Redis的各数据类型的内存占用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis的各数据类型的内存占用相关的知识,希望对你有一定的参考价值。
参考技术A 先给一个Redis分析内存占用的网址: http://www.redis.cn/redis_memory/这个工具会给我们一个内存占用分析,示例如下图:
我们在使用Redis的时候,String 类型是我们使用最多的,他也是唯一的一个非集合类型。
然而String类型并不是适用于所有场合的,它有一个明显的短板,就是它保存数据时所消耗的内存空间较多。
为什么String类型的占用的空间比较大呢,那是因为他除了记录实际数据,String 类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了。
当你保存 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。但是,当你保存的数据中包含字符时,String 类型就会用简单动态字符串(Simple Dynamic String,SDS)结构体来保存。
其中SDS的保存占用的内存如下所示:
在 SDS 中,buf 保存实际数据,而 len 和 alloc 本身其实是 SDS 结构体的额外开销。
然而,除了SDS的额外开销,String类型还有一个RedisObject 结构体(包含了八个字节的元数据和八个字节的指针)的开销,如下图所示:
为了解决上面提到的String类型占用内存过多的情况,我们可以使用压缩表来存储。
压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。
Redis 基于压缩列表实现了 List、Hash 和 Sorted Set 这样的集合类型,这样做的最大好处就是节省了 dictEntry 的开销。当你用 String 类型时,一个键值对就有一个 dictEntry,要用 32 字节空间。但采用集合类型时,一个 key 就对应一个集合的数据,能保存的数据多了很多,但也只用了一个 dictEntry,这样就节省了内存。
Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。这两个阈值分别对应以下两个配置项:
hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
Redis 的数据被删除,为什么占用内存没减少?
通过 CONFIG SET maxmemory 100mb或者在 redis.conf 配置文件设置 maxmemory 100mb Redis 内存占用限制。当达到内存最大值值,会触发内存淘汰策略。
除此之外,当 key 达到过期时间,Redis 会有以下两种删除过期数据的策略:
- 后台定时任务选取部分数据删除;
- 惰性删除。
答案是:可能依然占用了大约 5GB 的内存,即使 Redis 的数据只占用了 3GB 左右。
大家一定要设置maxmemory,否则 Redis 会继续为新写入的数据分配内存,无法分配就会导致应用程序报错,当然不会导致宕机。
释放的内存去哪了
内存都去哪了?使用 info memory 命令获取 Redis 内存相关指标,我列举了几个重要的数据:
127.0.0.1:6379> info memory
# Memory
used_memory:1132832 // Redis 存储数据占用的内存量
used_memory_human:1.08M // 人类可读形式返回内存总量
used_memory_rss:2977792 // 操作系统角度,进程占用的物理总内存
used_memory_rss_human:2.84M // used_memory_rss 可读性模式展示
used_memory_peak:1183808 // 内存使用的最大值,表示 used_memory 的峰值
used_memory_peak_human:1.13M // 以可读的格式返回 used_memory_peak的值
used_memory_lua:37888 // Lua 引擎所消耗的内存大小。
used_memory_lua_human:37.00K
maxmemory:2147483648 // 能使用的最大内存值,字节为单位。
maxmemory_human:2.00G // 可读形式
maxmemory_policy:noeviction // 内存淘汰策略
// used_memory_rss / used_memory 的比值,代表内存碎片率
mem_fragmentation_ratio:2.79
Redis 进程内存消耗主要由以下部分组成:
- Redis 自身启动所占用的内存;
- 存储对象数据内存;
- 缓冲区内存:主要由 client-output-buffer-limit 客户端输出缓冲区、复制积压缓冲区、AOF 缓冲区。
- 内存碎片。
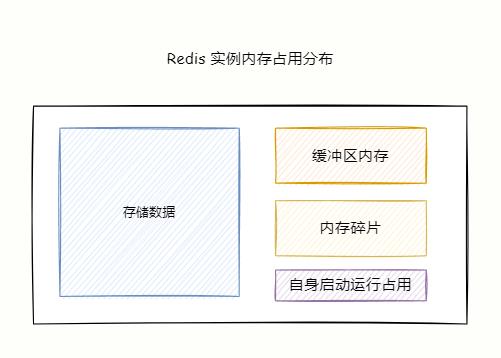
Redis 自身空进程占用的内存很小可以忽略不计,对象内存是占比对打的一块,里面存储着所有的数据。
缓冲区内存在大流量场景容易失控,造成 Redis 内存不稳定,需要重点关注。
内存碎片过大会导致明明有空间可用,但是却无法存储数据。
碎片 = used_memory_rss 实际使用的物理内存(RSS 值)除以 used_memory 实际存储数据内存。
什么是内存碎片
内存碎片会造成明明有内存空间空闲,可是却无法存储数据。举个例子,你跟漂亮小姐姐去电影院看电影,肯定想连在一块坐。
假设现在有 8 个座位,已经卖出了 4 张票,还有 4 张可以买。可是好巧不巧,买票的人很奇葩,分别间隔一个座位买票。
即使还有 4 个座位空闲,可是你却买不到两个座位连在一块的票,厚礼蟹!
