方法教程 | Python 网络爬虫实战:采集知乎一个话题下的全部问题
Posted 爬小虫联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了方法教程 | Python 网络爬虫实战:采集知乎一个话题下的全部问题相关的知识,希望对你有一定的参考价值。
00 制定爬取策略
我们任取一个话题(如:https://www.zhihu.com/topic/20192351/),进入话题的主页,如截图所示。
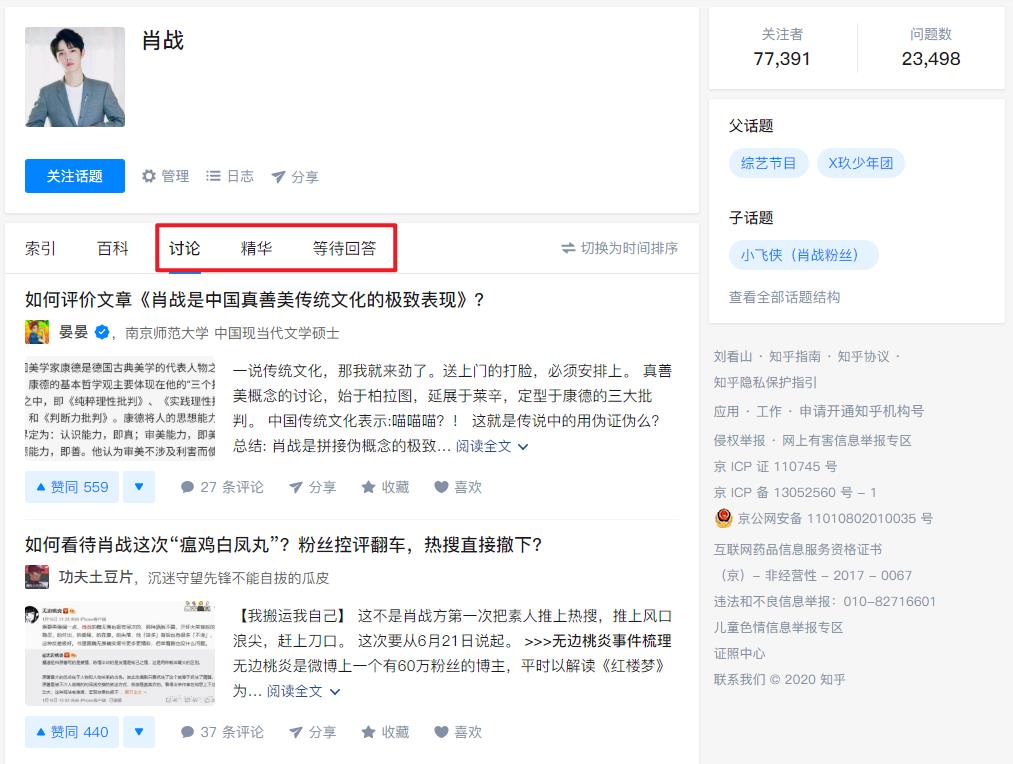
事实上,知乎话题下的所有 “问题” 没有想象中那么容易爬取。
01 抓取数据接口
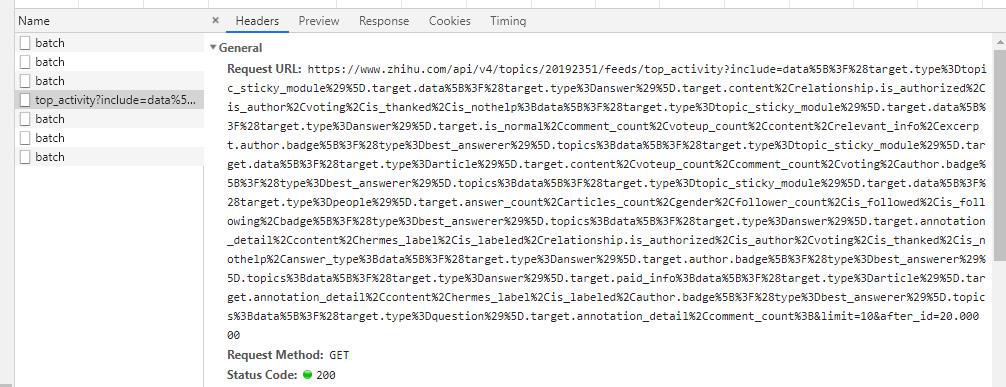
知乎并没有设置特别严格的反爬措施,所以不需要在反反爬方面做特殊处理,设置好参数,直接访问接口就可以了。
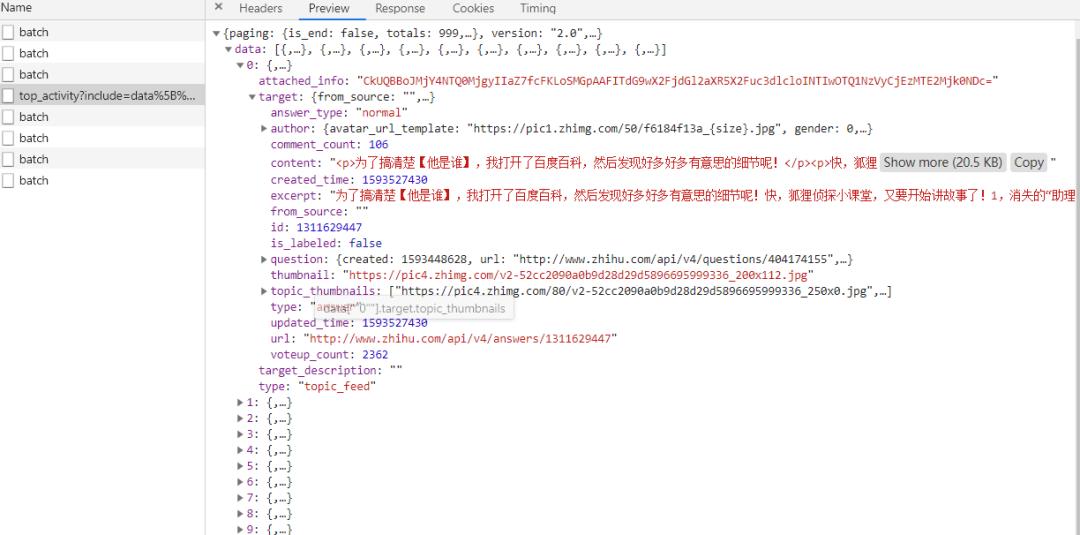
下面简单说一下数据接口,看着很长的一大串,其实只需要关注三个地方就可以了,其他不用管。
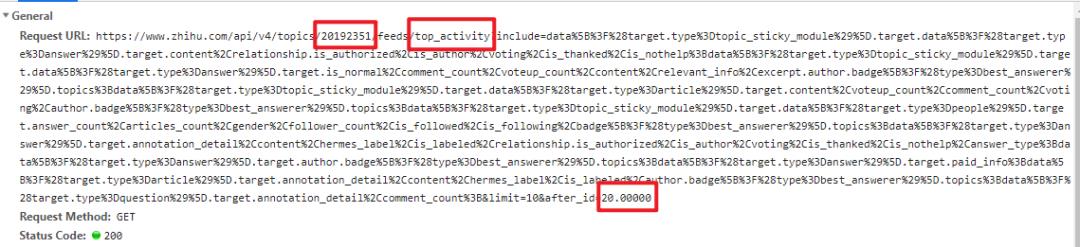
1. 第一处(图中的 20192351 )是话题的 ID,如果后续大家想爬其他话题的话,只需要更改这个参数即可。
2. 第二处(图中的 top_activity )表示是 “讨论”页签的数据接口,同理,“精华”页签是 essence ,“等待回答”是 top_question。
3. 第三处(图中的 20.00000 )是表示该请求的数据是第20条到第30条(从第20条开始的,每页10条数据),可以用它来控制页码,第一页就设置它为 0 (第0 - 9条),第二页就是 10(第10 - 19条)......以此类推
具体分析网站和抓包过程,这里不再赘述了,感兴趣的话,可以参考我之前的爬虫文章。
1. Python网络爬虫实战:爬取知乎话题下 18934 条回答数据
2. Python爬虫基础:使用 Python 爬虫时经常遇到的问题合集
3. Python 爬虫实战系列专栏
02 爬虫代码准备
根据上述的分析,我们可以简单编写一下代码,进行爬取。
import requestsimport jsondef fetchHotel(url):# 发起网络请求,获取数据headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',}# 发起网络请求r = requests.get(url,headers=headers)r.encoding = 'Unicode'return r.textdef parseJson(text):json_data = json.loads(text)lst = json_data['data']nextUrl = json_data['paging']['next']if not lst:return;for item in lst:type = item['target']['type']if type == 'answer':# 回答question = item['target']['question']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)elif type == 'article':#专栏zhuanlan = item['target']id = zhuanlan['id']title = zhuanlan['title']url = zhuanlan['url']vote = zhuanlan['voteup_count']cmts = zhuanlan['comment_count']auth = zhuanlan['author']['name']print("专栏:",id,title)elif type == 'question':# 问题question = item['target']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)return nextUrlif __name__ == '__main__':topicID = '20192351'url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_activity?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&after_id=0'while url:text = fetchHotel(url)url = parseJson(text)

注:
1.爬虫核心部分都在上面了,后面的部分是在此基础上做一些优化,如用数据库,多线程等,不关心的话跳过也没关系。
2.上述代码为“讨论” 页签的爬虫代码,其他两个页签的数据,只需要仿照这个写就可以啦
3.由于页签下混杂着回答,专栏文章,甚至还有广告,所以在解析函数中针对每种类型的数据做了相应的处理。
03 数据库准备
pip install pymysql
import pymysqldb = pymysql.connect(host='xxx.xxx.xxx.xxx', port=3306, user='zhihuTopic', passwd='xxxxxx', db='zhihuTopic', charset='utf8')cursor = db.cursor()
3. 增删改查
通过 pymysql 库操作数据库,实际上也是通过执行 SQL 语句。也就是说,自行构造 SQL 语句的字符串 sql,然后通过 cursor.excute(sql) 执行。
def queryDB():# 查询数据库try:sql = "select * from questions"cursor.execute(sql)data = cursor.fetchone()print(data)except Exception as e:print(e)
def insertDB(id, title, url):#插入数据try:sql = "insert into questions values (%s,'%s','%s')"%(id, title, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)
import requestsimport jsonimport pymysqldb = pymysql.connect(host='xxx.xx.xx.xxx', port=3306, user='zhihuTopic', passwd='xxxxxx', db='zhihuTopic', charset='utf8')cursor = db.cursor()def saveQuestionDB(id, title, url):#插入数据try:sql = "insert into questions values (%s,'%s','%s')"%(id, title, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)def saveArticleDB(id, title, vote, cmts, auth, url):#插入数据try:sql = "insert into article