如何系统地欺骗图像识别神经网络
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何系统地欺骗图像识别神经网络相关的知识,希望对你有一定的参考价值。
本文最初发表于 Towards Data Science 博客,经原作者 Andre Ye 授权,InfoQ 中文站翻译并分享。
卷积神经网络(Convolutional Nerual Network,CNN)构成了图像识别的基础,这无疑是深度学习最重要的应用之一。然而不幸的是,有关深度学习的许多研究都是在数据集的“完美世界”约束下进行的——追求几个百分点的正确率。因此,尽管我们开发的架构在理论测试中效果非常好,但在现实世界中却不一定如此了。
对人眼来说,对抗性样本或输入与普通图像难以区分,但却能完全骗过各种图像识别架构。对抗性输入的部署显然会带来许多令人不安的危险影响,特别是当人工智能被赋予更多自主决策的权力时,尤为如此。
因此,理解和解决应用于深度学习的系统产生对抗性输入——伦理黑客的方法是非常重要的。
由 Goodfellow 等人提出的一种简单的方法,用于系统生成对抗性输入,称为“快速梯度符号法”(fast gradient signed method)。
考虑如下:
输入向量 x(此为输入信息所在的位置,但可以将其视为一维列表)。
对抗性输入 x-hat(与 x 相同的形状,但值有所改变)。
一个 perbutation 向量 η(“eta”,以产生对抗性输入向量)。
为了执行逐个元素的乘法和求和(例如[1,2,3] [1,2,3] = 1+4+9 = 14),我们将第一个向量的转置乘以第二个向量。这就是所谓的“加权总和”。
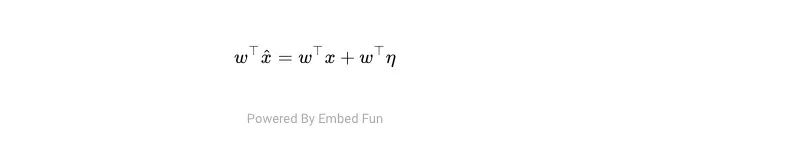
在这方面,我们必须实现两个目标,以产生对抗性输入:
我们希望最大化原始输入向量的加权与扰动(改变)的加权和之间的差值。这会改变模型的激活状态,并使模型的决策过程中断。
我们希望使对抗性向量 η 的每个单独值尽可能小,这样整个图像在人眼来看没有改变。
Goodfellow 等人提出的解决方案是双管齐下的,而且相当聪明,原因有几个。
η 设置为符号 (w),其中 sign 函数对于负值返回 -1,正值返回 1(0 表示 0)。如果权重为负,则将其乘以 -1 以得到正和;如果权重为正,则乘以 1 而结果无变化。
例如,如果权重向量为[3,-5,7],η 将为[1,-1,1]。加权和为3+5+7=15。请注意,执行这个操作本质上是将负值转换为正值,而使正值保持不变(abs()函数)。这意味着每个数字都是尽可能大的,如果权重在区间内,那么就是最大可能的加权和[-1, 1]。
考虑下面的一些“图像”。尽管它们以二维形式表示的,但可以将它们视作一维向量。
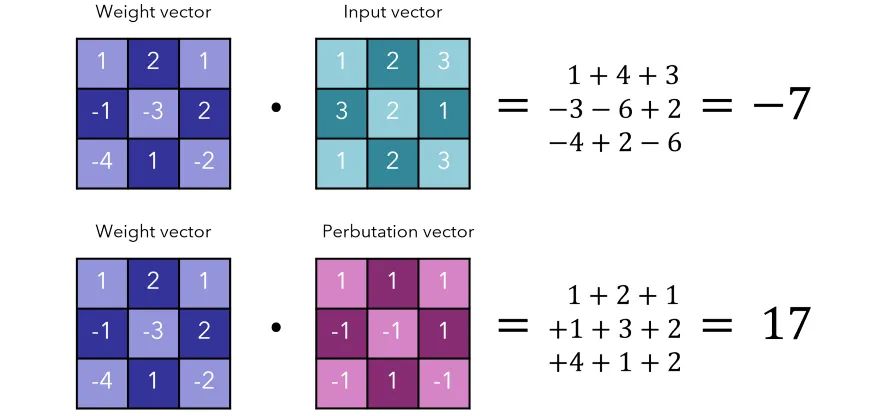
最终总和为 10,与原始输出 -7 相差很大。当然,这将会使网络的预测更加糟糕。
这样做可以达到进行较大更改的目的,但一点也不谨慎。毕竟,我们的图像在我们进行干扰的时候,发生了明显的改变:
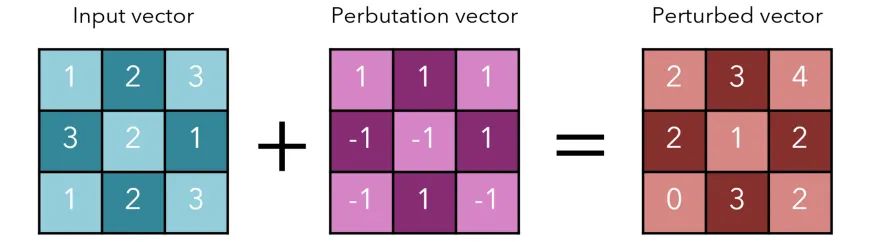
请记住,我们之前将最终总和表示为W(x) + w(η),其中w()是加权综合,η是 perbutation 向量,实际上是w(x+η)的展开。我们想要稍微改变每个像素的值,虽然总效应必须最大化,但η的每个元素都必须足够小,以至于不能被注意到。
在对抗性输入的实际产生中,像素数j被定义为x的jth 值加上η的第j个值。首先引入的表示法使用了一种简单的方式来证明η的目的,即大幅增加总和,而不一定是单个像素值。
η 的每个元素都相当大:+1 或 -1,这对适当缩放的数据有很大的影响。为了解决这个问题,我们将每个 η 元素乘以一个带符号的 ϵ,其中 ϵ 是传感器检测到的最小数值单位(或更小)。对于 8 位颜色,该数字将为 256,因此 ϵ=1/255。
因为 ϵ 是“不可检测”的(或者几乎不可检测),所以它在视觉上对图像应该没有什么不同。但是,每一个变化都是按照 sign 函数构建的,这样加权和的变化是最大的。
因此,我们将 -ϵ 或 +ϵ 添加到输入向量的每个元素上,这是一个足够小的变化,以至于它不可检测,但使用 sign 函数构造,从而使变化最大化。
许多小组件加起来可能会变得非常大,特别是如果它们是一种智能的方式构造的话。
让我们考虑一下在上一个例子中 ϵ=0.2 时这种情况的影响。我们可以得到 3 个单位的差额(总和为 -4)。
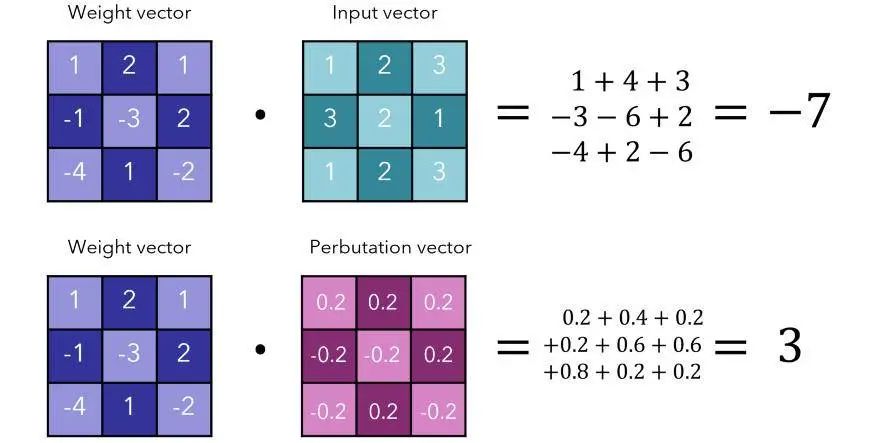
这是相当可观的,特别是考虑到 perbutation 向量对原始输入向量的微小变化。
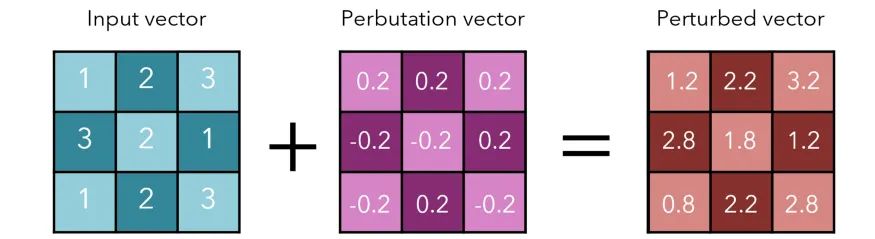
让我们考虑一下在上一个例子中 ϵ=0.2 时这种情况的影响。我们可以得到 3 个单位的差额(总和为 -4)。
如果权重向量具有 n 个维数,并且元素的平均绝对值为 m,则激活值将增长为 ϵnm。在高维图像中(如 256×256×3),n 的值为 196608。m 和 ϵ 可以非常小,但仍会对输出产生重大影响。
这种方法非常快,因为它只通过 +ϵ 或 -ϵ 来改变输入:但是它这样做的方式如此有效,以至于完全愚弄了神经网络。
在上图中,0.007 的 ϵ 对应于 GoogLeNet 转换为实数之后的 8 位图像编码的最小为的大小。来源:Goodfellow 等人。
Goodfellow 等人在应用 FGSM 时发现了有趣的结果:
ϵ=0.25 时,浅层 SoftMax 分类器的错误率为 99.9%,MNIST 上的平均置信度为 79.3%。
ϵ=0.1 时,对预处理的 CIFAR-10 的错误预测,CNN 的错误率为 87.15%,平均置信度为 96.6%。
显然,这些对抗性的输入会导致严重的错误率,但也许更令人担忧的是高置信度。这些网络不仅做出了错误的预测,还对自己错误的输出“充满了信心”。这显然是有问题的:想象一下,教一个犹豫不决回答 2×4=6 的学生和一个自豪地宣布答案的学生之间的区别。
