Hadoop、Spark、Flink概要
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop、Spark、Flink概要相关的知识,希望对你有一定的参考价值。
参考技术A 当前大数据的数据量已达PB级别(1PB=1024TB),可以说是庞大无比。同时数据还有 结构化 (如数字、符号等)、 非结构化 (如文本、图像、声音、视频等)之分,兼具大量、复杂的特点,使得如何又快又好又便宜得进行大数据的存储,管理和处理变成一个亟待解决的问题。于是 分布式计算 作为一种低成本的方案被提出来了。原理就是把一组计算机通过网络相互连接组成分散系统,尽管分散系统内的单个计算机的计算能力不强,但是每个计算机只计算一部分数据,多台计算机同时计算,最后将这些计算结果合并得到最终的结果。就整个分散系统而言,处理数据的速度远高于单个计算机,且比集中式计算的大型机要划算的多。
为什么是他们,这要从谷歌的三篇论文说起...
2003年到2004年间,Google发表了三篇技术论文,提出了一套分布式计算理论,分别是:
但由于Google没有开源,所以其他互联网公司根据Google三篇论文中提到的原理,对照MapReduce搭建了 Hadoop , 对照GFS搭建了 HDFS ,对照BigTable搭建了 HBase.
即:
而 Spark 分布式计算是在Hadoop分布式计算的基础上进行的一些架构上的改良。目前也是Hadoop生态圈的成员之一。
Spark与Hadoop最大的不同点在于,Hadoop用 硬盘 存储数据,而Spark用 内存 存储数据,所以Spark能提供超过Hadoop100倍的运算速度。但因为内存断电后会丢失数据,所以Spark不能用于处理需要长期保存的数据。
Flink是目前唯一同时支持高吞吐、低延迟、高性能的分布式流式数据处理框架。一般需要实时处理的场景都有他的身影,比如:实时智能推荐、实时复杂事件处理、实时欺诈检测、实时数仓与ETL、实时报表分析等
广义的Hadoop不再是单指一个分布式计算系统,而是一套生态系统。
那么,这套生态圈是如何产生的呢?
在有了Hadoop之类计算系统的基础上,人们希望用更友好的语言来做计算,于是产生了Hive、Pig、SparkSQL等。计算问题解决了,还能在什么地方进一步优化呢?于是人们想到给不同的任务分配资源,于是就有了Yarn、Oozie等。渐渐地,随着各种各样的工具出现,就慢慢演变成一个包含了文件系统、计算框架、调度系统的Hadoop大数据生态圈。
附:一些其他的组件示意
Kafka:是一种高吞吐量的分布式发布订阅消息系统,它可以处理各大网站或者App中用户的动作流数据。用户行为数据是后续进行业务分析和优化的重要数据资产,这些数据通常以处理日志和日志聚合的方式解决。
Kafka集群上的消息是有时效性的,可以对发布上来的消息设置一个过期时间,不管有没有被消费,超过过期时间的消息都会被清空。例如,如果过期时间设置为一周,那么消息发布上来一周内,它们都是可以被消费的,如果过了过期时间,这条消息就会被丢弃以释放更多空间。
Oozie:是一个工作流调度系统,统一管理工作流的调度顺序、安排任务的执行时间等,用来管理Hadoop的任务。Oozie集成了Hadoop的MapReduce、Pig、Hive等协议以及Java、Shell脚本等任务,底层仍然是一个MapReduce程序。
ZooKeeper:是Hadoop和HBase的重要组件,是一个分布式开放的应用程序协调服务,主要为应用提供配置维护、域名服务、分布式同步、组服务等一致性服务。
YARN:Hadoop生态有很多工具,为了保证这些工具有序地运行在同一个集群上,需要有一个调度系统进行协调指挥,YARN就是基于此背景诞生的资源统一管理平台。
Flink学习之flink sql
🌰 昨天我们学习完Table API后,今天我们继续学SQL,Table API和SQL可以处理SQL语言编写的查询语句,但是这些查询需要嵌入用Java、Scala和python编写的程序中。
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🌱flink sql只需要具备 SQL 的基础知识即可,不需要其他编程经验。我的SQL 客户端选择的是docker安装的Flink SQL Click,大家根据自己的需求安装即可。
目录
1. SQL客户端
SQL客户端内置在Flink的版本中,大家只要启动即可,我使用的是docker环境中配置的Flink SQL Click,让我们测试一下:

输入’helloworld’ 看看输出的结果。
SELECT ‘hello world’;
结果如下:说明运行成功!

