VSRC唯科普简易图像识别与文字处理(第11/14篇)
Posted 唯品会安全应急响应中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VSRC唯科普简易图像识别与文字处理(第11/14篇)相关的知识,希望对你有一定的参考价值。
鸣 谢
VSRC感谢业界小伙伴——Mils 投稿精品科普类文章。VSRC欢迎精品原创类文章投稿,优秀文章一旦采纳发布,将有好礼相送,我们已为您准备好了丰富的奖品!
(活动最终解释权归VSRC所有)
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python有很多库可以进行图像处理,例如Tesseract库。Tesseract库目前由Google赞助,Tesseract库也是目前公认最优秀、最精准的开源OCR系统。除了极高的精准度,也具有很高的灵活性。通过有效的训练,可以识别出任何字体及Unicode字符。
通常,格式规范的文字具有以下特点:
使用一个标准字体,虽然被复制或被拍照,但是字体还是清晰的,并且没有多余的痕迹;
排列整齐且没有歪歪斜斜的字;
没有超出图片范围的内容;
也没有残缺不全或紧贴在图片的边缘;
例如以下这段规范文字示例:

我们使用 tesseract text1.tif textoutput | dir textoutput.txt 命令将其内容进行读取并将结果写到一个文本文件中:
D:Program FilesTesseract-OCR>tesseract text1.tif textoutput | dir textoutput.txt
Volume in drive D has no label.
Volume Serial Number is 2695-512E
Directory of D:Program FilesTesseract-OCR
Tesseract Open Source OCR Engine v5.0.0-alpha.20200223 with Leptonica运行这段命令后,会输出Tesseract版本信息:Tesseract Open Source OCR Engine v5.0.0-alpha.20200223 with Leptonica ,表明程序正在运行,后面是图片识别结果textoutput.txt文件里的内容,并且我们可以看到,识别的结果还是非常准确的。
This is some text,written in Arial,that will be read by
Tesseract. Here are some symbols: !@##$%%()网站上的图片有些看起来丰富多彩,但其文字内容对爬虫来说却并不太直观,并且图书的预览页面通常不会允许爬虫采集,例如Amazon图书的预览页面,会通过Ajax脚本进行加载,预览图片也会隐藏在div节点内,这对于普通的访问者而言,他们看起来更像是一个Flash动画,而不是一个图片文件。
采集此类文字,我们可以使用Selenium+WebDriver+Tesseract相结合的方式来实现,以托尔斯泰的《War and Peace》为例,采集的整体思路为:先导航到托尔斯泰的《War and Peace》页面,然后打开阅读器,收集图片的URL链接,最后下载图片,识别图片,打印图片内的文字。以下为对应实现的代码,其中除了在《Web Scraping with Python》中提及到的内容,VSRC唯科普还会将具体元素的定位方式进行讲解,以帮助读者更直观的理解这段代码背后具体所执行的操作。
# encoding=utf8
import time
from urllib.request import urlretrieve
import subprocess
from selenium import webdriver
driver = webdriver.Chrome(executable_path='C:chromedriver.exe')
driver.get(
"https://www.amazon.com/War-Peace-Leo-Nikolayevich-Tolstoy/dp/1427030200"
