什么是图像识别?图像识别是如何实现的?
Posted 电子产品世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是图像识别?图像识别是如何实现的?相关的知识,希望对你有一定的参考价值。
当我们看到一个东西,大脑会迅速判断是不是见过这个东西或者类似的东西。这个过程有点儿像搜索,我们把看到的东西和记忆中相同或相类的东西进行匹配,从而识别它。机器的图像识别也是类似的,通过分类并提取重要特征而排除多余的信息来识别图像。
归根结底,机器的图像识别和人类的图像识别原理相近,过程也大同小异。只是技术的进步让机器不但能像人类一样认花认草认物认人,还开始拥有超越人类的识别能力。
图像识别概述
图像识别原理
文字识别的研究是从 1950年开始的,一般是识别字母、数字和符号,从印刷文字识别到手写文字识别,应用非常广泛。
数字图像处理和识别的研究开始于1965年。数字图像与模拟图像相比具有存储,传输方便可压缩、传输过程中不易失真、处理方便等巨大优势,这些都为图像识别技术的发展提供了强大的动力。
物体的识别主要指的是对三维世界的客体及环境的感知和认识,属于高级的计算机视觉范畴。它是以数字图像处理与识别为基础的结合人工智能、系统学等学科的研究方向,其研究成果被广泛应用在各种工业及探测机器人上。
图像识别原理主要是需处理具有一定复杂性的信息,处理技术并不是随意出现在计算机中,结合计算机程序对相关内容模拟并予以实现。图像识别的过程归纳起来主要包括4个步骤:
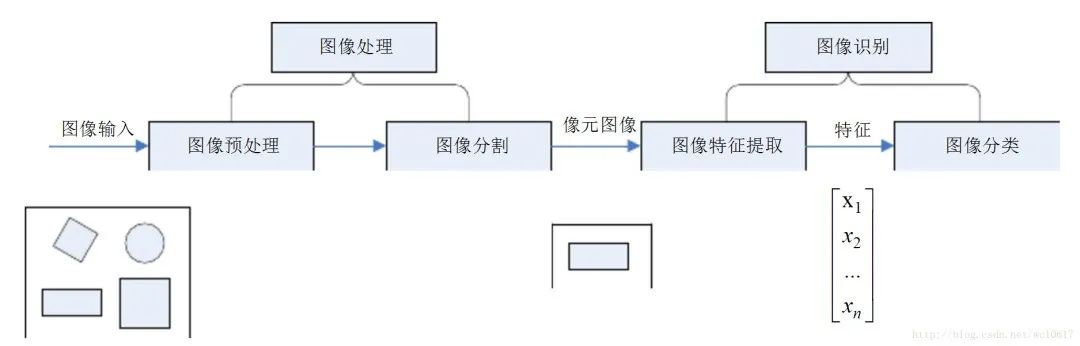
获取信息:主要是指将声音和光等信息通过传感器向电信号转换,也就是对识别对象的基本信息进行获取,并将其向计算机可识别的信息转换。
信息预处理:主要是指采用去噪、变换及平滑等操作对图像进行处理,基于此使图像的重要特点提高。
抽取及选择特征:主要是指在模式识别中,抽取及选择图像特征,概括而言就是识别图像具有种类多样的特点,如采用一定方式分离,就要识别图像的特征,获取特征也被称为特征抽取;在特征抽取中所得到的特征也许对此次识别并不都是有用的,这个时候就要提取有用的特征,这就是特征的选择。特征抽取和选择在图像识别过程中是非常关键的技术之一,所以对这一步的理解是图像识别的重点。
设计分类器及分类决策:其中设计分类器就是根据训练对识别规则进行制定,基于此识别规则能够得到特征的主要种类,进而使图像识别的不断提高辨识率,此后再通过识别特殊特征,最终实现对图像的评价和确认。
图像识别技术

基于神经网络的图像识别:神经网络图像识别技术是一种比较新型的图像识别技术,是在传统的图像识别方法和基础上融合神经网络算法的一种图像识别方法。这里的神经网络是指人工神经网络,也就是说这种神经网络并不是动物本身所具有的真正的神经网络,而是人类模仿动物神经网络后人工生成的。在神经网络图像识别技术中,遗传算法与BP网络相融合的神经网络图像识别模型是非常经典的,在很多领域都有它的应用。
在图像识别系统中利用神经网络系统,一般会先提取图像的特征,再利用图像所具有的特征映射到神经网络进行图像识别分类。以汽车拍照自动识别技术为例,当汽车通过的时候,汽车自身具有的检测设备会有所感应。此时检测设备就会启用图像采集装置来获取汽车正反面的图像。获取了图像后必须将图像上传到计算机进行保存以便识别。最后车牌定位模块就会提取车牌信息,对车牌上的字符进行识别并显示最终的结果。在对车牌上的字符进行识别的过程中就用到了基于模板匹配算法和基于人工神经网络算法。
基于非线性降维的图像识别:计算机的图像识别技术是一个异常高维的识别技术。不管图像本身的分辨率如何,其产生的数据经常是多维性的,这给计算机的识别带来了非常大的困难。想让计算机具有高效地识别能力,最直接有效的方法就是降维。降维分为线性降维和非线性降维。例如主成分分析(PCA)和线性奇异分析(LDA)等就是常见的线性降维方法,它们的特点是简单、易于理解。但是通过线性降维处理的是整体的数据集合,所求的是整个数据集合的最优低维投影。
经过验证,这种线性的降维策略计算复杂度高而且占用相对较多的时间和空间,因此就产生了基于非线性降维的图像识别技术,它是一种极其有效的非线性特征提取方法。此技术可以发现图像的非线性结构而且可以在不破坏其本征结构的基础上对其进行降维,使计算机的图像识别在尽量低的维度上进行,这样就提高了识别速率。例如人脸图像识别系统所需的维数通常很高,其复杂度之高对计算机来说无疑是巨大的“灾难”。由于在高维度空间中人脸图像的不均匀分布,使得人类可以通过非线性降维技术来得到分布紧凑的人脸图像,从而提高人脸识别技术的高效性。