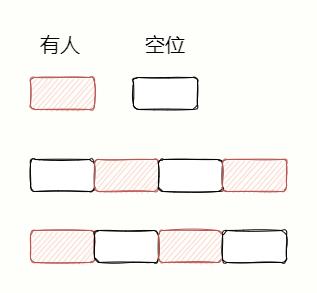
内存碎片形成原因
主要有两个原因:
- 内存分配器的分配策略。
- 键值对的大小不一样和删改操作:Redis 频繁做更新操作、大量过期数据删除,释放的空间(不够连续)无法得到复用,导致碎片率上升。
接下来我分别探讨实际发生的原因……
内存分配器的分配策略
Redis 默认的内存分配器采用 jemalloc,可选的分配器还有:glibc、tcmalloc。
内存分配器并不能做到按需分配,而是采用固定范围的内存块进行分配。
例如 8 字节、16 字节…..,2 KB,4KB,当申请内存最近接某个固定值的时候,jemalloc 会给它分配最接近固定值大小的空间。
这样就会出现内存碎片,比如程序只需要 1.5 KB,内存分配器会分配 2KB 空间,那么这 0.5KB 就是碎片。
这么做的目的是减少内存分配次数,比如申请 22 字节的空间保存数据,jemalloc 就会分配 32 字节,如果后边还要写入 10 字节,就不需要再向操作系统申请空间了,可以使用之前申请的 32 字节。
删除 key 的时候,Redis 并不会立马把内存归还给操作系统,出现这个情况是因为底层内存分配器管理导致,比如大多数已经删除的 key 依然与其他有效的 key分配在同一个内存页中。
另外,分配器为了复用空闲的内存块,原有 5GB 的数据中删除了 2 GB 后,当再次添加数据到实例中,Redis 的 RSS 会保持稳定,不会增长太多。
因为内存分配器基本上复用了之前删除释放出来的 2GB 内存。
键值对大小不一样和删改操作
由于内存分配器是按照固定大小分配内存,所以通常分配的内存空间比实际数据占用的大小多一些,会造成碎片,降低内存的存储效率。
另外,键值对的频繁修改和删除,导致内存空间的扩容和释放,比如原本占用 32 字节的字符串,现在修改为占用 20 字节的字符串,那么释放出的 12 字节就是空闲空间。
如果下一个数据存储请求需要申请 13 字节的字符串,那么刚刚释放的 12 字节空间无法使用,导致碎片。
碎片最大的问题:空间总量足够大,但是这些内存不是连续的,可能大致无法存储数据。
内存碎片解决之道
首先要确定是否发生了内存碎片,重点关注前面 INFO memory 命令提示的 mem_fragmentation_ratio 指标,表示内存碎片率:
mem_fragmentation_ratio = used_memory_rss/ used_memory
如果 1 < 碎片率 < 1.5,可以认为是合理的,而大于 1.5 说明碎片已经超过 50%,我们需要采取一些手段解决碎片率过大的问题。
重启大法
最简单粗暴的方式就是重启,如果没有开启持久化,数据会丢失。
开启持久化的话,需要使用 RDB 或者 AOF 恢复数据,如果只有一个实例,数据大的话会导致恢复阶段长时间无法提供服务,高可用大打折扣。
自动清理内存碎片
