机器学习——k近邻算法原理分析与python代码实现
Posted python学习与大数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——k近邻算法原理分析与python代码实现相关的知识,希望对你有一定的参考价值。
一、KNN算法分析
K近邻分类算法是一种常用的监督学习方法。它采用测量不同特征值之间的距离方法进行分类。它的原理很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。用我们熟知的一个成语来概括就是:近朱者赤近墨者黑。从实践上,我们发现k-近邻算法没有训练过程,它只是把训练样本保存起来,训练开销为零,收到测试样本后才进行处理,它是典型的懒惰学习(lazy learning);
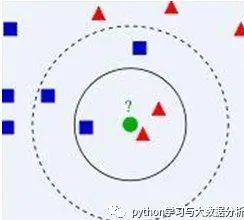
如上图有两类数据,分别是蓝色方块和红色三角形,假如我们有一个绿色圆形,需要判断这个圆形是跟蓝色同类还是跟红色同类。我们先把离这个绿色圆圈最近的K个点来帮助判断绿色圆圈离哪个分类的图形比较近,从而对蓝色圆圈进行分类。如果k=3,就表示我们选择离绿色圆圈最近的3个点来判断,由于红色三角形所占比例为2/3,所以我们认为绿色圆形和红色三角形同类。如果k=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。由此可见,k是一个重要参数,当k选不同值时会产生不同的结果。
k值设置过小会降低分类精度;若设置过大且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。
通常,k值的设定采用交叉检验的方式(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
K近邻算法通常采用的是欧式距离公式(当然也可以采用其他距离公式,如曼哈顿距离公式。只不过欧氏距离是最容易直观理解的距离度量方法,我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离。):
二、Python实现
import numpy as np #导入numpy模块import operator as op #导入operator模块def createDataSet():# 创建训练集及其对应标签集并返回group = numpy.array([[1.0, 1.1], [1.2, 1.4], [2.2, 2.9], [2.0, 3.1]])labels = ['A', 'A', 'B', 'B']return dataSet, labels#K-NN分类函数,采用欧式距离公式# ==============================================# 输入:# inX:目标向量# dataSet:训练集# labels:训练集对应的标签集# k:算法参数# 输出:# sortedClassCount[0][0]:目标向量的分类结果# ==============================================def classify(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]#将修改规模后的未知标签的数据记录与训练数据集作差diffMat = np.tile(inX, (dataSetSize,1)) - dataSet#将对应得到的差值求平方sqDiffMat = diffMat**2#横向求得上面差值平方的和,axis=1:表示矩阵的每一行分别进行相加sqDistances = sqDiffMat.sum(axis=1)#再对每条记录的平方和开方,得到每一条已知标签的记录与未知标签数据的距离distances = sqDistances**0.5#对求得的距离进行排序,返回的是排序之后的数值对应它原来所在位置的下标sortedDistIndicies = distances.argsort()#创建一个空的字典,用来保存和统计离未知标签数据最近的已知标签与该标签的个数,标签作为字典的key(键),该标签的个数作为字典的value(值)classCount={}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)#统计数最大的那个标签,作为对未知标签的预测,也就是该返回标签就是未知标签数据inX的预测标签了return sortedClassCount[0][0]def knn():# 新建训练集及其对应标签集group, labels = createDataSet()# 输入目标向量并返回分类结果后打印label = classify([1.1, 0.0], group, labels, 3)print labelif __name__ == '__main__':# 调用测试函数knn()
以上是关于机器学习——k近邻算法原理分析与python代码实现的主要内容,如果未能解决你的问题,请参考以下文章