图像识别—EfficientNet算法详细总结
Posted AI研习图书馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别—EfficientNet算法详细总结相关的知识,希望对你有一定的参考价值。
AI研习图书馆,发现不一样的世界

算法简介
文章题目:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (ICML 2019 )
论文链接:https://arxiv.org/abs/1905.11946
代码链接:
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
PyTorch实现:https://github.com/lukemelas/EfficientNet-PyTorch
EfficientNet是谷歌2019年的一篇图像分类论文。
这篇论文主要讲述了如何利用复合系数统一缩放模型的所有维度,达到精度最高和效率最高。符合系数包括w,d,r,其中,w表示卷积核大小,决定了感受野大小;d表示神经网络的深度;r表示分辨率大小。
算法笔记
2.1 摘要
卷积神经网络通常都是先在固定资源预算下开发设计,然后如果资源有多余的话再将模型结构放大以便获得更好的精度。在本篇论文中,作者系统地研究了模型缩放并且仔细验证了网络深度、宽度和分辨率之间的平衡可以导致更好的性能表现。基于这样的观察,提出了一种新的缩放方法——使用一个简单高效的复合系数来完成对深度/宽度/分辨率所有维度的统一缩放。作者在MobileNets和ResNet上展示了这种缩放方法的高效性。
为了进一步研究,作者使用神经架构搜索设计了一个baseline网络,并且将模型放大获得一系列模型,作者称之为EfficientNets,它的精度和效率比之前所有的卷积网络都好。尤其是EfficientNet-B7在ImageNet上获得了最先进的 84.4%的top-1精度 和 97.1%的top-5精度,同时比之前最好的卷积网络大小缩小了8.4倍、速度提高了6.1倍。EfficientNets也可以很好的迁移,并且实现了最先进的精度——CIFAR-100(91.7%)、Flowers(98.8%)、等其他3个迁移学习数据集。
2.2 文章重点总结
目前通用的几种方法是放大CNN的深度、宽度和分辨率,在之前都是单独放大这三个维度中的一个,尽管任意放大两个或者三个维度也是可能的,但是任意缩放需要繁琐的人工调参同时可能产生的是一个次优的精度和效率。
在本篇论文中,作者想要研究和重新思考放大CNN的过程,尤其地,调查了一个中心问题:是否存在一个原则性的放大CNN的方法实现更好的精度和效率?作者的实验研究表明了平衡深度、宽度和分辨率这三个维度是至关重要的,令人惊讶的是这样的平衡可以通过简单的使用一组常量比率来缩放每一个维度,基于这个观察,提出了一个简单高效的复合缩放方法,不像传统实践中任意缩放这些因子,作者提出的方法使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
在已经存在的MobileNets和ResNets上展示了缩放方法可以工作得很好,值得注意的是,模型缩放的高效性严重地依赖于baseline网络,为了进一步研究,作者使用网络结构搜索发展了一种新的baseline网络,然后将它缩放来获得一系列模型,称之为EfficientNets。
2.3 个人总结
个人理解的算法笔记如下:
(1)文中总结了我们常用的三种网络调节方式:增大感受野w,增大网络深度d,增大分辨率大小r,三种方式示意图如下:
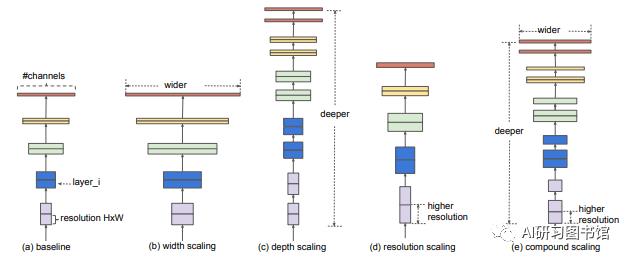
其中,(a)为基线网络,也可以理解为小网络;(b)为增大感受野的方式扩展网络;(c)为增大网络深度d的方式扩展网络;(d)为增大分辨率r的方式扩展网络;(e)为本文所提出的混合参数扩展方式。
文中试验测试,调查了w/r/d在各种情况下的准确率和效率的相互关系曲线,如下图所示:
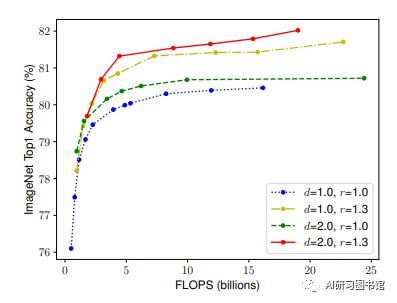
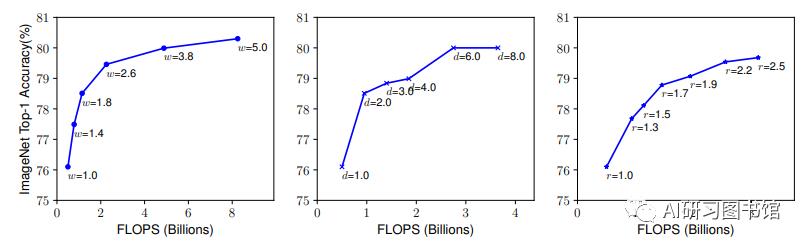
(2)总结规律如下:
在r和w大小不变的情况下,随着d的增大,准确率没有太大的差异;
在d和w不变的情况下,随着r的增大,准确率有较大提升;
r和d不变的情况下,随着w的增大,准确率先有较大提升,然后趋于平缓,往后再无太大提升。
复合系数的数学模型
文中给出了一般卷积的数学模型如下:
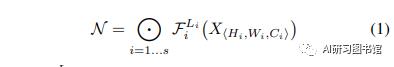
其中H,W为卷积核大小,C为通道数,X为输入tensor;
则复合系数的确定转为如下的优化问题:

