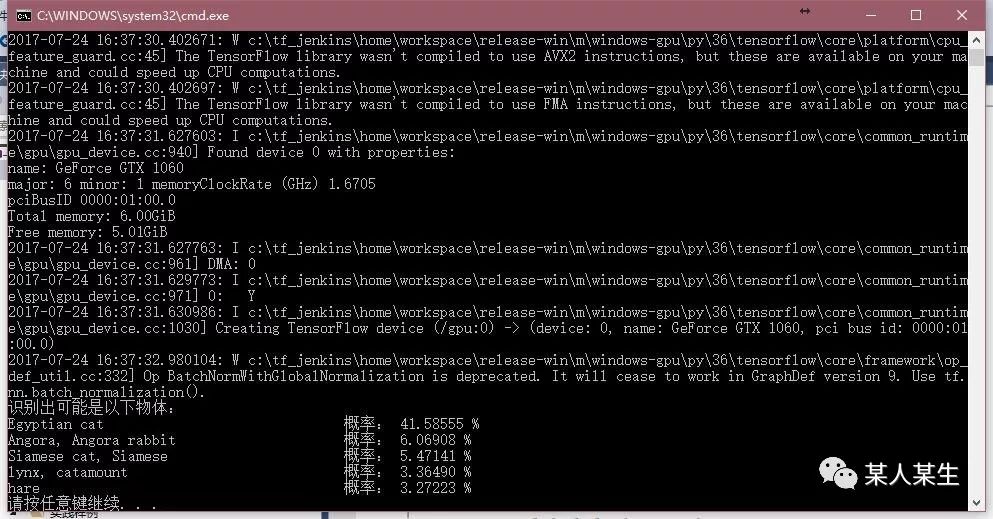
识别出可能是以下物体:
Egyptian cat 概率:41.58555 %
Angora, Angora rabbit 概率:6.06907 %
Siamese cat, Siamese 概率:5.47141 %
lynx, catamount 概率:3.36490 %
hare 概率:3.27223 %
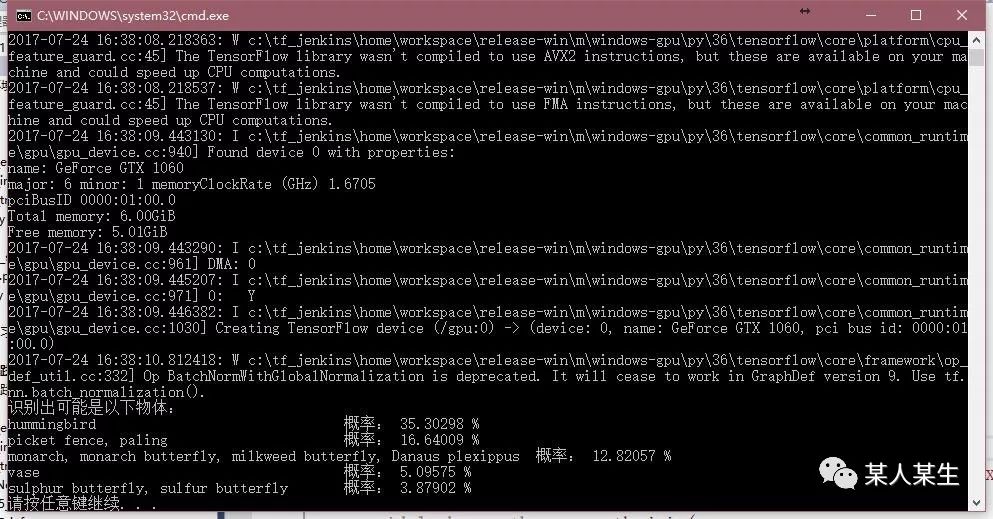
识别出可能是以下物体:
hummingbird 概率:35.30299 %
picket fence, paling 概率:16.64010 %
monarch, monarch butterfly, milkweed butterfly, Danaus plexippus 概率:12.82056 %
vase 概率:5.09575 %
sulphur butterfly, sulfur butterfly 概率:3.87901 %
