分分钟实现C ++到JavaPython的代码转换!Facebook 最新发布的 TransCoder做到了
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分分钟实现C ++到JavaPython的代码转换!Facebook 最新发布的 TransCoder做到了相关的知识,希望对你有一定的参考价值。
在过往的 IT 技术变迁史中,不乏有将代码库迁移到主流或更高效语言,如 Java 或 C++ 的案例,这需要开发人员具备源语言和目标语言方面的专业知识,而且通常成本很高。例如,澳大利亚联邦银行在 5 年内花费了约 7.5 亿美元将其平台从 COBOL 转换为 Java。超编译器在理论上可以提供帮助,它们消除了从头开始重写代码的过程,但在实践中却很难应用,因为不同的语言可能有不同的语法,并依赖于不同的平台 API、标准库函数和变量类型。
为简化这一问题,Facebook 推出了 TransCoder ,该工具采用无监督学习,可以让代码在 C ++,Java 和 Python 之间进行转换。
根据研究人员的说法,TransCoder 在实验过程中展示了对每种语言特有的语法、数据结构及其方法的理解,并且在跨编程语言的情况下正确对齐了库,同时适应了较小的修改(例如当输入已重命名)。尽管它并不完美,例如 TransCoder 在生成过程中未能考虑某些变量类型,但它的性能仍然比一些框架要优秀。
该工具的一位共同作者写道:TransCoder 可以轻松推广到任何编程语言,不需要任何专业知识,并且在很大程度上优于商业解决方案。我们的研究结果表明,通过向解码器添加简单的约束以确保生成的函数在语法上是正确的,或者通过使用专用架构,可以轻松解决该模型所犯的许多错误。
对于 TransCoder,Facebook 考虑了一个带注意力的 seq2seq 模型,这个模型由一个编码器和一个带有 transformer 架构的解码器组成。所有的编程语言都共享同一个模型,使用 Lample et al. 中定义的无监督机器翻译的三个原理来训练它,即初始化、语言建模和回译。本节总结了这些原理,并详细介绍了如何在实例中编译编程语言(下图 1 给出了方法说明)。
预训练是无监督机器翻译 Lample 中的重要一环。它能确保具有相似意义的序列被映射到相同的 latent representation 上,而不用考虑它们是哪种编程语言。最初,预训练是通过用跨语言词汇表征初始化模型来完成的。在无监督英法翻译语境中,“cat”这个词的嵌入与其法语翻译 “chat”的嵌入接近。通过训练单语言词汇嵌入并让这些嵌入以无监督的方式训练,可以得到跨语言词汇嵌入。
随后的工作表明,以跨语言的方式预训练整个模型(而不仅仅是词汇表征)可以使无监督机器翻译得到显著改善。特别是,遵循 Lample 和 Conneau 的预训练原则进行训练时效果尤为明显——即在单语言源代码数据库上,用掩码语言建模 objective 预训练跨语言模型(XLM)。
所得模型的跨语言性质来自于不同语言间存在的海量通用标记(锚点)。在英法翻译的语境中,锚点基本上由数字、城市和人名组成。在编程语言中,这些锚点通常由常见的关键词组成(如 for、while、if、try),也包括数字、数学运算符和源代码中出现的英文字符串。
对于掩码语言建模(MLM)objective 来说,在每次迭代时,Facebook 都会考虑源码序列的输入流,随机屏蔽掉一些标记,并训练 TransCoder 来根据上下文预测被屏蔽掉的标记。在不同语言的批次流之间来回切换,这使得该模型能够创建高质量、跨语言的序列表征。图 1 展示了一个 XLM 预训练的例子。
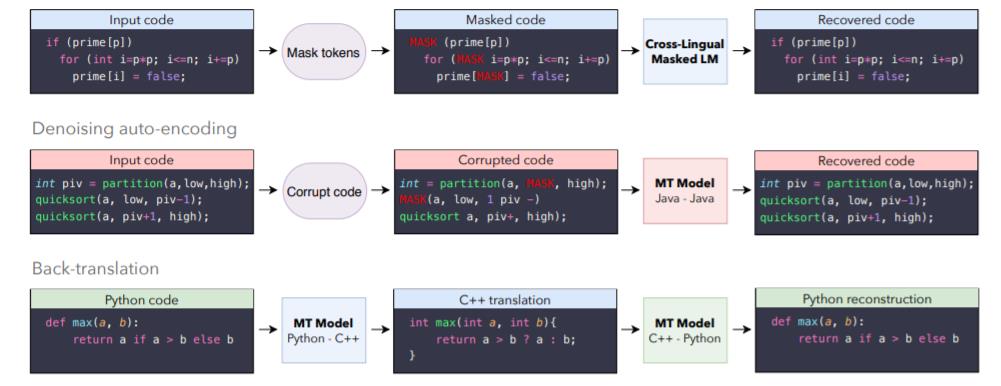
图 1
