求哈夫曼解码C语言程序 请各位大侠在我原有的程序上加上哈夫曼解码的程序,不胜感激!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了求哈夫曼解码C语言程序 请各位大侠在我原有的程序上加上哈夫曼解码的程序,不胜感激!相关的知识,希望对你有一定的参考价值。
请各位大侠在我原有的程序上加上哈夫曼解码的程序,不胜感激!
如输入101010010000010,输出ABC即可!谢谢!
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <conio.h>
typedef struct
unsigned int weight;
unsigned int parent,lchild,rchild;
HTNode,*HuffmanTree;
typedef char **HuffmanCode;
typedef struct
unsigned int s1;
unsigned int s2;
MinCode;
MinCode Select(HuffmanTree HT,int n);
HuffmanCode HuffmanCoding(HuffmanTree HT,HuffmanCode HC,int *w,int n)
int i,s1=0,s2=0;
HuffmanTree p;
char *cd;
int f,c,start,m;
MinCode min;
m=2*n-1;
HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));
for(p=HT,i=0;i<=n;i++,p++,w++)
p->weight=*w;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(;i<=m;i++,p++)
p->weight=0;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(i=n+1;i<=m;i++)
min=Select(HT,i-1);
s1=min.s1;
s2=min.s2;
HT[s1].parent=i;
HT[s2].parent=i;
HT[i].lchild=s1;
HT[i].rchild=s2;
HT[i].weight=HT[s1].weight+HT[s2].weight;
HC=(HuffmanCode)malloc((n+1)*sizeof(char *));
cd=(char *)malloc(n*sizeof(char *));
cd[n-1]='\0';
for(i=0;i<=n;i++)
start=n-1;
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)
if(HT[f].lchild==c) cd[--start]='0';
else cd[--start]='1';
HC[i]=(char *)malloc((n-start)*sizeof(char *));
strcpy(HC[i],&cd[start]);
free(cd);
return HC;
MinCode Select(HuffmanTree HT,int n)
int min,secmin;
int temp;
int i,s1,s2,tempi;
MinCode code;
s1=1;s2=1;
for(i=0;i<=n;i++)
if(HT[i].parent==0)
min=HT[i].weight;
s1=i;
break;
tempi=i++;
for(;i<=n;i++)
if(HT[i].weight<min&&HT[i].parent==0)
min=HT[i].weight;
s1=i;
for(i=tempi;i<=n;i++)
if(HT[i].parent==0&&i!=s1)
secmin=HT[i].weight;
s2=i;
break;
for(i=0;i<=n;i++)
if(HT[i].weight<secmin&&i!=s1&&HT[i].parent==0)
secmin=HT[i].weight;
s2=i;
if(s1>s2)
temp=s1;
s1=s2;
s2=temp;
code.s1=s1;
code.s2=s2;
return code;
void main()
HuffmanTree HT=NULL;
HuffmanCode HC=NULL;
int i,n=27;
char c[27]=' ','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z';
int w[27]=186,64,13,22,32,103,21,15,47,57,1,5,32,20,57,63,15,1,48,51,80,23,8,18,1,16,1;
HC=HuffmanCoding(HT,HC,w,n);
printf("HuffmanCode:\n");
printf("Char\t\tWeight\t\tCode\n");
for(i=0;i<=n-1;i++)
printf("%c\t\t%d\t\t%s\n",c[i],w[i],HC[i]);
getch();
#include <string.h>
#include <stdlib.h>
#include <conio.h>
typedef struct
unsigned int weight;
unsigned int parent,lchild,rchild;
HTNode,*HuffmanTree;/*动态分配数组存储哈夫曼树*/
typedef char **HuffmanCode;/*动态分配数组存储哈夫曼编码表*/
typedef struct
unsigned int s1;
unsigned int s2;
MinCode;
MinCode Select(HuffmanTree HT,int n);
HuffmanCode HuffmanCoding(HuffmanTree HT,HuffmanCode HC,int *w,int n)
