怎么从链接里提取师资力量
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么从链接里提取师资力量相关的知识,希望对你有一定的参考价值。
找那个高中学校的教务处,会有些数据可以参考,不过,一般不外泄露。也可以去学校,看看学校橱窗中的教师情况介绍,听一哈社会上的评价。打开目标网页(相信每个大学的每个学院官网都有这一栏信息)
在这里插入图片描述
在这里插入图片描述
可以很直观的看出,所有教师的信息保存在一个表格当中,查看网页源码验证一下自己的想法:
在这里插入图片描述
直接定位元素的源码位置,可以看出确实保存在table标签当中,再看每一个元素的位置,都是在span标签中保存,但自己观察数据和源码,会发现在名字一栏,其若是两个字的名字的话,中间是由空格隔开的,这对于使用xpath提取的话,在进行数据清洗保存的时候会比较麻烦,而且下面的有数据为空,对于爬取下来的数据进行分类也比较麻烦。我采用了一种简单粗暴的方法用来提取这表格保存的数据,下面我会给出解决的方法。
在这里插入图片描述
2. 暴力爬取表格存储的教师信息
此次爬取使用的是Scrapy框架。
2.1 创建工程
scrapy startproject rjxyInfo
2.2 创建Spider
在Pycharm下端的Terminal中执行即可:(可以指定域名)
scrapy genspider rjxy
2.3 暴力爬取表格信息
2.3.1 分析如何爬取
网页的源码并没有什么特殊的地方,但是在使用xpath爬取的时候,直接进行爬取,会因为源码在编写的时候使用了回车符,或者有的表格中的信息没有填写,直接进行爬取返回的数据不易整理成组存入数据库。但通过直接查看其xpath源码,会发现其中的规律:
# 性别
# //*[@id="vsb_content"]/div/div/table/tbody/tr[2]/td[3]/p/span
# //*[@id="vsb_content"]/div/div/table/tbody/tr[103]/td[3]/p/span
# 序号
# //*[@id="vsb_content"]/div/div/table/tbody/tr[2]/td[1]/p/span
# //*[@id="vsb_content"]/div/div/table/tbody/tr[103]/td[1]/p/span
# 姓名
# result = ''.join(response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[3]/td[2]/p/span/text()').extract()).strip()
# 毕业学校
# //*[@id="vsb_content"]/div/div/table/tbody/tr[2]/td[5]/p/span
# 现从事专业
# //*[@id="vsb_content"]/div/div/table/tbody/tr[2]/td[6]/p/span
# 备注
# //*[@id="vsb_content"]/div/div/table/tbody/tr[2]/td[7]/p/span
2.3.2 编写spider中的parse()方法
def parse(self, response):
for i in range(2,104):
i = str(i)
item = TeachersItem()
item['id'] = response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i + ']/td[1]/p/span/text()').extract()
item['name'] = ''.join(response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[2]/p/span/text()').extract()).strip()
item['sex'] = ''.join(response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[3]/p/span/text()').extract()).strip()
item['degree'] = response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[4]/p/span/text()').extract()
item['graduated_school'] = ''.join(response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[5]/p/span/text()').extract()).strip()
item['now_Teachproject'] = ''.join(response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[6]/p/span/text()').extract()).strip()
item['remark'] = response.xpath('//*[@id="vsb_content"]/div/div/table/tbody/tr[' +i+ ']/td[7]/p/span/text()').extract()
yield item
3. 将数据存入数据库
class PymysqlPipeline(object):
#连接数据库
def __init__(self):
self.connect = pymysql.connect(
host = 'localhost',
database = 'teachersinfo',
user = 'root',
password = '123456',
charset = 'utf8',
port = 3306
)
# 创建游标对象
self.cursor = self.connect.cursor()
# 此方法是必须要实现的方法,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理
def process_item(self,item,spider):
# 判断item是哪一类的item
cursor = self.cursor
sql = 'insert into teachers(id,name,sex,degree,graduated_school,now_Teachproject,remark) values (%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['id'],item['name'],item['sex'],item['degree'],item['graduated_school'],item['now_Teachproject'],item['remark'],
))
# 提交数据库事务
self.connect.commit()
return item
4. 通过sql语言查询,得到数据进行数据可视化
4.1 sql语言查询举例
4.2 全部老师男女比例(柱状图)
4.3 专职老师男女比例(柱状图)
4.4 师资力量(柱状图)
4.5 师资力量(饼图)
4.6 不同备注教师比例(柱状图)
4.7 不同备注教师比例(饼图)
4.8 教师毕业大学整合(柱状图) 参考技术A 从链接里提取师资力量的方法:
1.选取有价值的链接。
2.打开链接,找到里面有关师资力量的信息。
3.将有价值的信息复制出来。
4.将复制的信息进行分类整理。 参考技术B 1通过session.get()命令与r.html.text命令获取并将指定网页内容转换为字符串格式(下面简称该字符串为string);
2.由于本次爬取内容较为简单,网页内容格式也较为固定,因此在string中寻找指定起始字符位置和结束字符位置,这里选取的参考位置是导师名单前的字符串"Y\nZ\nA\n"和名单后的字符串" _showDynClickBatch(['dynclicks"来定位;
3.由于导师名单字符串的格式恰好为四个字符中有一个导师姓名,因此以四个字符为一组的方式拆分名单字符串,删去空格后加入对应的名单list中; 参考技术C 1通过session.get()命令与r.html.text命令获取并将指定网页内容转换为字符串格式(下面简称该字符串为string);
2.由于本次爬取内容较为简单,网页内容格式也较为固定,因此在string中寻找指定起始字符位置和结束字符位置,这里选取的参考位置是导师名单前的字符串"Y\nZ\nA\n"和名单后的字符串" _showDynClickBatch(['dynclicks"来定位;
3.由于导师名单字符串的格式恰好为四个字符中有一个导师姓名,因此以四个字符为一组的方式拆分名单字符串,删去空格后加入对应的名单list中; 参考技术D 官网查看。
1、首先登陆大学官网。
2、在主页就能看到师资力量。
3、点击就可以进入师资力量的页面。
4、在页面里就可以看到教师的简历了。
美剧神车《邪恶力量》雪佛兰Impala肌肉车
更多车坛资讯趣闻,↑↑↑关注好购汽车
看过美剧邪恶力量的人相信都对那台大马力肌肉车印象非常深刻。
这是一台1967年的雪佛兰Impala。

