机器学习基础数学推导+纯Python实现机器学习算法17:XGBoost
Posted 机器学习初学者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础数学推导+纯Python实现机器学习算法17:XGBoost相关的知识,希望对你有一定的参考价值。
Python机器学习算法实现
Author:louwill
Machine Learning Lab
-
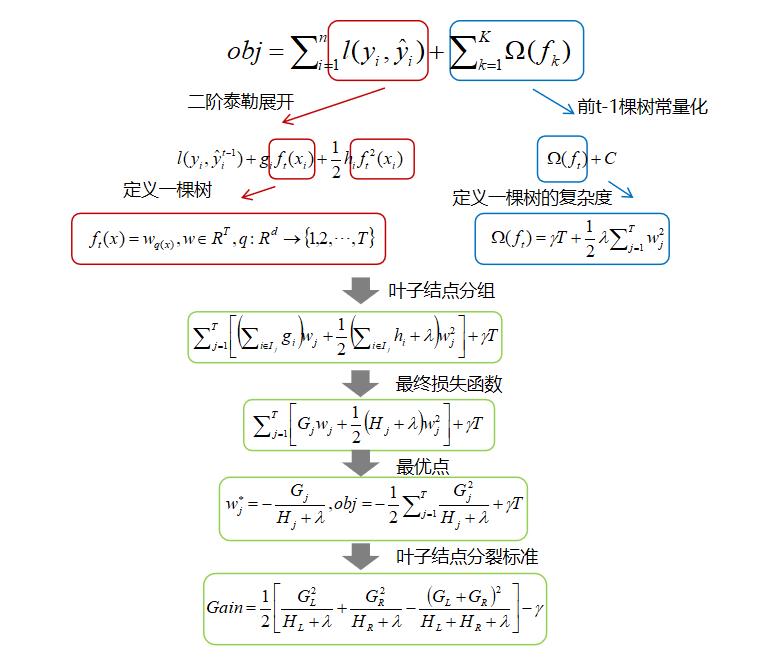
:叶子结点 所包含样本的一阶偏导数累加之和,是一个常量; -
:叶子结点 所包含样本的二阶偏导数累加之和,是一个常量;
class XGBoostTree(Tree):# 结点分裂def _split(self, y):col = int(np.shape(y)[1]/2)y, y_pred = y[:, :col], y[:, col:]return y, y_pred# 信息增益计算公式def _gain(self, y, y_pred):Gradient = np.power((y * self.loss.gradient(y, y_pred)).sum(), 2)Hessian = self.loss.hess(y, y_pred).sum()return 0.5 * (Gradient / Hessian)# 树分裂增益计算def _gain_by_taylor(self, y, y1, y2):# 结点分裂y, y_pred = self._split(y)y1, y1_pred = self._split(y1)y2, y2_pred = self._split(y2)true_gain = self._gain(y1, y1_pred)false_gain = self._gain(y2, y2_pred)gain = self._gain(y, y_pred)return true_gain + false_gain - gain# 叶子结点最优权重def _approximate_update(self, y):# y split into y, y_predy, y_pred = self._split(y)# Newton's Methodgradient = np.sum(y * self.loss.gradient(y, y_pred), axis=0)hessian = np.sum(self.loss.hess(y, y_pred), axis=0)update_approximation = gradient / hessianreturn update_approximation# 树拟合方法def fit(self, X, y):self._impurity_calculation = self._gain_by_taylorself._leaf_value_calculation = self._approximate_updatesuper(XGBoostTree, self).fit(X, y)
class XGBoost(object):def __init__(self, n_estimators=200, learning_rate=0.001, min_samples_split=2,min_impurity=1e-7, max_depth=2):self.n_estimators = n_estimators # Number of treesself.learning_rate = learning_rate # Step size for weight updateself.min_samples_split = min_samples_split # The minimum n of sampels to justify splitself.min_impurity = min_impurity # Minimum variance reduction to continueself.max_depth = max_depth # Maximum depth for tree# 交叉熵损失self.loss = LogisticLoss()# 初始化模型self.estimators = []# 前向分步训练for _ in range(n_estimators):tree = XGBoostTree(min_samples_split=self.min_samples_split,min_impurity=min_impurity,max_depth=self.max_depth,loss=self.loss)self.estimators.append(tree)def fit(self, X, y):y = to_categorical(y)y_pred = np.zeros(np.shape(y))for i in range(self.n_estimators):tree = self.trees[i]y_and_pred = np.concatenate((y, y_pred), axis=1)tree.fit(X, y_and_pred)update_pred = tree.predict(X)y_pred -= np.multiply(self.learning_rate, update_pred)def predict(self, X):y_pred = None# 预测for tree in self.estimators:update_pred = tree.predict(X)if y_pred is None:y_pred = np.zeros_like(update_pred)y_pred -= np.multiply(self.learning_rate, update_pred)y_pred = np.exp(y_pred) / np.sum(np.exp(y_pred), axis=1, keepdims=True)# 将概率预测转换为标签y_pred = np.argmax(y_pred, axis=1)return y_pred
from sklearn import datasetsdata = datasets.load_iris()X = data.datay = data.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, seed=2)clf = XGBoost()clf.fit(X_train, y_train)y_pred = clf.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print ("Accuracy:", accuracy)
Accuracy: 0.9666666666666667XGBoost也提供了原生的模型库可供我们调用。pip安装xgboost即可:
pip install xgboostimport xgboost as xgbfrom xgboost import plot_importancefrom matplotlib import pyplot as plt# 设置模型参数params = {'booster': 'gbtree','objective': 'multi:softmax','num_class': 3,'gamma': 0.1,'max_depth': 2,'lambda': 2,'subsample': 0.7,'colsample_bytree': 0.7,'min_child_weight': 3,'silent': 1,'eta': 0.001,'seed': 1000,'nthread': 4,}plst = params.items()dtrain = xgb.DMatrix(X_train, y_train)num_rounds = 200model = xgb.train(plst, dtrain, num_rounds)# 对测试集进行预测dtest = xgb.DMatrix(X_test)y_pred = model.predict(dtest)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print ("Accuracy:", accuracy)# 绘制特征重要性plot_importance(model)plt.show();
Accuracy: 0.9166666666666666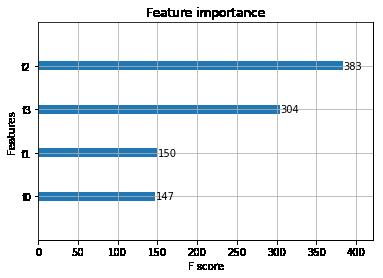
参考资料:
XGBoost: A Scalable Tree Boosting System
https://www.jianshu.com/p/ac1c12f3fba1
往期精彩:
和线性支持向量机
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群:
以上是关于机器学习基础数学推导+纯Python实现机器学习算法17:XGBoost的主要内容,如果未能解决你的问题,请参考以下文章
机器学习强基计划8-3:详细推导核化主成分分析KPCA算法(附Python实现)
机器学习强基计划7-4:详细推导高斯混合聚类(GMM)原理(附Python实现)