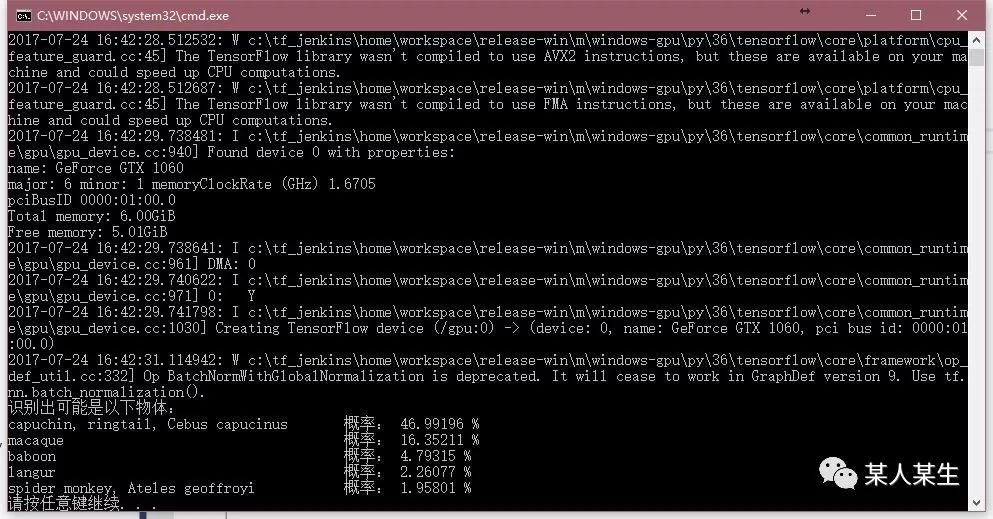
识别出可能是以下物体:
capuchin, ringtail, Cebus capucinus 概率:46.99196 %
macaque 概率:16.35211 %
baboon 概率:4.79315 %
langur 概率:2.26077 %
spider monkey, Ateles geoffroyi 概率:1.95801 %

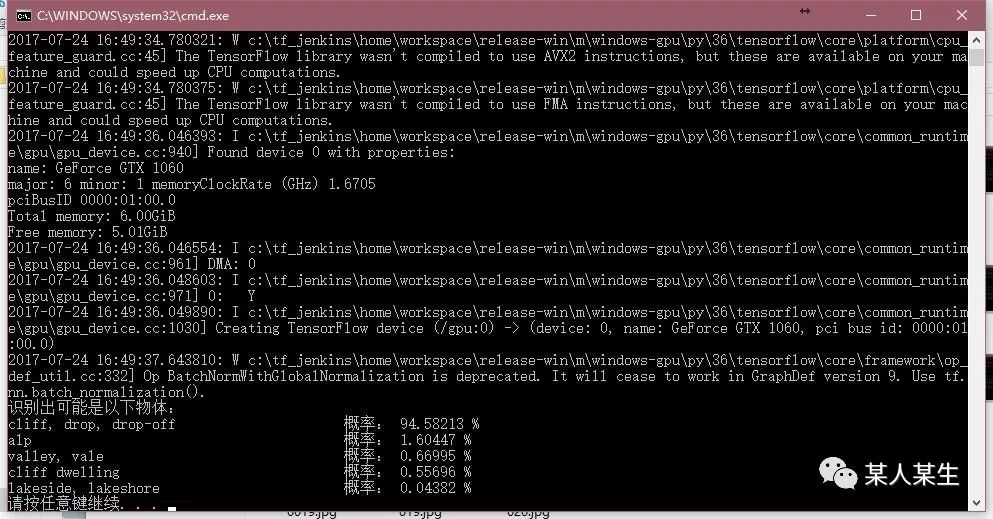
识别出可能是以下物体:
cliff, drop, drop-off 概率:94.58213 %
alp 概率:1.60447 %
valley, vale 概率:0.66995 %
cliff dwelling 概率:0.55696 %
lakeside, lakeshore 概率:0.04382 %
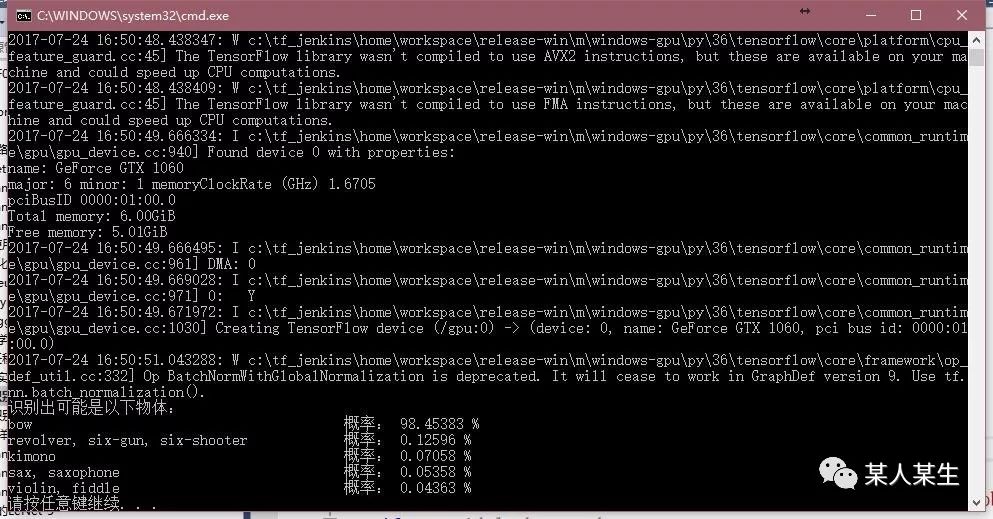
识别出可能是以下物体:
bow 概率:98.45382 %
revolver, six-gun, six-shooter 概率:0.12596 %
kimono 概率:0.07058 %
sax, saxophone 概率:0.05358 %
violin, fiddle 概率:0.04363 %
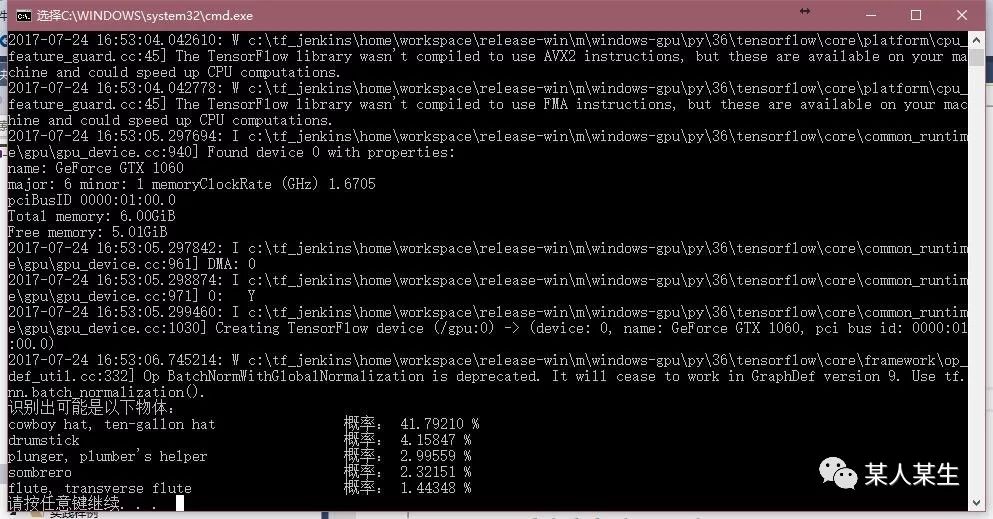
识别出可能是以下物体:
cowboy hat, ten-gallon hat 概率:41.79210 %
drumstick 概率:4.15847 %
plunger, plumber's helper 概率:2.99559 %
sombrero 概率:2.32151 %
flute, transverse flute 概率:1.44348 %
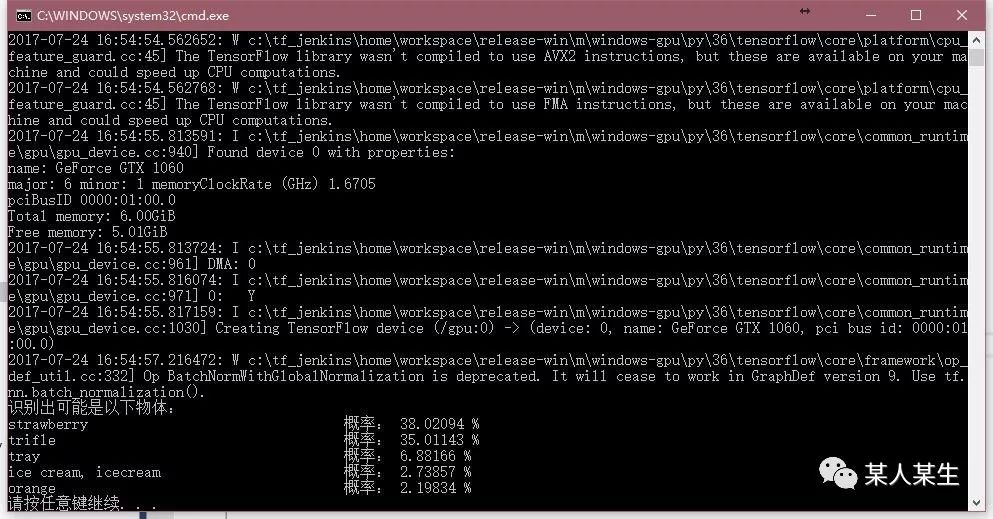
识别出可能是以下物体:
strawberry 概率:38.02094 %
trifle 概率:35.01143 %
tray 概率:6.88166 %