/* w存放n个字符的权值(均>0),构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC.*/
int i,s1=0,s2=0;
HuffmanTree p;
char *cd;
int f,c,start,m;
MinCode min;
m=2*n-1;
HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode)); /*0号单元未用*/
for(p=HT,i=0;i<=n;i++,p++,w++)
p->weight=*w;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(;i<=m;i++,p++)
p->weight=0;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(i=n+1;i<=m;i++) /*建哈夫曼树*/
/*在HT[1..i-1]选择parent为0且weight最小的两个结点,其序号分别为s1和s2.*/
min=Select(HT,i-1);
s1=min.s1;
s2=min.s2;
HT[s1].parent=i;
HT[s2].parent=i;
HT[i].lchild=s1;
HT[i].rchild=s2;
HT[i].weight=HT[s1].weight+HT[s2].weight;
/*从叶子到根逆向求每个字符的哈夫曼编码*/
HC=(HuffmanCode)malloc((n+1)*sizeof(char *)); /*分配n个字符编码的头指针向量*/
cd=(char *)malloc(n*sizeof(char *)); /*分配求编码的工作空间*/
cd[n-1]='\0'; /*编码结束符*/
for(i=0;i<=n;i++)
/*逐个字符求哈夫曼编码*/
start=n-1; /*编码结束符位置*/
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent) /*从叶子到根逆向求编码*/
if(HT[f].lchild==c) cd[--start]='0';
else cd[--start]='1';
HC[i]=(char *)malloc((n-start)*sizeof(char *)); /*为第i个字符编码分配空间*/
strcpy(HC[i],&cd[start]); /*从cd复制编码(串)到HC*/
free(cd); /*释放工作空间*/
return HC;
MinCode Select(HuffmanTree HT,int n)
int min,secmin;
int temp;
int i,s1,s2,tempi;
MinCode code;
s1=1;s2=1;
for(i=0;i<=n;i++)
if(HT[i].parent==0)
min=HT[i].weight;
s1=i;
break;
tempi=i++;
for(;i<=n;i++)
if(HT[i].weight<min&&HT[i].parent==0)
min=HT[i].weight;
s1=i;
for(i=tempi;i<=n;i++)
if(HT[i].parent==0&&i!=s1)
secmin=HT[i].weight;
s2=i;
break;
for(i=0;i<=n;i++)
if(HT[i].weight<secmin&&i!=s1&&HT[i].parent==0)
secmin=HT[i].weight;
s2=i;
if(s1>s2)
temp=s1;
s1=s2;
s2=temp;
code.s1=s1;
code.s2=s2;
return code;
void main()
HuffmanTree HT=NULL;
HuffmanCode HC=NULL;
int i,n=27;
char c[27]=' ','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z';
int w[27]=186,64,13,22,32,103,21,15,47,57,1,5,32,20,57,63,15,1,48,51,80,23,8,18,1,16,1;
HC=HuffmanCoding(HT,HC,w,n);
printf("HuffmanCode:\n");
printf("Char\t\tWeight\t\tCode\n");
for(i=0;i<=n-1;i++)
printf("%c\t\t%d\t\t%s\n",c[i],w[i],HC[i]);
char cs[128];
char results[64];
char buf[64];
int ps=0,pe=1;
results[0]=0;
printf("Input code:\n");
scanf("%s",cs);
while (cs[ps]!=0)
strncpy(buf,&cs[ps],pe-ps); /*返回字符*/
buf[pe-ps]=0;
for(i=0;i<n;i++)
if (strcmp(buf,HC[i])==0)
int len=strlen(results);
results[len]=c[i];
results[len+1]=0;
ps=pe;
pe++;
break;
if (cs[pe]==0) break;
pe++;
printf("RESULT: %s",results);
getch();
参考技术A //这是我写的haffman编码:
//不明白,发消息问我哦。
#include "iostream.h"
class Haffman
public:
int Weight;
int Father;
int Left;
int Right;
;
Haffman* HAFFMAN(const int n,int opt[])
Haffman *h=new Haffman[2*n-1];
int i,j;
int w1,w2;