这些对抗性的输入 / 样本可以解释为高维点积的一个特性:当需要在其中分配和的像素数量较多时,加权和可以更大,而对每个单独像素的改变也会更小。
事实上,对抗性样本是网络过于线性的结果。毕竟,这样的变化(比如说)对一个由 sigmoid 函数组成的网络的影响微乎其微,因为在大多数地方,perbutation 的影响都是递减的。具有讽刺意味的是,正是这种特性——死亡梯度(dying gradients)ReLU 和其他容易受到对抗性输入影响的无界函数的兴起。
本文中提出的其他要点包括:
最重要的是 perbutation 的方向,而不是空间中的某个特定点。这并不是说,模型在多维空间中存在“弱点”的情况;相反,在对抗性输入的构建中,perbutation 的方向才是最关键的。
因为方向是最重要的,所以对抗性结构可以泛化。由于寻找对抗性输入并不局限于探索模型的预测空间,因此,可以在集中不同类型和结构的模型上推广构造方法。
对抗性训练可以导致正则化,甚至比 Dropout 还要多。训练网络识别对抗性输入是一种有效的正则化形式,也许比 Dropout 更有效。对抗性训练的正则化效果不能通过减少权重或简单地增加权重来复制。
易于优化的模型很容易受到扰动。如果找到最佳梯度很简单,那么计算一个有效的对抗性输入同样也会很简单。
线性模型、训练以模拟输入分布的模型以及集合对抗性输入均不能抵抗对抗性输入。RBF 网络具有抵抗性。具有隐藏层的架构可以通过训练来识别对抗性输入,从而获得不同程度的成功。
走出数据集的限制性和完美条件的世界,进入不那么有序的现实世界变得越来越重要。通过发现有效的策略来欺骗我们的图像识别模型,我们就可以在它们被用于更恶意的目的之前对其进行屏蔽。
《解释和利用对抗性样本》(Explaining and Harnessing Adversarial Examples),Goodfellow 等人。该论文以比本文更严谨的数学方法禁烧了 FGSM,并对实验结果进行了深入分析,讨论了 FGSM 的卢纶解释和启示。
《建立抵抗对抗性攻击的深度学习模型》(Towards Deep Learning Models Resistant to Adversarial Attacks),Madry 等人。在 FGSM 的研究工作的基础上,开发了一种更为复杂的对抗性样本生成方法。
《TensorFlow 教程:FGSM 的对抗性样本》(TensorFlow Tutorial: Adversarial Example with FGSM)。在 TensorFlow 中实现 FGSM 的代码教程。
作者介绍:
Andre Ye,Critiq 联合创始人。机器学习、计算机科学与数学爱好者。
原文链接:
https://towardsdatascience.com/how-to-systematically-fool-an-image-recognition-neural-network-7b2ac157375d
你也「在看」吗? 以上是关于如何系统地欺骗图像识别神经网络的主要内容,如果未能解决你的问题,请参考以下文章