ice cream, icecream 概率:2.73857 %
orange 概率:2.19834 %
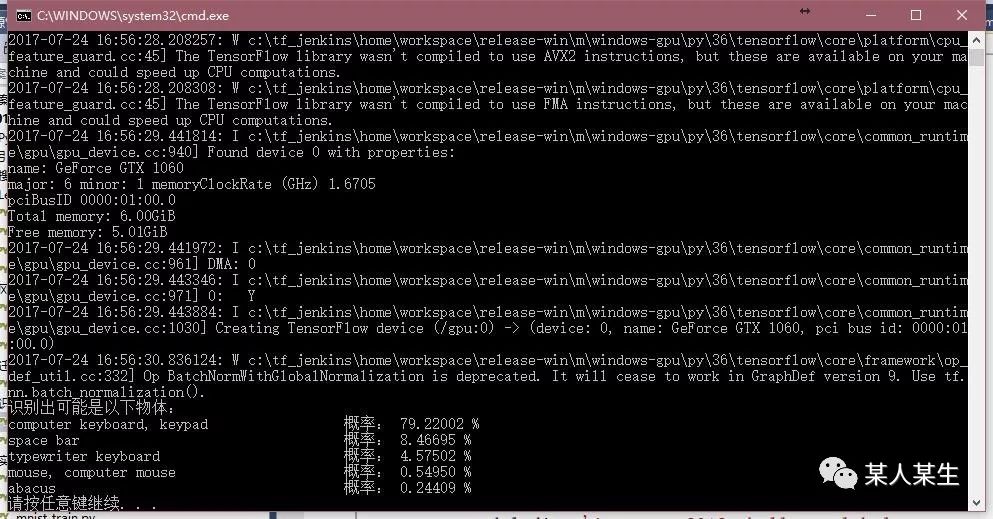
识别出可能是以下物体:
computer keyboard, keypad 概率:79.22003 %
space bar 概率:8.46694 %
typewriter keyboard 概率:4.57503 %
mouse, computer mouse 概率:0.54950 %
abacus 概率:0.24409 %
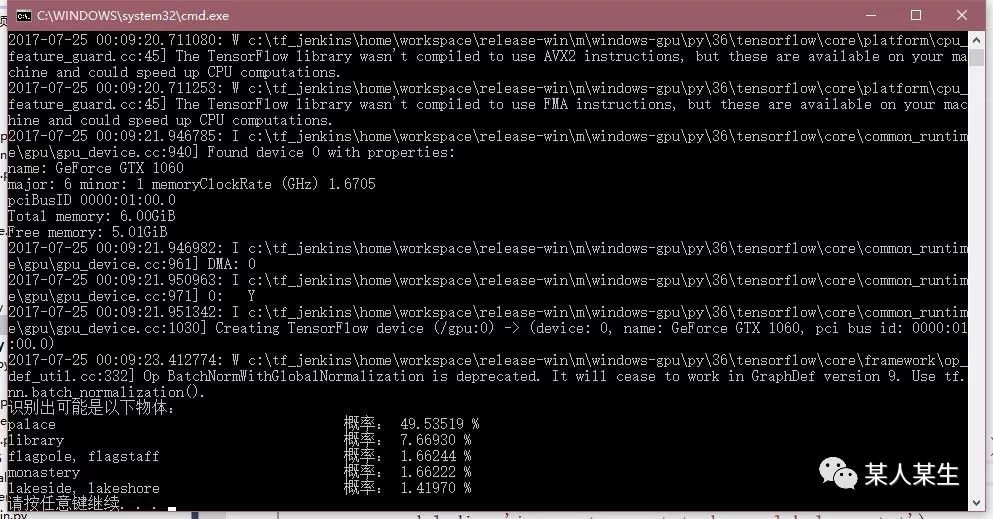
识别出可能是以下物体:
palace 概率:49.53517 %
library 概率:7.66930 %
flagpole, flagstaff 概率:1.66244 %
monastery 概率:1.66222 %
lakeside, lakeshore 概率:1.41970 %
不过第二种可能猜对了