在故事里,这台经典老车是迪恩的父亲留下。

据悉其采用了4.1L的V8发动机,百公里加速为9秒,极速超过200公里。

既然是抓鬼,经典的后备箱武器库怎么能少?不过遗憾的是这些武器都不能直接从车里取出,万一鬼飘进车厢怎么办?


喜欢这车的相信更关心价格,查了一下该车在ebay上的售价:
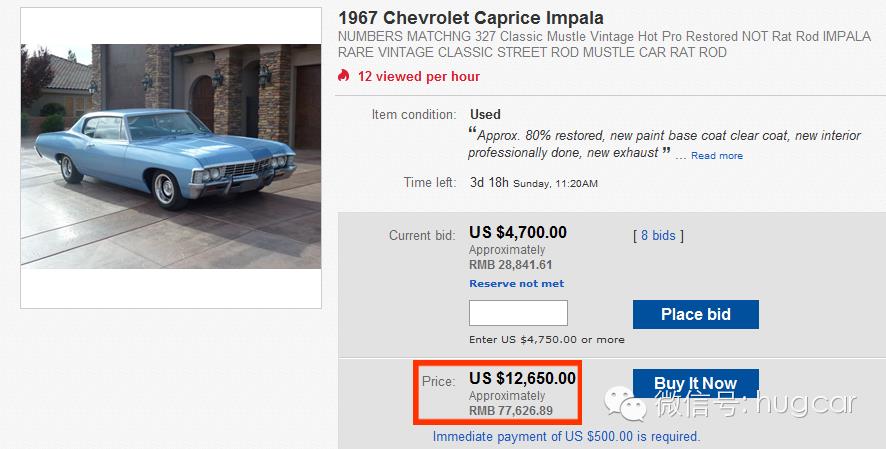
好了,现在该上主角了。



不好意思,不小心穿越了。。。。
以上是关于怎么从链接里提取师资力量的主要内容,如果未能解决你的问题,请参考以下文章