Spark实践|如何让CDSW的PySpark自动适配Python版本
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark实践|如何让CDSW的PySpark自动适配Python版本相关的知识,希望对你有一定的参考价值。
在CDH集群中Spark2的Python环境默认为Python2,CDSW在启动Session时可以选择Engine Kernel版本Python2或者Python3。当选择Python3启动Session时,开发PySpark作业在运行时会报“Python in worker has different version 2.7 than that in driver 3.6, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set”,为解决Python版本适配的问题,需要进行如下调整来使我们的应用自动的适配Python版本。
基于CDH提供的Anaconda Parcels包来安装Python,通过在CDH集群同时安装两个Python版本的Parcel包来解决多个版本的问题。如果需要在Spark中默认的支持Python2或者Python3版本则激活相应版本的Parcel即可,在我的集群默认激活的为Python2版本的Parcel包,在接下来的操作主要介绍Python3的环境准备。
Spark2默认使用的Python2环境变量
https://repo.anaconda.com/pkgs/misc/parcels/Anaconda-2019.07-el7.parcel
https://repo.anaconda.com/pkgs/misc/parcels/Anaconda-2019.07-el7.parcel.sha
https://repo.anaconda.com/pkgs/misc/parcels/manifest.json
https://repo.anaconda.com/pkgs/misc/parcels/archive/Anaconda-5.1.0.1-el7.parcel
https://repo.anaconda.com/pkgs/misc/parcels/archive/Anaconda-5.1.0.1-el7.parcel.sha
https://repo.anaconda.com/pkgs/misc/parcels/archive/manifest.json
3.将下载好的parcel包部署到集群的私有HTTP服务上



上述操作不需要激活,在不激活的情况下PySpark默认使用的Python2环境,如果激活则使用的是Python3环境。
6.确认集群所有节点已存在Python2和Python3的环境

为了能让我们的Pyspark程序代码自动适配到不同版本的Python,需要在我们的Spark代码初始化之前进行环境的初始化,在代码运行前增加如下代码实现适配不同版本的Python。
import os
py_environ=os.environ['CONDA_DEFAULT_ENV']
if py_environ=='python2.7':
os.environ['PYSPARK_PYTHON'] = '/opt/cloudera/parcels/Anaconda/bin/python'
else:
os.environ['PYSPARK_PYTHON'] = '/opt/cloudera/parcels/Anaconda-5.1.0.1/bin/python'
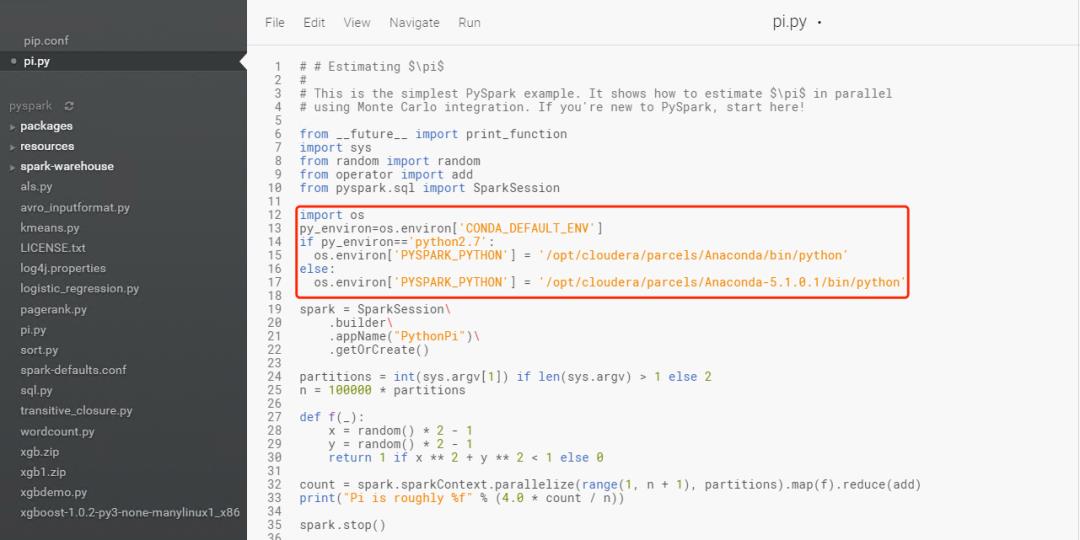
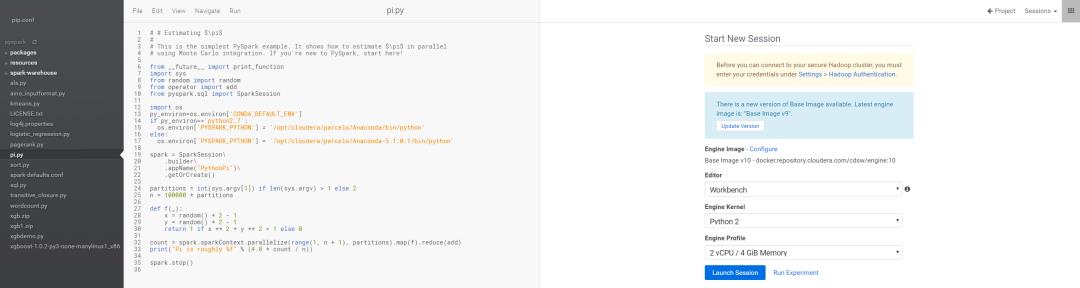
1.选择Python2环境启动Session
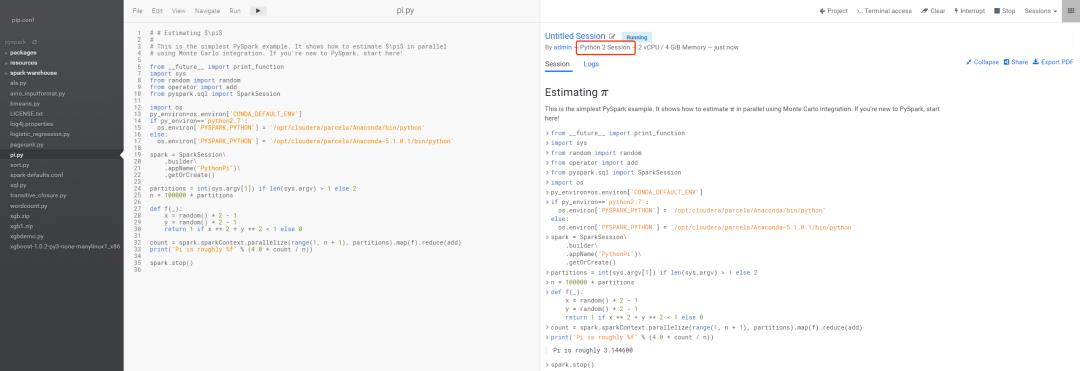
2.运行PySpark作业测试正常运行
3.选择Python3环境启动Session
4.运行PySpark作业测试正常运行
在集群中同时部署多个版本的Python,通过在Pyspark代码中使用Python命令动态的指定PYSPARK_PYTHON为我们需要的Python环境即可。
以上是关于Spark实践|如何让CDSW的PySpark自动适配Python版本的主要内容,如果未能解决你的问题,请参考以下文章
在 Python/PySpark 中 Spark 复制数据框列的最佳实践?
在单个 spark 数据框中减去两个字符串列的最佳 PySpark 实践是啥?
基于在 DataBrick 中的笔记本顶部提取小部件值来动态检索/过滤 Spark 框架的最佳 PySpark 实践是啥?