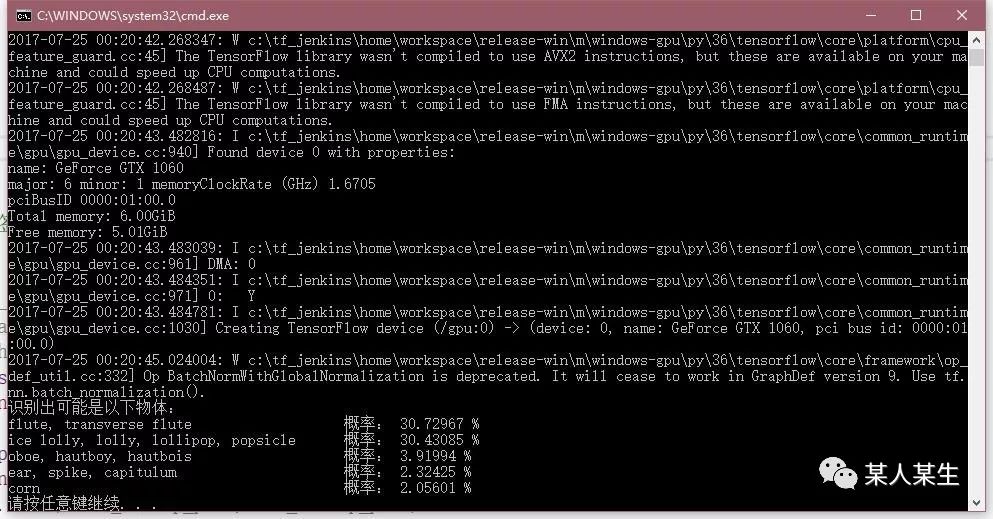 识别出可能是以下物体:
识别出可能是以下物体:
flute, transverse flute 概率:30.72968 %
ice lolly, lolly, lollipop, popsicle 概率:30.43085 %
oboe, hautboy, hautbois 概率:3.91994 %
ear, spike, capitulum 概率:2.32425 %
corn 概率:2.05601 %
总之除此之外还试了很多照片就不一一发出来了,能够使用训练好的模型也算是这两天的一个进步吧,之后训练了自己的模型也可以直接套用来测试了,岂不美哉?
另外我严重怀疑PS CC2017里面的图像处理算法有用到和我现在用的框架一样的内核数据或者调用了和我计算时同样使用的硬件运算模块,打开PS时进行识别运算会一直像下面这样报错:
写了40min左右吧,我差不多该休息了。
以上是关于用训练好的模型进行图像识别的主要内容,如果未能解决你的问题,请参考以下文章