)
time.sleep(2)
并调用javascript执行点击操作:
ele = driver.find_element_by_id('sitbLogoImg')
driver.execute_script("arguments[0].click();", ele)
time.sleep(5)

读取预览页内容,并选取所有class元素,且这些元素拥有值为pageImage的class属性。
imageList = set()
while "pointer" in driver.find_element_by_id('sitbReaderRightPageTurner').get_attribute("style"):
driver.find_element_by_id("sitbReaderRightPageTurner").click()
time.sleep(2)
pages = driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")
for page in pages:
image = page.get_attribute("src")
imageList.add(image)
if len(imageList) > 3:
break
driver.quit()使用tesseract对页面内容进行分析,收集图片的URL链接:
for image in sorted(imageList):
urlretrieve(image,"page.jpg")
p = subprocess.Popen(["D:\Program Files\Tesseract-OCR\tesseract.exe","page.jpg","page"],stdout=subprocess.PIPE,stderr=subprocess.PIPE)
p.wait()
f = open("page.txt","r")
print (f.read())最终输出如下:
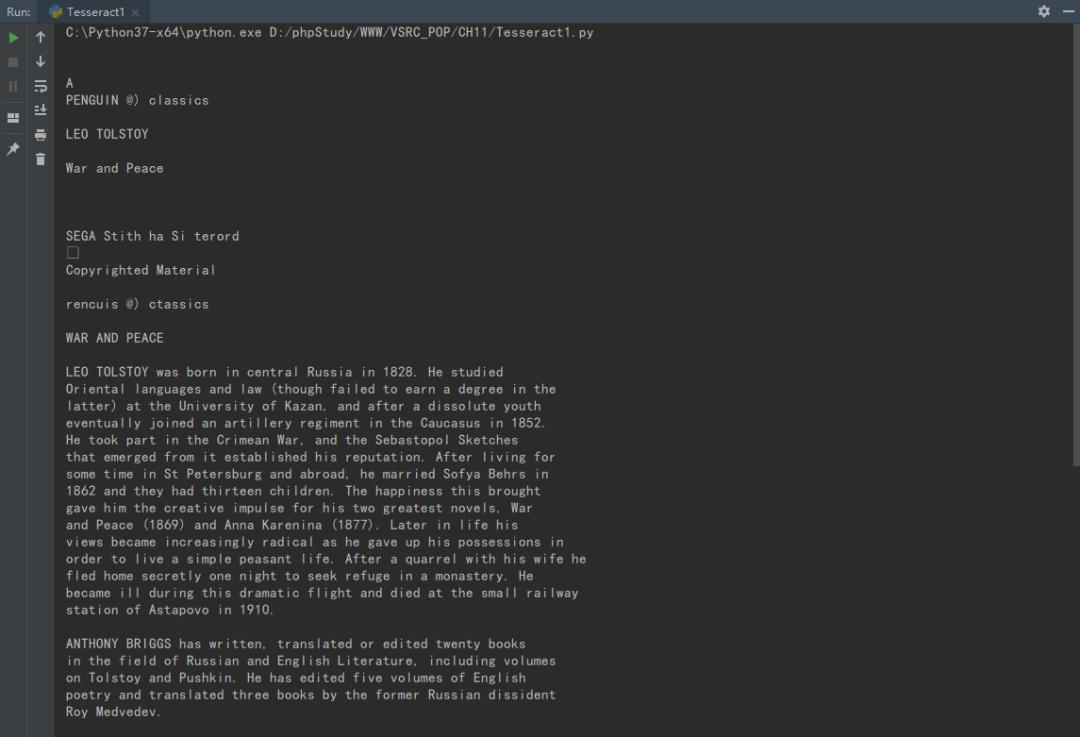
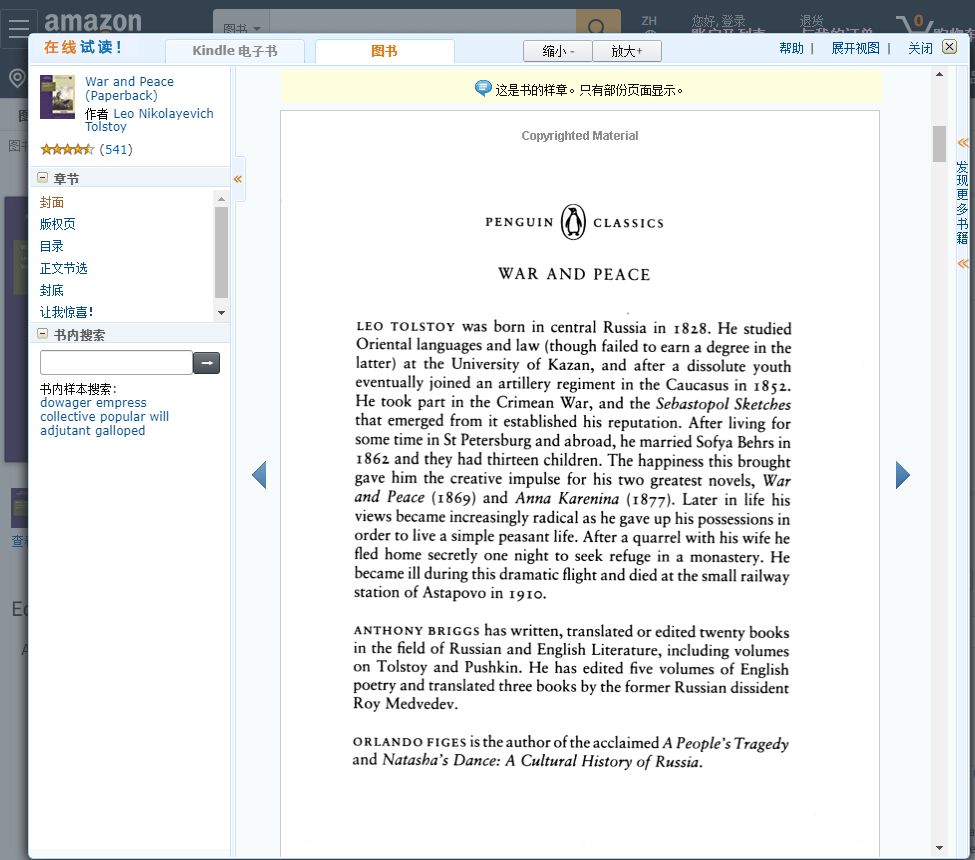
我们将其中部分内容,与原文内容比对后,很明显的能发现,通过程序读取的内容还原度整体较高。
大多数网站生成的验证码图片都具有以下属性:
-
他们设计服务器端的程序动态生成的图片,验证码图片的src属性,可能会和普通图片不太一样,比如<img >,但是可以和其他 图片一样进行下载和处理; -
图片的答案存储在服务器端的数据库里; -
很多验证码都有时间限制;
我们通过一个在线的带验证码的评论表单 http://www.pythonscraping.com/humans-only ,来演示如何使用机器人破解验证码。
实现代码如下:
# encoding=utf8
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
import subprocess
import requests
from PIL import Image
from PIL import ImageOps
def cleanImage(imagePath):
image = Image.open(imagePath)
image = image.point(lambda x: 0 if x <143 else 255)
borderImage = ImageOps.expand(image, border=20, fill='white')
borderImage.save(imagePath)
html = urlopen('http://www.pythonscraping.com/humans-only')
bsObj = BeautifulSoup(html,"html.parser")
imageLocation = bsObj.find("img",{'title':"Image CAPTCHA"})["src"]
formBuildId = bsObj.find("input",{"name":"form_build_id"})["value"]
