自然语言处理 |收藏!使用Python代码的4种句嵌入技术
Posted 数艺学苑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理 |收藏!使用Python代码的4种句嵌入技术相关的知识,希望对你有一定的参考价值。
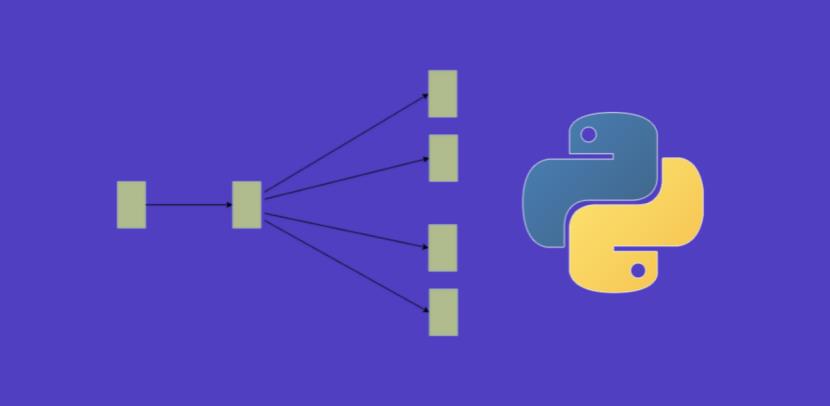
一、什么是词嵌入?
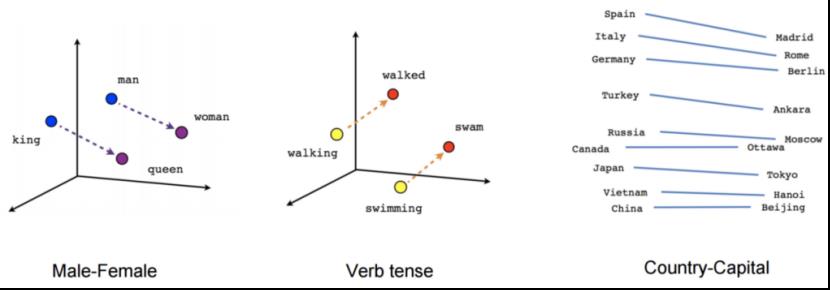
二、什么是句嵌入?
import nltknltk.download('punkt')from nltk.tokenize import word_tokenizeimport numpy as np
sentences = ["I ate dinner.","We had a three-course meal.","Brad came to dinner with us.","He loves fish tacos.","In the end, we all felt like we ate too much.","We all agreed; it was a magnificent evening."]
# Tokenization of each documenttokenized_sent = []for s in sentences:tokenized_sent.append(word_tokenize(s.lower()))tokenized_sent

def cosine(u, v):return np.dot(u, v) / (np.linalg.norm(u) * np.linalg.norm(v))
三、(1)Doc2Vec
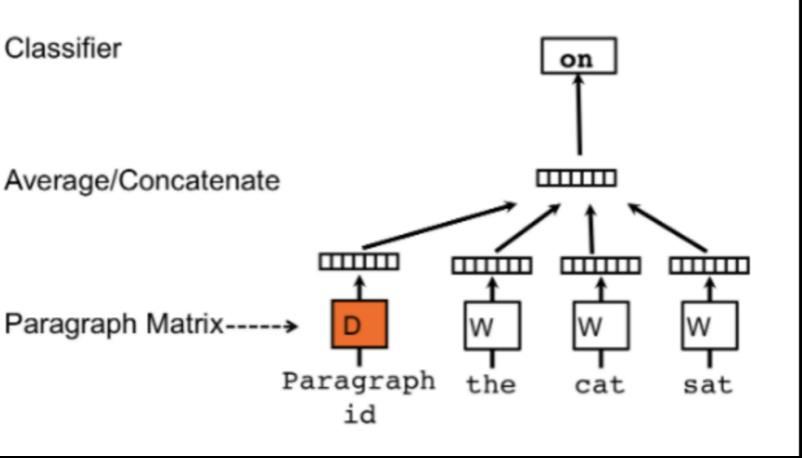
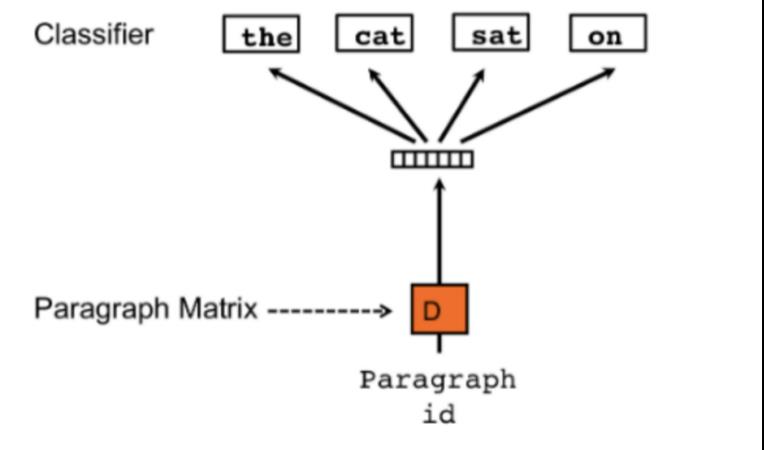
from gensim.models.doc2vec import Doc2Vec, TaggedDocumenttagged_data = [TaggedDocument(d, [i]) for i, d in enumerate(tokenized_sent)]tagged_data

