分词|Python最好的中文分词库
Posted 数据山谷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分词|Python最好的中文分词库相关的知识,希望对你有一定的参考价值。


大家都知道,在处理文本的时候,对于英文的文本我们可以通过空格将每一个单词分开,但是“中国文化,博大精深”汉语的句子中每一个词都仅仅的连在一起,如果不靠人们去辨别就很难将他们分开,为了解决这个问题号称最好的中文分词库“jieba”出现了。
PS:至今二师兄也没发现比jieba更好的中文分词库。
PART
1
jieba所使用的算法
在使用这个库之前,我相信有很多的读者一定很想知道jieba背后的工作原理,jieba具体应用的算法如下:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
PART
2
jieba中文分词
jieba库最出名的功能就是中文分词,在jieba中提供了三种常用的分词模式:
精确模式:将句子按照最精确的方法进行切分,适合用于进行文本分析;
全模式:将句子当中所有可以成词的词语都扫描出来,分词速度很快但容易产生歧义;
搜索引擎模式:在精确模式分词的基础上,将长的句子再次进行切分,提高召回率,适用于搜索引擎的分词。
注:jieba也支持对繁体字进行分词。在jieba中我们可以使用jieba.cut和jieba.cut_for_search来进行中文分词,我们可使用 for 循环来获得分词后得到的每一个词语。
看代码之前,不妨先考虑一下,“南京市长江大桥”能分成几个词语呢?
代码示例如下:
import jiebaex = '南京市长江大桥'# 全分词模式all_cut = jieba.cut(ex, cut_all=True)# 精确分词模式precise_cut = jieba.cut(ex, cut_all=False)# 当我们省略掉cut_all参数时,cut_all默认值为False,此时分词模式为精确分词default_precise_cut = jieba.cut(ex)# 搜索引擎模式search_cut = jieba.cut_for_search(ex)print("全分词: ", "/".join(all_cut))print("精确分词: ", "/".join(precise_cut))print("默认精确分词: ", "/".join(default_precise_cut))print("搜索分词: ", "/".join(search_cut))
结果如下:

PART
3
jieba中字典的补充
有的读者可能在分词后没有得到想要的结果,这或许是因为jieba中的分词词典不满足要求所造成的,比如最近非常火的一个词语“奥力给”就是不存在于词典中的,那么我们要怎么去更新我们的词典呢?
词典的静态补充
我们可以自定义词典,以便包含jieba词典中没有的词(虽然jieba有新词识别能力,但是添加自定义词典可以提高准确率)。
词典的添加格式:词语 词频(可省略) 词性(可省略)
我们可以按照上面三个属性去添加新的词语,属性之间用一个空格分开即可。
添加词典的方法函数:
jieba.load_userdict(file_name) # file_name为我们要添加的词典的路径假设我们现在有文件add_words.txt为要添加的词典,词典中设定的内容如下,我们用全分词模式来验证结果。
长江大 5江大桥 3 nz南京市长江 2
import jiebaex = '南京市长江大桥'print("更新前的全分词结果:", "/".join(jieba.cut(ex, cut_all=True)))jieba.load_userdict("add_words.txt")print("更新词典后的全分词结果: ", "/".join(jieba.cut(ex, cut_all=True)))
结果如下:
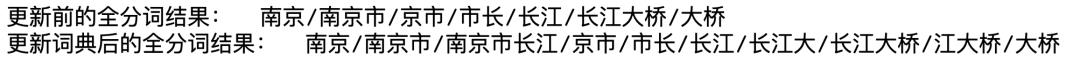
词典的动态补充
我们也可以使用jieba.add_word()和jieba.del_word()两种函数来动态的添加或者删除词语,其中add_word()可以添加词频和词性两种参数,示例如下:
import jiebaex = '南京市长江大桥'print("更新前的全分词结果:", "/".join(jieba.cut(ex, cut_all=True)))jieba.add_word("南京市长江")jieba.add_word("南京市长江", freq=5, tag='nz')jieba.del_word("南京")print("更新词典后的全分词结果:", "/".join(jieba.cut(ex, cut_all=True)))
结果如下:

PART
4
实战:高频词提取
高频词一般是指在文档中出现次数较多且有用的词语,在一定程度上表达了文档的关键词所在;高频词提取中我们主要用到了NLP中的TF策略。
TF指的是某个词语在文章中出现的总次数,我们将文章进行分词,去掉停用词(包括标点符号),然后去统计每个词在文章中出现的次数即可。
停用词:像“的”,“了”这种没有任何意义的词语,我们不需要进行统计。
示例代码如下(示例中随便选取了一篇文章):
# encoding: utf-8import globimport randomimport jieba# 读取文章的函数def get_content(content_path):with open(content_path, 'r', encoding="UTF-8", errors="ignore") as f:content = ''for i in f:i = i.strip()content += ireturn content# 提取topK个高频词的函数# TF:计算某个词在文章中出现的总次数def get_TF(k, words):tf_dic = {}for i in words:tf_dic[i] = tf_dic.get(i, 0) + 1return sorted(tf_dic.items(), key=lambda x: x[1], reverse=True)[:k]# 去掉停用词(包括标点)def stop_words(path):with open(path, encoding='UTF-8') as f:return [l.strip() for l in f]# 主函数if __name__ == "__main__":files = glob.glob("*.txt")corpus = [get_content(x) for x in files]sample_inx = random.randint(0, len(corpus))split_words = [x for x in jieba.cut(corpus[sample_inx])if x not in stop_words("add_words")]print("top(k)个词为:" + str(get_TF(10, split_words)))
结果如下:
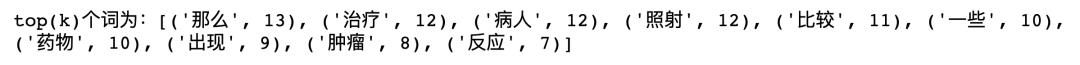

老铁们,长按二维码上车吧!
来都来了,点个好看再走吧~~~
以上是关于分词|Python最好的中文分词库的主要内容,如果未能解决你的问题,请参考以下文章