int n1,n2;
for(i=0;i<2*n-1;i++)
h[i].Father =-1;
h[i].Weight=0;
h[i].Left=-1;
h[i].Right=-1;
for(i=0;i<n;i++)
h[i].Weight=opt[i];
for(i=0;i<n-1;i++)
w1=9999;
w2=9999;
n1=0;
n2=0;
for(j=0;j<n+i;j++)
if (h[j].Weight<w1 && h[j].Father==-1)
w2=w1;
w1=h[j].Weight;
n2=n1;
n1=j;
else if(h[j].Weight<w2 && h[j].Father==-1)
w2=h[j].Weight;
n2=j;
h[n2].Father=n+i;
h[n1].Father=n+i;
h[n+i].Left = n2;
h[n+i].Right= n1;
h[n+i].Weight=h[n1].Weight+h[n2].Weight;
return h;
class Letter
public:
bool data[8];
int bit;
Letter()bit=0;
;
void d(char *opt,Haffman *scr)
int now=46;
while(*opt)
if (*opt=='1')
now=scr[now].Right;
if (scr[now].Right==-1)
cout<<char(now+'A');
now=46;
else
now=scr[now].Left;
if (scr[now].Left==-1)
cout<<char(now+'A');
now=46;
opt++;
cout<<endl;
int main()
int w[27]=186,64,13,22,32,103,21,15,47,57,13,5,392,20,57,63,15,123,48,51,80,23,8,18,321,16,132;
Haffman *opt=HAFFMAN(24,w);
Letter l[24];
int tmp;
for(int i=1;i<=24;i++)
tmp=i-1;
while(opt[tmp].Father!=-1)
if (opt[opt[tmp].Father].Left == tmp)
l[i-1].data[l[i-1].bit++]=0;
else
l[i-1].data[l[i-1].bit++]=1;
tmp=opt[tmp].Father;
for(i=1;i<=24;i++)
for(int j=0;j<=l[i-1].bit/2;j++)
char tmp=l[i-1].data[j];
l[i-1].data[j]=l[i-1].data[l[i-1].bit-j-1];
l[i-1].data[l[i-1].bit-j-1]=tmp;
for(i=1;i<=24;i++)
cout<<char(i+'A'-1)<<"\t";
for(int j=1;j<=l[i-1].bit;j++)
cout<<l[i-1].data[j-1];
cout<<endl;
char t[100];
cin>>t;
d(t,opt);
return 0;
参考技术B 加上有些男,这里有完整的,你可以看看!
希望有所帮助!
该睡觉了!
#include<iostream>
#include<string>
using namespace std;
typedef struct
int weight;
int flag;
int parent;
int lchild;
int rchild;
hnodetype;
typedef struct
int bit[10];
int start;
char leaf;
hcodetype;
void huf(char cha[],int m[],int n)
int i,j,m1,m2,x1,x2,c,p;
hnodetype *huffnode=new hnodetype[2*n-1];
hcodetype *huffcode=new hcodetype[n],cd;
for(i=0;i<2*n-1;i++)
huffnode[i].weight=0;
huffnode[i].parent=0;
huffnode[i].flag=0;
huffnode[i].lchild=-1;
huffnode[i].rchild=-1;
for(i=0;i<n;i++)
huffnode[i].weight=m[i];
huffcode[i].leaf=cha[i];
for(i=0;i<n-1;i++)
m1=m2=10000000;
x1=x2=0;
for(j=0;j<n+i;j++)
if(huffnode[j].weight<=m1&&huffnode[j].flag==0)
m2=m1;
x2=x1;
m1=huffnode[j].weight;
x1=j;
else if(huffnode[j].weight<=m2&&huffnode[j].flag==0)
m2=huffnode[j].weight;
x2=j;
huffnode[x1].parent=n+i;
huffnode[x2].parent=n+i;
huffnode[x1].flag=1;
huffnode[x2].flag=1;
huffnode[n+i].weight=huffnode[x1].weight+huffnode[x2].weight;
huffnode[n+i].lchild=x1;
huffnode[n+i].rchild=x2;
for(i=0;i<n;i++)
cd.start=n-1;
c=i;
p=huffnode[c].parent;
while(p!=0)
if(huffnode[p].lchild==c)
cd.bit[cd.start]=0;
else
cd.bit[cd.start]=1;
cd.start--;
c=p;
p=huffnode[c].parent;
cout<<huffcode[i].leaf<<":";