既然你都叫我靓仔了,就倾囊相助告诉你终极杀招:Redis 4.0 版本后,自身提供了一种内存碎片清理机制。
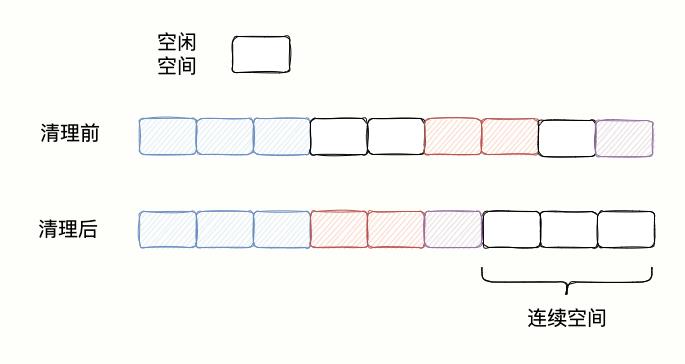
很简单,还是上面的例子,想要买两张连在一块的电影票。与与别人沟通调换下位置,就实现了。
对于 Redis 来说,当一块连续的内存空间被划分为好几块不连续的空间的时候,操作系统先把数据以依次挪动拼接在一块,并释放原来数据占据的空间,形成一块连续空闲内存空间。。
如下图所示:
自动清理内存碎片的代价
自动清理虽好,可不要肆意妄为,操作系统把数据移动到新位置,再把原有空间释放是需要消耗资源的。
Redis 操作数据的指令是单线程,所以在数据复制移动的时候,只能等待清理碎片完成才能处理请求,造成性能损耗。
好问题,通过以下两个参数来控制内存碎片清理和结束时机,避免占用 CPU 过多,减少清理碎片对 Redis 处理请求的性能影响。
开启自动内存碎片清理
CONFIG SET activedefrag yes
这只是开启自动清理,何时清理要同时满足以下两个条件才会触发清理操作。
清理的条件
active-defrag-ignore-bytes 200mb:内存碎片占用的内存达到 200MB,开始清理;
active-defrag-threshold-lower 20:内存碎片的空间占惭怍系统分配给 Redis 空间的 20% ,开始清理。
避免对性能造成影响
清理时间有了,还需要控制清理对性能的影响。由一项两个设置先分配清理碎片占用的 CPU 资源,保证既能正常清理碎片,又能避免对 Redis 处理请求的性能影响。
active-defrag-cycle-min 20:自动清理过程中,占用 CPU 时间的比例不低于 20%,从而保证能正常展开清理任务。
active-defrag-cycle-max 50:自动清理过程占用的 CPU 时间比例不能高于 75%,超过的话就立刻停止清理,避免对 Redis 的阻塞,造成高延迟。
总结
如果你发现明明 Redis 存储数据的内存占用远小于操作系统分配给 Redis 的内存,而又无法保存数据,那可能出现大量内存碎片了。
通过 info memory 命令,看下内存碎片mem_fragmentation_ratio 指标是否正常。
那么我们就开启自动清理并合理设置清理时机和 CPU 资源占用,该机制涉及到内存拷贝,会对 Redis 性能造成潜在风险。
如果遇到 Redis 性能变慢,排查下是否由于清理碎片导致,如果是,那就调小 active-defrag-cycle-max 的值。
码哥创建了技术群摸鱼群,想要与各个城市的程序员一起摸鱼打屁聊人生学技术就加群吧。
最后,可以我叫我一声靓仔么?你有什么问题想对码哥说么?在留言区留言吧,知无不言。
点赞、收藏、分享走起!
以上是关于Redis的各数据类型的内存占用的主要内容,如果未能解决你的问题,请参考以下文章