此方法中使用的无监督机器翻译三个原理的说明。第一个原理是用跨语言掩码语言模型预训练来初始化模型。因此,无论使用哪种编程语言,表达相同指令的代码块都会被映射到相同的表征上。第二个原理是去噪自动编码,训练解码器始终生成有效序列,即使输入的是噪声数据,也能提高编码器对输入噪声的鲁棒性。最后一个原理是回译,允许模型生成可以用于训练的并行数据。当 Python 语言模型转换成 C++ 语言模型性能更优时,它会为 C++ → Python 模型生成更准确的数据,反之亦然。
Facebook 用上述提到的预训练 XLM 模型来初始化 seq2seq 模型的编码器和解码器。编码器的初始化很简单,因为它的架构与 XLM 模型相同。然而,transformer 解码器有一些与源注意力机制相关的额外参数。根据 Lample 和 Conneau,随机初始化这些参数。
XLM 预训练能使 seq2seq 模型生成高质量的输入序列表征。然而,由于解码器从未被训练去解码一个基于源表征的序列,因此它缺乏翻译能力。为了解决这个问题,Facebook 以去噪自动编码(DAE)为目标来训练模型编码和解码序列。DAE objective 的操作就像一个监督的机器翻译算法,使用这种算法可以训练模型来预测一个给定损坏的标记序列。为了损坏一个序列,可以使用与 Lample et al. 中描述相同的噪声模型。也就是说,随机遮挡、删除和打乱这些输入标记。
输入到解码器中的第一个符号是一个特殊标记,表示输出的编程语言。在测试时,Python 序列可以被模型编码,并使用 C++ 起始符号进行解码,生成 C++ 翻译。C++ 翻译的质量将取决于模型的 "跨语言能力":如果 Python 函数和有效的 C++ 翻译被编码器映射到相同的 latent representation,解码器将成功生成 C++ 翻译。DAE objective 还训练了模型的 “语言建模 ”能力,也就是说,尽管有时编码器的输出是嘈杂的,但 Facebook 一直训练解码器去生成一个有效函数。此外,这种方法还训练了编码器对输入噪声的鲁棒性,这在回译的语境中非常有用,因为在回译过程中,模型是在有噪声的输入序列中训练的。图 1 对 DAE 进行了说明。
在实际操作中,仅 XLM 预训练和去噪自动编码就足以产生翻译。然而,这些翻译的质量往往很低,因为模型在测试时的效果未达到预期水准,即将函数从一种语言翻译到另一种语言。为了解决这个问题,Facebook 引入了回译,这是在弱监督场景下利用单语言数据的最有效方法之一。最初引入回译是为了提高监督环境下机器翻译的性能,后来发现回译变成了无监督机器翻译中的重要一环。在无监督环境下,source-to-target 模型与并行训练的后向 target-to-source 模型耦合。Target-to-source 模型用于将目标序列翻译成源语言,产生与实际目标序列相对应的噪声源序列。然而以弱监督的方式训练 source-to-target 模型,从 target-to-source 模型产生的噪声源序列重建目标序列,反之亦然。两个模型并行训练,直至实现趋同。图 1 中展示了一个回译的例子。
Facebook 使用具有 6 个 layer,8 个 attention head,并将模型的维度设置为 1024。对于所有编程语言,我们都使用单个编码器和解码器。XLM 预训练期间,在 C ++,Java 和 Python 之间进行了转换,它们由 512 个令牌的 32 个源代码序列组成。训练时,在去噪自编码器和回译 objectives 之间交替,并使用几批总数约 6000 个的标记。Facebook 使用 Adam 优化 TransCoder,学习速率为 10^(−4),并使用与 Vaswani 等相同的学习速率调度器。Facebook 在 PyTorch 中实现了模型,并在 32 个 V100 GPU 上对其进行训练,使用 float16 操作来加快训练速度并减少模型的内存使用量。