图像识别的应用
图像识别初级应用:主要是娱乐化、工具化,在这个阶段用户主要是借助图像识别技术来满足某些娱乐化需求。例如,百度魔图的“大咖配”功能可以帮助用户找到与其长相最匹配的明星,百度的图片搜索可以找到相似的图片;Facebook研发了根据相片进行人脸匹配的DeepFace;雅虎收购的图像识别公司IQ Engine开发的Glow可以通过图像识别自动生成照片的标签以帮助用户管理手机上的照片;国内专注于图像识别的创业公司旷视科技成立了VisionHacker游戏工作室,借助图形识别技术研发移动端的体感游戏。
这个阶段还有一个非常重要的细分领域 —— OCR(Optical Character Recognition,光学字符识别),是指光学设备检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,就是计算机对文字的阅读。
借助OCR技术将这些文字和信息提取出来。在这方面,国内产品包括百度的涂书笔记和百度翻译等;而谷歌借助经过DistBelief 训练的大型分布式神经网络,对于Google 街景图库的上千万门牌号的识别率超过90%,每天可识别百万门牌号。
图像识别初级应用仅作为我们的辅助工具存在,为我们自身的人类视觉提供了强有力的辅助和增强,带给了我们一种全新的与外部世界进行交互的方式。这些应用虽然看起来很普通,但当图像识别技术渗透到我们行为习惯的方方面面时,我们就相当于把一部分视力外包给了机器,就像我们已经把部分记忆外包给了搜索引擎一样。
这将极大改善我们与外部世界的交互方式,此前我们利用科技工具探寻外部世界的流程是这样:人眼捕捉目标信息、大脑将信息进行分析、转化成机器可以理解的关键词、与机器交互获得结果。而当图像识别技术赋予了机器“眼睛”之后,这个过程就可以简化为:人眼借助机器捕捉目标信息、机器和互联网直接对信息进行分析并返回结果。图像识别使摄像头成为解密信息的钥匙,我们仅需把摄像头对准某一未知事物,就能得到预想的答案,摄像头成为连接人和世界信息的重要入口之一。

图像识别的高级应用:成为拥有视觉的机器,当机器真正具有了视觉之后,它们完全有可能代替我们去完成这些行动。目前的图像识别应用就像是盲人的导盲犬,在盲人行动时为其指引方向;而未来的图像识别技术将会同其他人工智能技术融合在一起成为盲人的全职管家,不需要盲人进行任何行动,而是由这个管家帮助其完成所有事情。
举个例子,如果图像识别是一个工具,就如同我们在驾驶汽车时佩戴谷歌眼镜,它将外部信息进行分析后传递给我们,我们再依据这些信息做出行驶决策;而如果将图像识别利用在机器视觉和人工智能上,这就如同谷歌的无人驾驶汽车,机器不仅可以对外部信息进行获取和分析,还全权负责所有的行驶活动,让我们得到完全解放。
图像识别并非一个新领域,但放眼全局,它仍处于早期阶段。就像任何一个典型的成长中少年一样,在适应现实世界时也存在问题。图像识别是计算机视觉时代到来的早期征兆,无论它将如何应用或将应用于哪些行业,图像识别技术永远不可能孤立发展。只有通过访问更多图片,实时数据,花费更多的时间和精力才能使其更加强大;只有认识到这一点,并充分利用这些联系的企业才可能在未来取得成功。
作为一门科技含量较高的新兴技术,AI的图像识别技术已经与用户的生活紧密结合在一起,许多科技巨头也开始了在图像识别和人工智能领域的布局:
Facebook签下的人工智能专家Yann LeCun最重大的成就就是在图像识别领域,其提出的LeNet为代表的卷积神经网络,在应用到各种不同的图像识别任务时都取得了不错效果,被认为是通用图像识别系统的代表之一;Google 借助模拟神经网络“DistBelief”通过对数百万份 YouTube 视频的学习自行掌握了猫的关键特征,这是机器在没有人帮助的情况下自己读懂了猫的概念。值得一提的是,负责这个项目的Andrew NG已经转投百度领导百度研究院,其一个重要的研究方向就是人工智能和图像识别。这也能看出国内科技公司对图像识别技术以及人工智能技术的重视程度。
加入“电子产品世界”粉丝交流群
↓↓↓↓点击阅读原文,查看更多新闻
以上是关于什么是图像识别?图像识别是如何实现的?的主要内容,如果未能解决你的问题,请参考以下文章
图像识别 | 使用 Java 实现AI人工智能技术-图像识别功能