for(j=cd.start+1;j<n;j++)
huffcode[i].bit[j]=cd.bit[j];
cout<<cd.bit[j];
cout<<endl;
huffcode[i].start=cd.start;
delete[] huffcode;
delete[] huffnode;
void main()
string str;
int i=0,j,n,m[100],h,k=0;
char cha[100];
cout<<"请输入一个字符串"<<endl;
cin>>str;
n=str.length();
cout<<"字符串总共有字符"<<n<<"个"<<endl;
for(i=0;i<n;i++)
j=0;h=0;
while(str[i]!=str[j])
j++;
if(j==i)
cha[k]=str[i];
cout<<"字符"<<cha[k]<<"出现";
else
continue;
for(j=i;j<n;j++)
if(str[i]==str[j])
h++;
cout<<h<<"次"<<endl;
m[k]=h;
k++;
cout<<"每个字符的哈夫曼编码是:"<<endl;
huf(cha,m,k);
cin.get();
cin.get();
参考技术C 帮你改了,能运行
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <conio.h>
typedef struct
unsigned int weight;
unsigned int parent,lchild,rchild;
HTNode,*HuffmanTree;
typedef char **HuffmanCode;
typedef struct
unsigned int s1;
unsigned int s2;
MinCode;
MinCode Select(HuffmanTree HT,int n);
HuffmanCode HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int *w,int n)
int i,s1=0,s2=0;
HuffmanTree p;
char *cd;
int f,c,start,m;
MinCode min;
m=2*n-1;
HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));
for(p=HT,i=0;i<=n;i++,p++,w++)
p->weight=*w;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(;i<=m;i++,p++)
p->weight=0;
p->parent=0;
p->lchild=0;
p->rchild=0;
for(i=n+1;i<=m;i++)
min=Select(HT,i-1);
s1=min.s1;
s2=min.s2;
HT[s1].parent=i;
HT[s2].parent=i;
HT[i].lchild=s1;
HT[i].rchild=s2;
HT[i].weight=HT[s1].weight+HT[s2].weight;
HC=(HuffmanCode)malloc((n+1)*sizeof(char *));
cd=(char *)malloc(n*sizeof(char *));
cd[n-1]='\0';
for(i=0;i<=n;i++)
start=n-1;
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)
if(HT[f].lchild==c) cd[--start]='0';
else cd[--start]='1';
HC[i]=(char *)malloc((n-start)*sizeof(char *));
strcpy(HC[i],&cd[start]);
free(cd);
return HC;
MinCode Select(HuffmanTree HT,int n)
int min,secmin;
int temp;
int i,s1,s2,tempi;
MinCode code;
s1=1;s2=1;
for(i=0;i<=n;i++)
if(HT[i].parent==0)
min=HT[i].weight;
s1=i;
break;
tempi=i++;
for(;i<=n;i++)
if(HT[i].weight<min&&HT[i].parent==0)
min=HT[i].weight;
s1=i;
for(i=tempi;i<=n;i++)
if(HT[i].parent==0&&i!=s1)
secmin=HT[i].weight;
s2=i;
break;
for(i=0;i<=n;i++)
if(HT[i].weight<secmin&&i!=s1&&HT[i].parent==0)
secmin=HT[i].weight;
s2=i;
if(s1>s2)
temp=s1;
s1=s2;
s2=temp;
code.s1=s1;
code.s2=s2;
return code;
void Transcode(HuffmanTree HT,HuffmanCode HC,int n,char *c)
HuffmanTree p;
char str[500];
int L,i,j=0;
scanf("%s",str);
L=strlen(str);
while(j<L)
p=&HT[2*n-1];
while(p->lchild||p->rchild)
if(str[j]=='0')
i=p->lchild; p=&HT[i];
else
i=p->rchild; p=&HT[i];
j++;
printf("%c",c[i]);
printf("\n");
void main()
HuffmanTree HT=NULL;
HuffmanCode HC=NULL;
int i,n=27;
char c[27]=' ','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z';
