图像识别中的卷积神经网络
Posted 毕老师大家庭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别中的卷积神经网络相关的知识,希望对你有一定的参考价值。
深度卷积神经网络(ConvolutionalNeural Networks, CNN)解决了传统神经网络参数量过大的问题,为图像分类实现了突破。CNN在层级网络结构的基础上,以端到端的多层方式集成了不同的功能,并且功能的“级别”可以通过神经网络的层数(深度)来丰富。得益于CNN卓越的模型性能,目前图像识别技术几乎都是以CNN模型来进行训练。目前经典的卷积神经网络模型有以下几种:
图中表达了LeNet-5的结构:首先是一个5*5*6的卷积层,紧跟着是一个2*2*6的池化层,然后便是一个5*5*16的卷积层和2*2*16的池化层,最后跟着两个长度分别为120,84的全连接层和一个长度为10的输出层。
LeNet-5的结构简单,它的深度也和目前动辄几十层上百层的CNN模型比起来显得比较贫瘠,但后来的神经网络都是在它的结构上进行扩张加深。LeNet-5用简单的结构表现出了卷积神经网络的三个要点:局部感受野、权值共享和下采样。这三个要点也解释了为什么CNN能够在结构更复杂的情况下拥有更少的参数和训练准确率。
2.AlexNet
Krizhevsky等人提出了AlexNet,这是一种LeNet-5的扩展模型,因为AlexNet首次将CNN用于计算机视觉领域中的ImageNet数据集而被广为人知,从此揭开了CNN应用于计算机视觉领域的序幕。
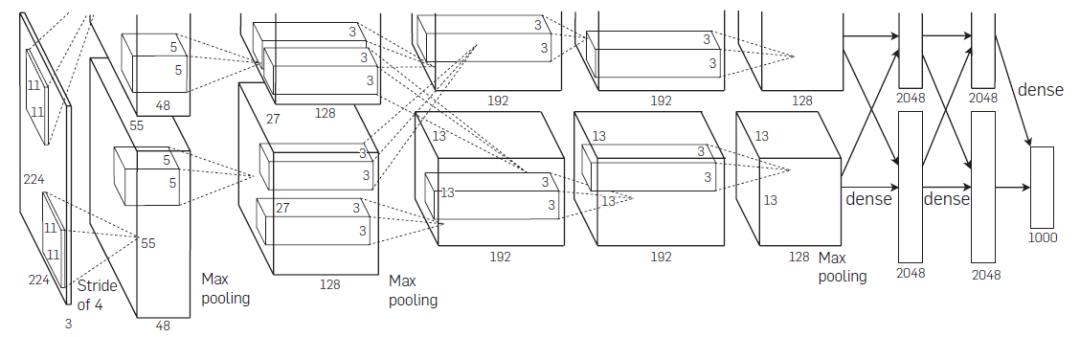
尽管AlexNet相比于LeNet-5仅在结构上进行了加深,但得益于硬件GPU强大的计算力,纵使是在大数据的情况下,GPU可以帮助研究者将原本需要数周乃至数月的网络训练过程缩短至短短几天,这无疑大大缩短了深度网络研究的时间成本。
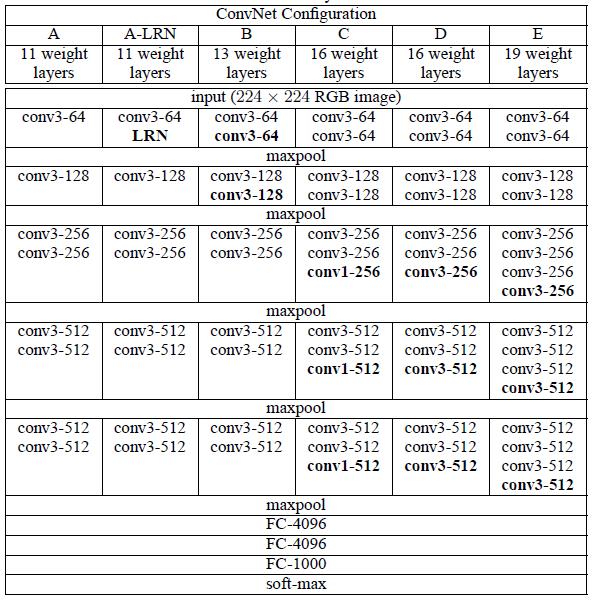
3.VGGNet
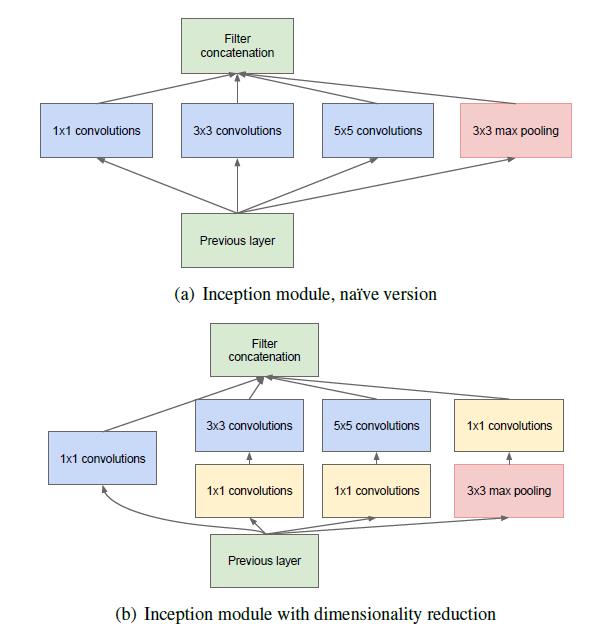
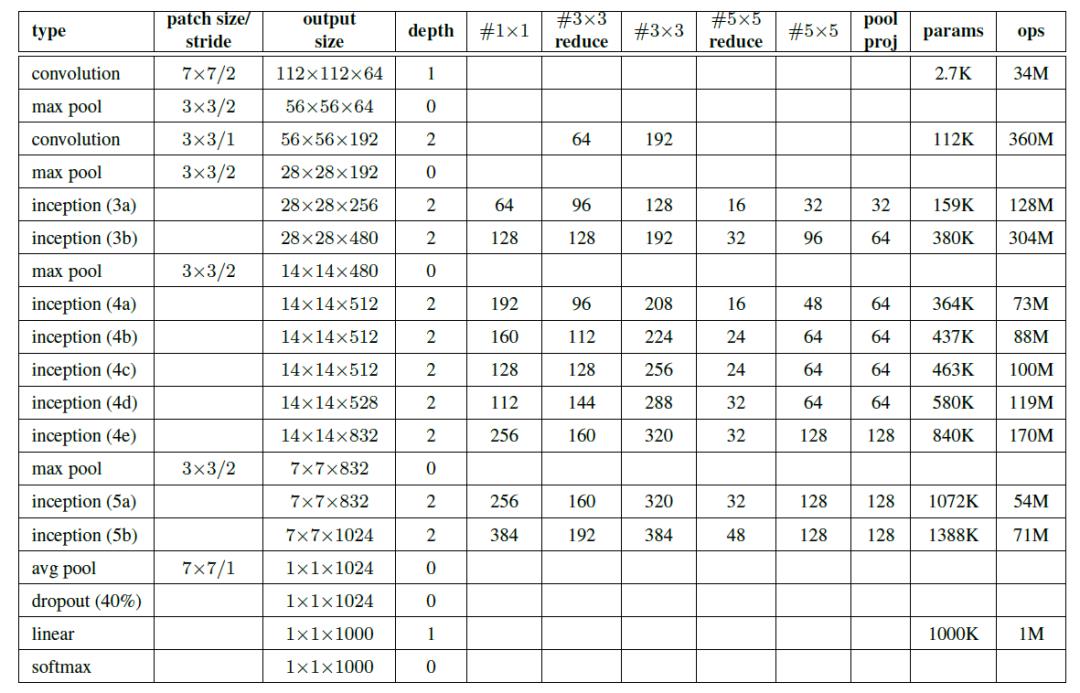
5.ResNet
如图所示,x为浅层的输出,H(x)为更深层映射的输出,F(x)为夹在二者中间的两层代表的变换。残差结构复制x加给F(x),映射关系就变换为H(x):=F(x)+x。假设x代表的特征映射已经足够成熟,那么在结构中,若任何对于x的改变都会使得损失变大,F(x)会自动趋于0,使x能够从恒等映射的路径中继续传递。这样就在不增加计算成本的情况下实现了最初的目的:在前向链路中,当浅层的输出已经优化到一定程度时,让深层网络后面的层能够实现恒等映射的作用。
参考文献:
[1]A. Krizhevsky,I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neuralnetworks. In NIPS, 2012.
[2] LeCun et al. Grandient-based learningapplied to document recognition. THE IEEE,VOL. 86, NO. 11, NOVEMBER 1998.
[3] K. Simonyan, A. Zisserman. Very deepconvolutional networks for large-scale image recognition. In ICLR, 2015.
[4] Szegedy et al. Going deeper withconvolutions s[C]//Proceedings of the IEEE conference on computervision and pattern recognition.2015:1-9.
[5] He K, Zhang X, Ren S, et al. Deep ResidualLearning for Image Recognition. s[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition.2016:770-778.
以上是关于图像识别中的卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章