model = Doc2Vec(tagged_data, vector_size = 20, window = 2, min_count = 1, epochs = 100)'''vector_size = Dimensionality of the feature vectors.window = The maximum distance between the current and predicted word within a sentence.min_count = Ignores all words with total frequency lower than this.alpha = The initial learning rate.'''model.wv.vocab

test_doc = word_tokenize("I had pizza and pasta".lower())test_doc_vector = model.infer_vector(test_doc)model.docvecs.most_similar(positive = [test_doc_vector])positive = List of sentences that contribute positively.

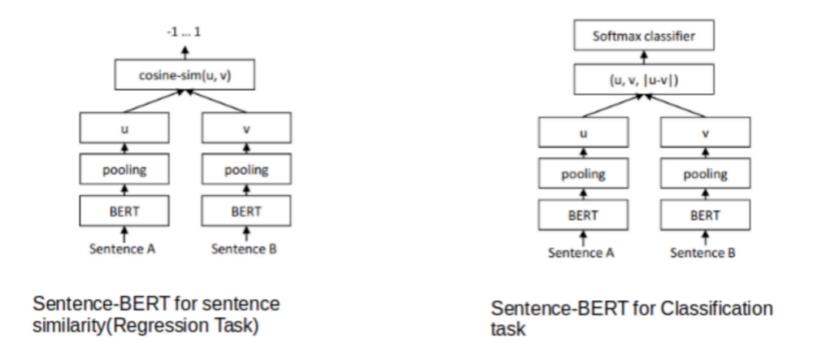
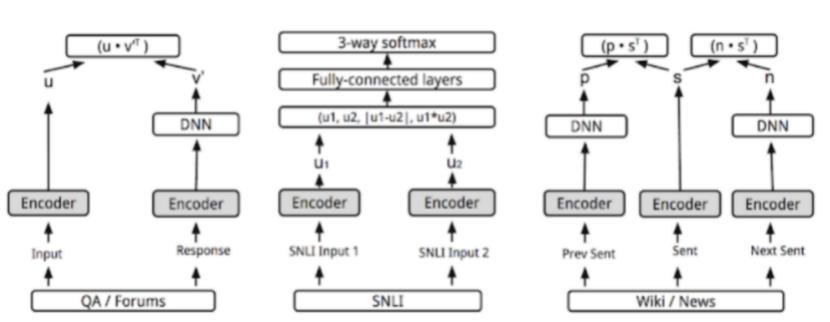
三、(2)SentenceBERT
!pip install sentence-transformersfrom sentence_transformers import SentenceTransformersbert_model = SentenceTransformer('bert-base-nli-mean-tokens')
sentence_embeddings = model.encode(sentences)#print('Sample BERT embedding vector - length', len(sentence_embeddings[0]))print('Sample BERT embedding vector - note includes negative values', sentence_embeddings[0])
query = "I had pizza and pasta"query_vec = model.encode([query])[0]
for sent in sentences:sim = cosine(query_vec, model.encode([sent])[0])print("Sentence = ", sent, "; similarity = ", sim):