2. SQL语句
2.1 create
CREATE 语句用于向当前或指定的 Catalog 中注册表、视图或函数。注册后的表、视图和函数可以在 SQL 查询中使用。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
<physical_column_definition> | <metadata_column_definition> | <computed_column_definition> [ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] ]
-- 例如
CREATE TABLE Orders_with_watermark (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'latest-offset'
);
2.2 drop
DROP 语句可用于删除指定的 catalog,也可用于从当前或指定的 Catalog 中删除一个已经注册的表、视图或函数。
--删除表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
--删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
--删除视图
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
--删除函数
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
2.3 alter
ALTER 语句用于修改一个已经在 Catalog 中注册的表、视图或函数定义。
--修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
--设置或修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
--修改视图名
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
--在数据库中设置一个或多个属性。若个别属性已经在数据库中设定,将会使用新值覆盖旧值。
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
2.4 insert
INSERT 语句用来向表中添加行(INTO是追加,OVERWRITE是覆盖)
-- 1. 插入别的表的数据
INSERT INTO | OVERWRITE [catalog_name.][db_name.]table_name [PARTITION part_spec] select_statement
-- 2. 将值插入表中
INSERT INTO | OVERWRITE [catalog_name.][db_name.]table_name VALUES [values_row , values_row ...]
-- 追加行到该静态分区中 (date='2019-8-30', country='China')
INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 追加行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT INTO country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
-- 覆盖行到静态分区 (date='2019-8-30', country='China')
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 覆盖行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
2.5 show
show用于列出所有的catalog、database、function等
-- 列出catalog
SHOW CATALOGS;
-- 列出数据库
SHOW DATABASES;
--列出表
SHOW TABLES;
-- 列出视图