Facebook 通过 Google BigQuery4 获得 GitHub 公共数据集,其包含超过 280 万个开源 GitHub 存储库,过滤其中许可证明确允许重新分发的项目,并选择其中的 C ++,Java 和 Python 文件。理想情况下,转编译器应该能够翻译整个项目。在这项工作中,Facebook 决定在函数级别进行转换。与文件或类不同,函数足够短以适合单个批处理,并且在函数级别上可以通过单元测试对模型进行更简单的评估。Facebook 会在所有可用的源代码上对 TransCoder 进行预训练,并仅对函数进行去噪自动编码和回译 objectives,以获取有关提取功能的更多详细信息以及有关训练集的统计信息。Facebook 进行了一项消融研究,以确定保留还是删除源代码中的注释更好。在源代码中保留注释会增加跨语言的定位点数量,从而提高整体性能。因此,Facebook 将它们保留在最终数据集和实验中。
多语言自然语言处理的最新方法趋向于使用通用分词器和所有语言的共享词汇表,这减少了整体词汇量,并使语言之间的令牌重叠最大化,从而改善了模型的跨语言性。在本次实验中,通用令牌生成器不是最佳的,因为不同的语言使用不同的模式和关键字。逻辑运算符 && 和||在 C ++ 中存在,它们应该被单个标记,但在 Python 中不存在。缩进在 Python 中很重要,因为它们定义了代码结构,但在 C ++ 或 Java 之类的语言中没有任何意义。Facebook 在 Java 中使用 javalang tokenizer,Python 标准库的 tokenizer,C ++ 中使用 clang tokenizer。这些 tokenizer 可确保代码中无意义的修改(例如,添加额外的新行或空格)不会对 tokenized 序列产生任何影响。Facebook 在提取的令牌上学习 BPE 代码,并将其拆分为子单元。
GeeksforGeeks 是一个包含计算机科学和编程相关文章的在线平台,收集了许多编码问题,并提供了几种编程语言的解决方案。从这些解决方案中,Facebook 提取了一组 C ++、Java 和 Python 并行函数,以创建验证和测试集。这些函数不仅返回相同的输出,而且使用相似的算法计算结果。下图显示了一个 C ++、Java 和 Python 并行函数的示例,该函数确定由字符串表示的整数是否可以被 13 整除。

图 2:显示了无监督 Python 到 C++ 转换
大多数源代码转换研究都使用 BLEU 来评估生成的函数 [1、10、22、36] 或其他度量(基于翻译和参考中 token 之间的重叠度)。一个简单的度量是计算参考匹配,即与真实结果之间的匹配度,这些度量标准的局限性在于未考虑语法正确性,语法差异小则得分高,而它们可能导致完全不同的编译和计算输出。相反,具有不同实现方式的语义等效程序将具有较低的 BLEU 分数。取而代之的是,Facebook 引入了一种新的度量标准,即计算精度,该度量标准可以评估转换后函数在给定相同输入时是否生成与参考函数相同的输出。如果每个输入给出的输出与参考相同,则认为转换是正确的。

验证集和测试集中带有单元测试的函数数量
在表 1 中报告了测试集上的结果。在表 2 中,报告了使用集束搜索解码的结果,并将 TransCoder 与现有的 baseline 进行了比较。图 2 给出了一个从 Python 到 C++ 的无监督翻译的例子。
评估度量标准之间的差异。在表 1 中,Facebook 发现大部分翻译与参考不同,虽然它们成功通过了单元测试,但是通过与参考匹配度量标准进行对比,这些翻译被认为是无效的。例如,当从 C++ 翻译到 Java 时,虽然 60.9% 的翻译达到了预期水准,但仅有 3.1% 的生成结果与实际参考完全相同。此外,其性能在 BLEU 上也表现平平,与计算精度相关性不高。测试结果显示了这种方法在该领域中常用的传统参考匹配指标和 BLEU 指标上存在一些问题。
