贪吃蛇程序中乘方部分是啥意思?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贪吃蛇程序中乘方部分是啥意思?相关的知识,希望对你有一定的参考价值。
P2=mux(x[i]);
P1=255-mux(y[i]);
**************************************
/*****************
乘方程序
*****************/
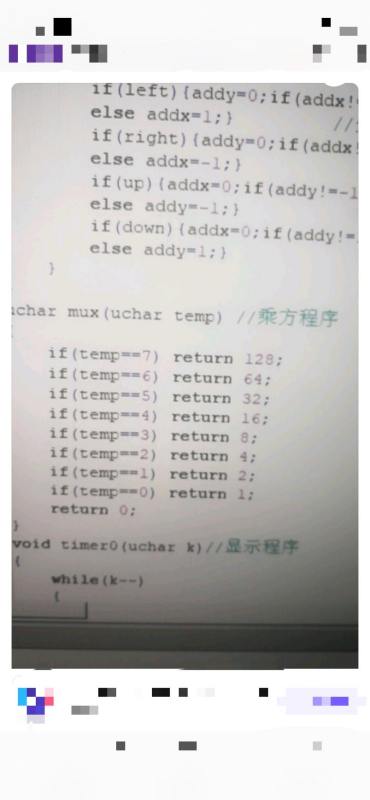
uchar mux(uchar temp)
if(temp==7)return 128;
if(temp==6)return 64;
if(temp==5)return 32;
if(temp==4)return 16;
if(temp==3)return 8;
if(temp==2)return 4;
if(temp==1)return 2;
if(temp==0)return 1;
return 0;
/*****************
显示时钟 显示程序
*****************/
void timer0(uchar k)
while(k--)
for(i=0;i<SNAKE+1;i++)
P2=mux(x[i]);
P1=255-mux(y[i]);
turnkey(); //上下左右键位处理
delay(TIME); //显示延迟
P2=0x00;
P1=0xff;

乘方部分返回2的temp次方
提问不清楚
能不能再解释详细一点
回答好

乘方程序啊
回答
往简单了说,就是等待⌛️
等待他们的运行。
提问啊?
回答就是源代码
提问还是没懂
回答让我再想想怎么说,你才能明白?
是这样的吧
提问对,然后就是看不懂什么意思,能讲清楚些吗
回答这个是编程。
这些才能运行。
这个是比较深奥的,只有IT行业的才懂。
那些专业术语说了,也不是很明白。
后来推出了cp系统,就是充钱,没别的。
一会一个cpdd一会一个cpdd
还有各种充值端口,各种关不掉的广告(虚假关闭键,点一下就进广告里了,真的得等几秒才会出现)
这个代码在定义关键的左边的时候,需要的是整型(int),但是捕获的却是其他,目前我还没找到好的办法完全解决。但是解决了中心点的问题(rotatedRect1.center),起码exe文件能运行了。
如果有问题的话。把我最开始回答的那一行写上去就行了。
让AI学会玩贪吃蛇
参考技术A2019/02/07
我记得我年前的时候,我看过很多文章,包括一些论文,主题都是利用AI来玩贪吃蛇这种。他们利用的方法很多,例如利用搜索算法[1],还有利用监督学习来进行训练达到目的的,训练数据的来源是有自己玩游戏产生的(好像有算法是可以让他自己产生的,想不起来是在哪里看到的了。),当然这种正如他自己所说,后续的结果就是机器最多玩的和你一样好,最后一种见的比较多的就是利用强化学习,加上Q-Learning算法的方式。 针对搜索算法部分,可以看前面的一篇随笔《贪吃蛇游戏》。
那段时间看了不少这类的文章,我现在集中阅读一下,并简单理解一下这部分内容的关键部分。无论什么游戏,都有一个 相应的状态空间 的定义,这部分数据,本质上就是这个游戏能展现给我的所有的内容。那么怎么来利用这部分数据,就是你的能力了。
文章[2]中,他是用的方法同时结合了深度学习和强化学习。 (我也想深究一下,如果是仅仅使用强化学习,这个过程又是什么样的,得看我收集的文章中,是不是有这类部分的内容了;我记得好像强化学习就是利用Q-Learning这种算法来实现的) 但是这篇文章感觉说的不够清楚,最重要的那个点就是,强化学习到底是如何跟深度学习联合起来的。可能单单强化学习已经可以完成这个任务了。
我大概理解了这个过程,他是利用强化学习来作为自动化生成数据的过程了,一开始的时候,利用强化学习尽可能得到多的数据,然后采样或者怎么样使得最后的数据作为训练得到效果。 这篇文章讲述的并不是清楚,不推荐。 下面这个图从这篇文章中看到的,挺不错。
文章[3]基于强化学习Q-Learning完成了贪吃蛇的步骤,不过貌似他的这个效果并不是非常好。整个部分的源码他都是利用js来完成的, 讲解部分比较基础, 回答了前一小节的疑问。
本篇文章中,他介绍的另外一个内容挺不错,就是利用神经网络来玩谷歌浏览器的游戏。
文章[5]利用深度学习和遗传算法来训练玩游戏;这部分的文章一系列的内容,从使用pygame设计游戏,到后面自动化产生数据,最后使用GA+ANN直接不需要数据。他的思路 跟前面强化学习是不一样的。
前面部分讲到了自动化产生训练数据的部分,这个部分我感觉讲解的并不是非常好,他的自动化并不是说让游戏自己去探测这个各种内容。反而是根据某种公式来计算角度,最终实现这个过程。后续GA算法的时候又说道可以不是用训练数据。
他利用GA算法应该是使用了两个部分,第一个就是直接使用GA进行训练,他的适应函数(fittness function)部分,类似强化学习的部分,产生奖励和惩罚机制。第二个就是使用GA算法来选择神经网络的架构。 (这部分我也不是很确认,有点没看懂他要干什么) 对于神经网络中的权值部分他是如何进行实现的,这是我的一个疑问。 GA算法到底针对的是哪一部分的内容。这种文章还是有一定缺陷的。GA算法是两部分内容,首先就是权值更新内容。
虽然这篇文章感觉很基础,但我觉的写的不好。
利用学习的办法实现玩游戏的目标,比较重要的问题,有以下几个。
[1] Hawstein,如何用Python写一个贪吃蛇AI
[2] 如何让AI玩贪吃蛇:深度强化学习
[3] 利用强化学习玩贪吃蛇
[4] 谷歌小恐龙
[5] 深度学习与贪吃蛇
以上是关于贪吃蛇程序中乘方部分是啥意思?的主要内容,如果未能解决你的问题,请参考以下文章