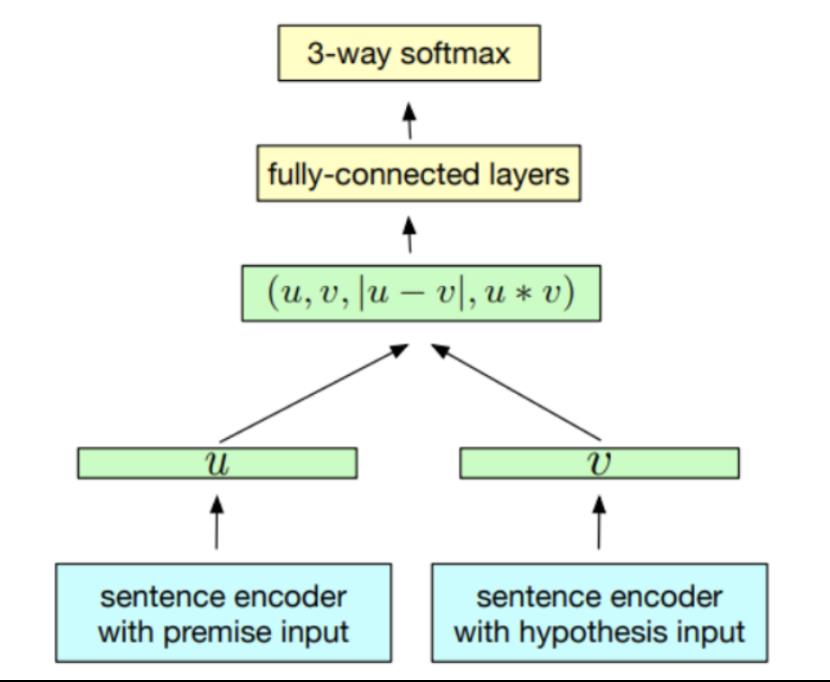
三、(3)InferSent
! mkdir encoder! curl -Lo encoder/infersent2.pkl https://dl.fbaipublicfiles.com/infersent/infersent2.pkl! mkdir GloVe! curl -Lo GloVe/glove.840B.300d.zip http://nlp.stanford.edu/data/glove.840B.300d.zip! unzip GloVe/glove.840B.300d.zip -d GloVe/
from models import InferSentimport torchV = 2MODEL_PATH = 'encoder/infersent%s.pkl' % Vparams_model = {'bsize': 64, 'word_emb_dim': 300, 'enc_lstm_dim': 2048,'pool_type': 'max', 'dpout_model': 0.0, 'version': V}model = InferSent(params_model)model.load_state_dict(torch.load(MODEL_PATH))W2V_PATH = '/content/GloVe/glove.840B.300d.txt'model.set_w2v_path(W2V_PATH)
model.build_vocab(sentences, tokenize=True)
query = "I had pizza and pasta"query_vec = model.encode(query)[0]query_vec

similarity = []for sent in sentences:sim = cosine(query_vec, model.encode([sent])[0])print("Sentence = ", sent, "; similarity = ", sim)

三、(4)Universal Sentence Encoder
!pip3 install --upgrade tensorflow-gpu# Install TF-Hub.!pip3 install tensorflow-hub
import tensorflow as tfimport tensorflow_hub as hubimport numpy as np
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"model = hub.load(module_url)print ("module %s loaded" % module_url)

sentence_embeddings = model(sentences)query = "I had pizza and pasta"query_vec = model([query])[0]
for sent in sentences:sim = cosine(query_vec, model([sent])[0])print("Sentence = ", sent, "; similarity = ", sim)

四、小结



指导老师:
参考文献:
https://www.analyticsvidhya.com/blog/2020/08/top-4-sentence-embedding-techniques-using-python/
https://www.analyticsvidhya.com/blog/2020/10/reinforcement-learning-stock-price-prediction/
以上是关于自然语言处理 |收藏!使用Python代码的4种句嵌入技术的主要内容,如果未能解决你的问题,请参考以下文章