调节d,w,r使得满足内存Memory和浮点数量都小于阈值要求;
为了达到这个目标,文中提出了如下的方法:
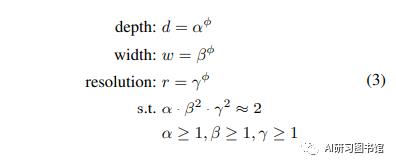
对于这个方法,我们可以通过一下两步来确定d,w,r参数:

第一步我们可以通过基线网络来调节确定最佳的,然后,用这个参数将基准网络扩展或放大到大的网络,这样就可以使大网络也具有较高的准确率和效率。同样,我们也可以将基线网络扩展到其他网络,使用同样的方法来放大。
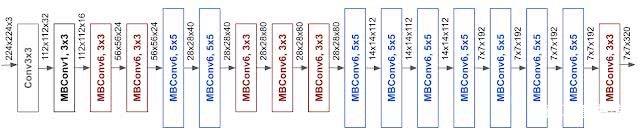
发现问题并解决问题——论文中基线模型使用的是 mobile inverted bottleneck convolution(MBConv),类似于 MobileNetV2 和 MnasNet,但是由于 FLOP 预算增加,该模型较大。于是,研究人员缩放该基线模型,得到了EfficientNets模型,它的网络示意图如下:
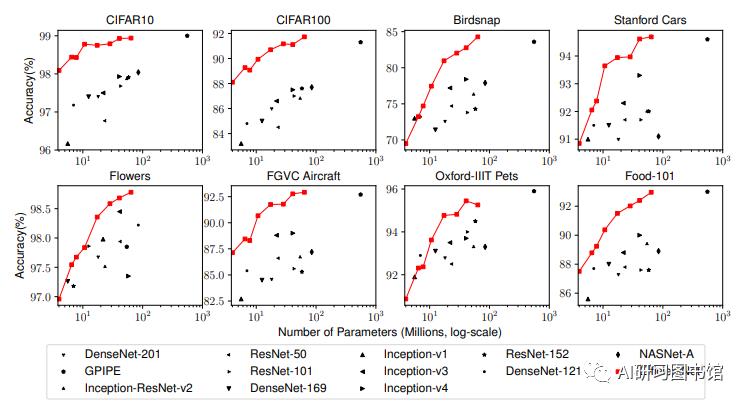
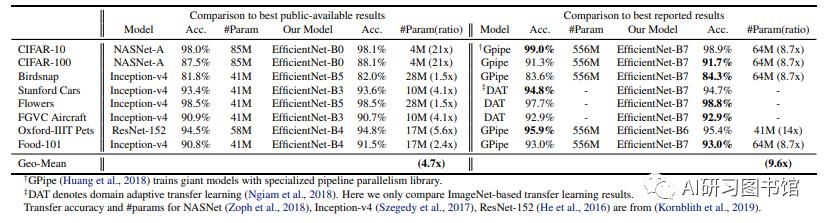
最后,研究人员对EfficientNets的效率进行了测试,结果如下:
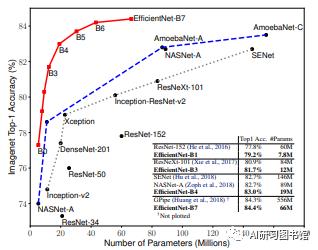
对比EfficientNets和已有的CNN模型,EfficientNet 模型要比已有 CNN 模型准确率更高、效率更高,其参数量和 FLOPS 都下降了一个数量级,EfficientNet-B7 在 ImageNet 上获得了当前最优的 84.4% top-1 / 97.1% top-5 准确率,而且CPU 推断速度是 Gpipe 的 6.1 倍,而且模型大小方面,EfficientNet-B7却比其他模型要小得多,同时,还对比了ResNet-50,准确率也是胜出一筹(ResNet-50 76.3%,EfficientNet-B4 82.6%)。
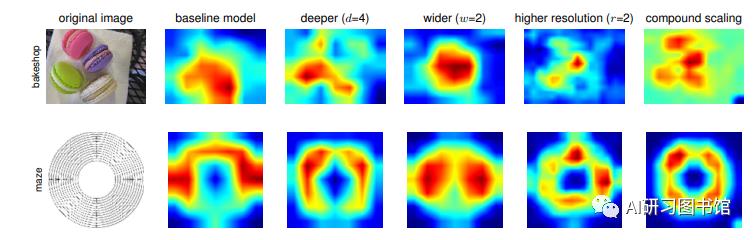
寄语
EffieicntNet的研究思路大家可以学习一下,在这个日新月异的伟大时代,创新性思维显得弥足珍贵,心平气和,好好研究论文吧,祝大家文章发发发~
推荐阅读文章
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
......






关注AI研习图书馆,发现不一样的精彩世界
以上是关于图像识别—EfficientNet算法详细总结的主要内容,如果未能解决你的问题,请参考以下文章