SHOW VIEWS;
--列出函数
SHOW FUNCTIONS;
-- 列出所有激活的 module
SHOW MODULES;
3. Window Functions
这里的Window Functions不是指我们sql中的窗口函数,是指处理流数据中特有的窗口操作。
3.1 滚动窗口 TUMBLE
TUMBLE函数把行分配到有固定间隔时间且不重叠的窗口上,滚动窗口在批处理和流处理可以定义在事件时间上,但只有流处理可以定义在处理时间上。

--1. TUMBLE函数的参数
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2.实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.2 滑动窗口 HOP
滑动窗口在批处理和流处理中可以定义在事件时间上,但只有流处理可以定义在处理时间上。(数据会有重复)
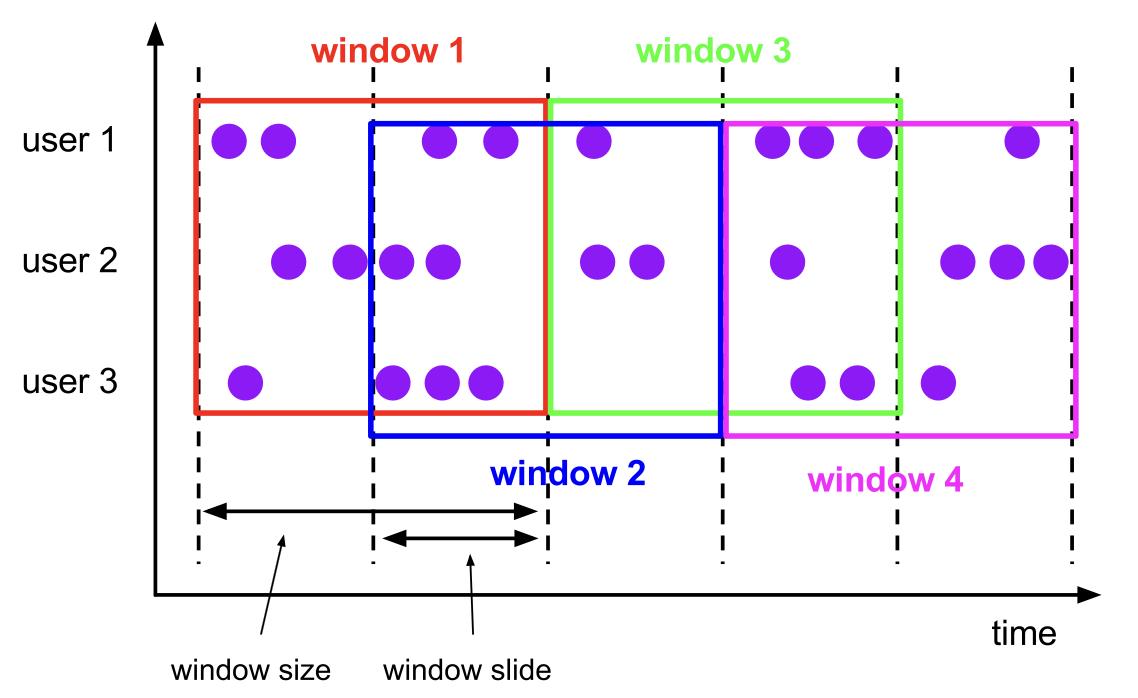
-- 1. HOP函数的参数
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- slide:指窗口滑动的大小
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2.实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.3 累计窗口 CUMULATE
累计窗口是指在固定窗口内,每隔一段时间触发操作。类似于滚动窗口内定时进行累计操作。
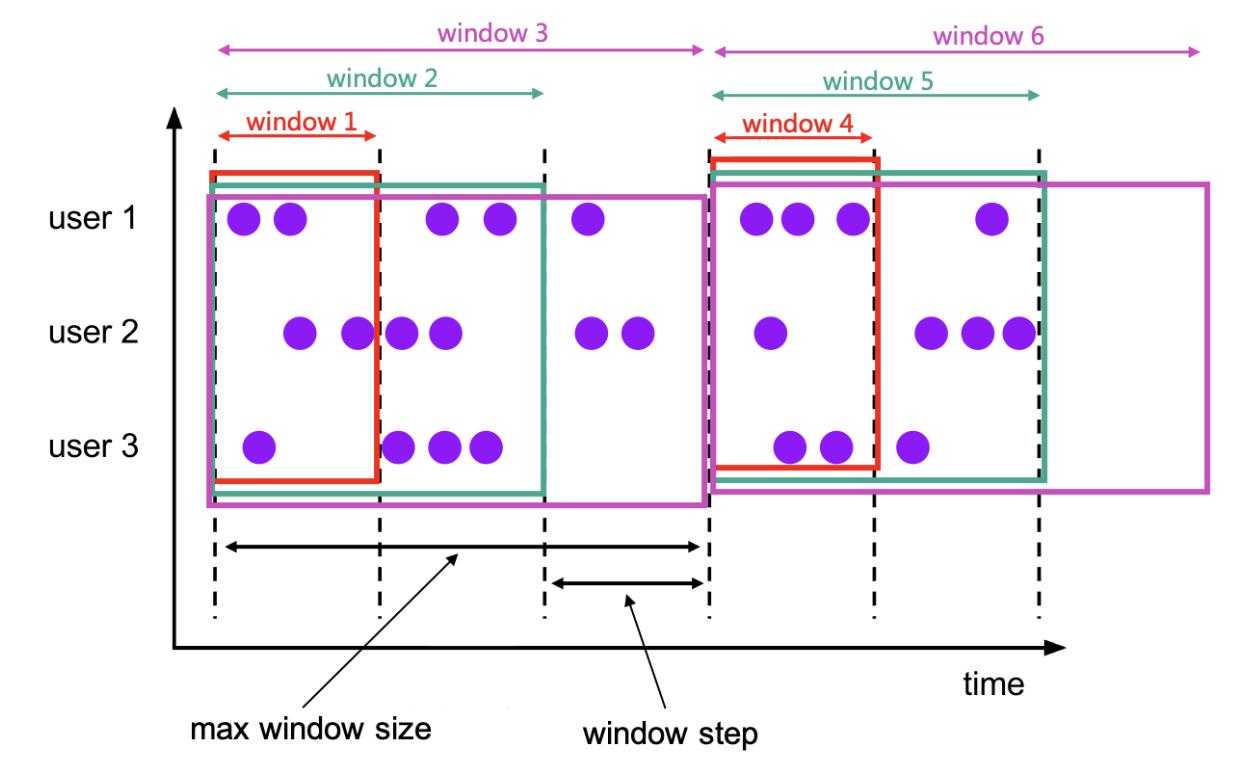
--1. 累计窗口的参数
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
--data: 和时间有关的数据源
--timecol: 时间列,数据的哪些时间属性列应该映射到滚动窗口。
--step: 是指定顺序累积窗口结束之间增加的窗口大小的持续时间。
--size: 是指定累积窗口最大宽度的持续时间。size 必须是 step 的整数倍。
-- offset:可增加其他参数,会有特别的意义
-- 实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
4. 其他函数
处理上述这些,剩下还有的操作都是和我们的SQL语法差不多,就不再阐述:
- 窗口聚合函数:group by、…
- 分组聚合函数:count、having、count(distinct xxx)、…
- over聚合函数:over(partition by xxx order by xxx)、…
- 内外连接函数:join、left join 、outer join、…
- limit 函数
- TOP-N函数: rank()、dense_rank()、row_number()
对以上内容感兴趣的小伙伴可以参考如下链接:
- SQL教程: SQL专题-各部分函数讲解.
5. 总结
今天学习的sql,和往常不一样的地方在于,以往的sql都是处理的是批数据,而今天学习的flink sql可以处理流数据,流数据随着时间的变化而变化,flink sql可以对流数据进行类似表一样的处理,可以实现大部分DataStream API和DataSet API的功能。
😂还有就是,flink sql中的窗口函数和我们传统的窗口函数不一样,按理来说,我们正常的窗口函数应该叫over聚合函数。
6. 参考资料
《Flink入门与实战》
《PyDocs》(pyflink官方文档)
《Kafka权威指南》
《Apache Flink 必知必会》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Hadoop、Spark、Flink概要的主要内容,如果未能解决你的问题,请参考以下文章
大数据最全的大数据Hadoop|Yarn|Spark|Flink|Hive技术书籍分享/下载链接,持续更新中...
大数据云计算高级实战Hadoop,Flink,Spark,Kafka,Storm,Docker高级技术大数据和Hadoop技能