集束搜索解码。在表 2 中,Facebook 研究了集束搜索的影响,要么考虑集束中所有通过单元测试的假设(Beam N),要么只考虑对数概率最高的假设(Beam N - Top 1)。与 greedy 解码(Beam 1)相比,集束搜索显著提高了计算精度,使 Beam 25 Java → Python 的计算精度提高了 33.7%。当模型只返回对数概率最高的假设时,性能就会下降,这说明 TransCoder 经常能找到有效的翻译,尽管它有时会给错误的假设一个较高的对数概率。文中给出了通过集束搜索纠正错误的解释。

表 1:TransCoder 在测试集上 greedy 解码的结果。
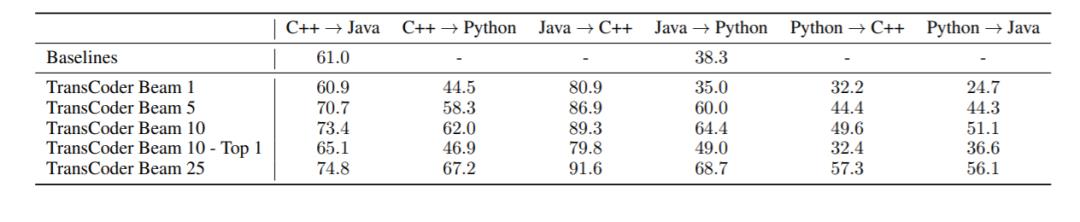
表 2:集束搜索解码计算准确率和以及和 Baseline 的对比
在实际用例中,检查生成的函数是否在语法上正确并被编译过,或者从输入函数中创建单元测试,这些方法都比对比对数概率更好。附录中的表 5 显示,当目标语言是 Java 或 C++ 时,编译错误是测试失败的最主要原因之一。这表明 “Beam N - Top 1”指标可以很容易地进行改进。
与现有 baseline 相比。Facebook 将 TransCoder 与现有的两种方法进行比较:第一种是 j2py10 ,一个从 Java 翻译到 Python 的框架;第二种是 Tangible Software Solutions11 的商业解决方案,从 C++ 翻译到 Java。这两个系统都依赖于用专业知识手动建立的重写规则。后者处理多种元素的转换,包括核心类型、数组、一些集合(Vectors 和 Maps)和 lambdas。
在表 2 中,Facebook 观察到 TransCoder 在计算精度上明显优于两个 baseline,从 C++ 到 Java 的计算准确率能达到 74.8%,从 Java 到 Python 的计算准确率能达到 68.7%,而 baseline 在这两种转换上的计算准确率分别为 61% 和 38.3%。在翻译标准库中的函数时,TransCoder 的表现尤为突出。在基于规则的编译转换器中,需要为每个标准库函数手动编码重写规则,而 TransCoder 则以无监督的方式学习这些规则。下图介绍了 TransCoder 的几个成功例子,而 baseline 则无法生成正确的翻译。

图 3:错误的 baseline 翻译与正确的 TransCoder 翻译示例
事实上,Facebook 并不是唯一开发代码生成系统的组织。在今年早些时候的 Microsoft Build 大会上,OpenAI 演示了一个在 GitHub 存储库上训练的模型,该模型使用英语注释生成整个功能。两年前,莱斯大学的研究人员创建了一个名为 Bayou 的系统,该系统通过将公开代码背后的“意图”相关联,实现自主编写软件程序。
拥有吃喝玩乐全场景丰富数据的美团点评,利用跨场景数据挖掘、映射、聚合与关联构建了一个庞大的生活服务知识图谱——“美团大脑”,这个知识图谱可以促进每个场景下应用服务的智能升级。点击「阅读原文」来 AICon 上海 2020 了解新零售场景下的知识图谱如何构建与落地。大会限时 8 折购票中,欢迎咨询票务小姐姐:18514549229(微信同号)。
今日荐文
台积电最新回应:如无法向华为出售芯片,将尽快填补订单缺口
你也「在看」吗? 以上是关于分分钟实现C ++到JavaPython的代码转换!Facebook 最新发布的 TransCoder做到了的主要内容,如果未能解决你的问题,请参考以下文章