int w[27]=186,64,13,22,32,103,21,15,47,57,1,5,32,20,57,63,15,1,48,51,80,23,8,18,1,16,1;
HC=HuffmanCoding(HT,HC,w,n);
printf("HuffmanCode:\n");
printf("Char\t\tWeight\t\tCode\n");
for(i=0;i<=n-1;i++)
printf("%c\t\t%d\t\t%s\n",c[i],w[i],HC[i]);
printf("input\n");
Transcode(HT,HC,n,c);
getch();
参考技术D 我再煮程序里加了一段
void main()
HuffmanTree HT=NULL;
HuffmanCode HC=NULL;
int i,n=27;
char c[27]=' ','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z';
int w[27]=186,64,13,22,32,103,21,15,47,57,1,5,32,20,57,63,15,1,48,51,80,23,8,18,1,16,1;
HC=HuffmanCoding(HT,HC,w,n);
printf("HuffmanCode:\n");
printf("Char\t\tWeight\t\tCode\n");
for(i=0;i<=n-1;i++)
printf("%c\t\t%d\t\t%s\n",c[i],w[i],HC[i]);
//ADD here
char cs[128];//="101010010000010"
char results[64];
char buf[64];
int ps=0,pe=1;
results[0]=0;
printf("Input code:\n");
scanf("%s",cs);
while (cs[ps]!=0)
//copy str
strncpy(buf,&cs[ps],pe-ps);
buf[pe-ps]=0;
for(i=0;i<n;i++)
if (strcmp(buf,HC[i])==0)
//equal
int len=strlen(results);
results[len]=c[i];
results[len+1]=0;
ps=pe;
pe++;
break;
if (cs[pe]==0) break;
pe++;
printf("RESULT: %s",results);
getch();
20172303 2018-2019-1《程序设计与数据结构》哈夫曼树编码与解码
20172303 2018-2019-1《程序设计与数据结构》哈夫曼树编码与解码
哈夫曼树简介
- 定义:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
- 带权路径长度(Weighted Path Length of Tree,简记为WPL)
- 结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
- 结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
- 树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和。
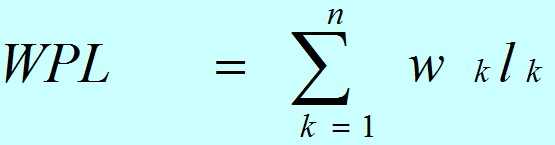
哈夫曼树代码实现
- 代码参考了java创建哈夫曼树和实现哈夫曼编码
HuffmanNode类
- 首先设置一个
HuffmanNode类作为实现的基础,每个结点都包含一个六项内容:权值、结点代表字母、字母的编码、左孩子、右孩子和父结点,为了方便之后进行结点的比较,这里还重新编写了一下compareTo方法。
public int compareTo(HuffmanNode<T> o) {
if (this.getWeight() > o.getWeight()){
return -1;
}
else if (this.getWeight() < o.getWeight()){
return 1;
}
return 0;
}HuffmanTree类
- 在
HuffmanTree类里有两个方法,第一个方法createTree方法用于构造树,第二个方法BFS方法是使用广度优先遍历来给每一个叶子结点进行编码。具体方法及步骤在代码中都已写明。
public static HuffmanNode createTree(List<HuffmanNode<String>> nodes) {
while (nodes.size() > 1){
// 对数组进行排序
Collections.sort(nodes);
// 当列表中还有两个以上结点时,构造树
// 获取权值最小的两个结点
HuffmanNode left = nodes.get(nodes.size() - 2);
left.setCode(0 + "");
HuffmanNode right = nodes.get(nodes.size() - 1);
right.setCode(1 + "");
// 生成新的结点,新结点的权值为两个子节点的权值之和
HuffmanNode parent = new HuffmanNode(left.getWeight() + right.getWeight(), null);
// 使新结点成为父结点
parent.setLeft(left);
parent.setRight(right);
// 删除权值最小的两个结点
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);
}
public static List<HuffmanNode> BFS(HuffmanNode root){
Queue<HuffmanNode> queue = new ArrayDeque<HuffmanNode>();