captchaSid = bsObj.find("input",{"name":"captcha_sid"})["value"]
captchaToken = bsObj.find("input",{"name":"captcha_token"})["value"]
captchaUrl = "http://pythonscraping.com"+imageLocation
urlretrieve(captchaUrl,"captcha.jpg")
cleanImage("captcha.jpg")
p = subprocess.Popen(["D:\Program Files\Tesseract-OCR\tesseract.exe","captcha.jpg","captcha"],stdout=subprocess.PIPE,stderr=subprocess.PIPE)
p.wait()
f = open("captcha.txt","r")
captchaResponse = f.read().replace(" ","").replace("
","")
print ("Captcha solution attempt: "+captchaResponse)
if len(captchaResponse) == 5:
params = {"captcha_token":captchaToken,"captcha_sid":captchaSid,
"form_id":"comment_node_page_form","form_build_id":formBuildId,
"captcha_response":captchaResponse,"name":"Ryan Mitchell",
"subject":"I come to seek the Grail",
"comment_body[und][0][value]":
"...and I am definitely not a bot"}
r = requests.post ("http://www.pythonscraping.com/comment/reply/10",data=params)
responseObj = BeautifulSoup(r.text)
if responseObj.find("div",{"class":"messages"}) is not None:
print(responseObj.find("div",{"class":"messages"}).get_text())
else:
print ("There was a problem reading the CAPTCHA correctly!")最终输出结果如下:
1、https://www.w3school.com.cn/xpath/xpath_intro.asp
2、https://github.com/tesseract-ocr/tesseract/wiki3
3、https://www.python.org/
4、《Web Scraping with Python》
唯科普 | 《数据采集》目录
A.K.A "小白终结者"系列
第11篇、图像识别与文字处理
第12篇、避开采集的陷阱
第13篇、用自动化程序测试网站
第14篇、远程采集
。
。
精彩原创文章投稿有惊喜!
VSRC欢迎精品原创类文章投稿,优秀文章一旦采纳发布,将为您准备的丰富奖金税后1000元现金或等值礼品,上不封顶!如若是安全文章连载,奖金更加丰厚,税后10000元或等值礼品,上不封顶!还可领取精美礼品!可点击“阅读原文”了解规则。(最终奖励以文章质量为准。活动最终解释权归VSRC所有)
不知道,大家都喜欢阅读哪些类型的信息安全文章?
不知道,大家都希望我们更新关于哪些主题的干货?
精彩留言互动的热心用户,将有机会获得VSRC赠送的精美奖品一份!
同时,我们也会根据大家反馈的建议,选取热门话题,进行原创发布!
点击阅读原文进入 【VSRC征稿】宅家副业攻略请查收!
以上是关于VSRC唯科普简易图像识别与文字处理(第11/14篇)的主要内容,如果未能解决你的问题,请参考以下文章