List<HuffmanNode> list = new java.util.ArrayList<HuffmanNode>();
if (root != null){
// 将根元素加入队列
queue.offer(root);
root.getLeft().setCode(root.getCode() + "0");
root.getRight().setCode(root.getCode() + "1");
}
while (!queue.isEmpty()){
// 将队列的队尾元素加入列表中
list.add(queue.peek());
HuffmanNode node = queue.poll();
// 如果左子树不为空,将它加入队列并编码
if (node.getLeft() != null){
queue.offer(node.getLeft());
node.getLeft().setCode(node.getCode() + "0");
}
// 如果右子树不为空,将它加入队列并编码
if (node.getRight() != null){
queue.offer(node.getRight());
node.getRight().setCode(node.getCode() + "1");
}
}
return list;
}HuffmanMakeCode类
HuffmanMakeCode类用于将文件中的内容提取,放入数组并进行计数,这里将数组长度设置为27,因为还对空格进行了计数,以便于解码。具体方法及步骤在代码中都已写明。
public class HuffmanMakeCode {
public static char[] word = new char[]{'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s'
,'t','u','v','w','x','y','z',' '};
public static int[] number = new int[]{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
public static String makecode(FileInputStream stream) throws IOException {
//读取文件(缓存字节流)
BufferedInputStream in = new BufferedInputStream(stream);
//一次性取多少字节
byte[] bytes = new byte[2048];
//接受读取的内容(n就代表的相关数据,只不过是数字的形式)
int n = -1;
String a = null;
//循环取出数据
while ((n = in.read(bytes, 0, bytes.length)) != -1) {
//转换成字符串
a = new String(bytes, 0, n, "GBK");
}
// 对文件内容进行计数
count(a);
return a;
}
// 实现对文件内容计数,内层循环依次比较字符串中的每个字符与对应字符是否相同,相同时计数;外层循环指定对应字符从a至空格
public static void count(String str){
for (int i = 0;i < 27;i++){
int num = 0;
for (int j = 0;j < str.length();j++){
if (str.charAt(j) == word[i]){
num++;
}
}
number[i] += num;
}
}
public static char[] getWord() {
return word;
}
public static int[] getNumber() {
return number;
}
}HuffmanTest类
HuffmanTest类进行了文件的读取,构造哈夫曼树,编码,解码,文件的写入五个步骤,其中前三个步骤使用之前三个类中的方法即可实现,这里主要说一下后两个步骤。- 解码:解码部分使用一个列表list4将编码结果的字符串转化到列表中去,然后定义了两个变量,第一个变量用于每次依次获取的编码值,然后与list3(存储编码的列表)进行比较找到对应索引,然后将list2(存储字母的列表)中对应索引值位置的字母加入第二个变量中,每次循环后删除列表list4的第一个元素,循环直至list4为空时结束,第二个变量temp1中存储的即为解码结果。
- 文件写入:文件写入就是很简单的方法使用,这里使用的是字符操作流(使用FileWriter类和FileReader类)的方法。
// 进行解码
List<String> list4 = new ArrayList<>();
for (int i = 0;i < result.length();i++){
list4.add(result.charAt(i) + "");
}
String temp = "";
String temp1 = "";
while (list4.size() > 0){
temp += "" + list4.get(0);
list4.remove(0);
for (int i = 0;i < list3.size();i++){
if (temp.equals(list3.get(i))){
temp1 += "" + list2.get(i);
temp = "";
}
}
}
System.out.println("文件解码结果为: " + temp1);
// 写入文件
File file = new File("C:\\Users\\45366\\IdeaProjects\\fwq20172303_Programming\\HuffmanTest2.txt");
Writer out = new FileWriter(file);
out.write(result);
out.close();参考资料
以上是关于求哈夫曼解码C语言程序 请各位大侠在我原有的程序上加上哈夫曼解码的程序,不胜感激!的主要内容,如果未能解决你的问题,请参考以下文章