values (%s,'%s',%s,%s,'%s', '%s')"%(id, title, vote, cmts, auth, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)def fetchHotel(url):# 发起网络请求,获取数据headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',}# 发起网络请求r = requests.get(url,headers=headers)r.encoding = 'Unicode'return r.textdef parseJson(text):json_data = json.loads(text)lst = json_data['data']nextUrl = json_data['paging']['next']if not lst:return;for item in lst:type = item['target']['type']if type == 'answer':# 回答question = item['target']['question']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)# 保存到数据库saveQuestionDB(id,title,url)elif type == 'article':#专栏zhuanlan = item['target']id = zhuanlan['id']title = zhuanlan['title']url = zhuanlan['url']vote = zhuanlan['voteup_count']cmts = zhuanlan['comment_count']auth = zhuanlan['author']['name']print("专栏:",id,title)# 保存到数据库saveArticleDB(id, title, vote, cmts, auth, url)elif type == 'question':# 问题question = item['target']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)# 保存到数据库saveQuestionDB(id,title,url)return nextUrlif __name__ == '__main__':topicID = '20192351'# 讨论url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_activity?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&after_id=0'while url:text = fetchHotel(url)url = parseJson(text)# 精华url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/essence?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)# 等待回答url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_question?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)
另,“讨论”,“精华” 页签中除了问题的回答之外,还有一些专栏文章,顺手也爬了存数据库吧。下面是文章的数据表结构。
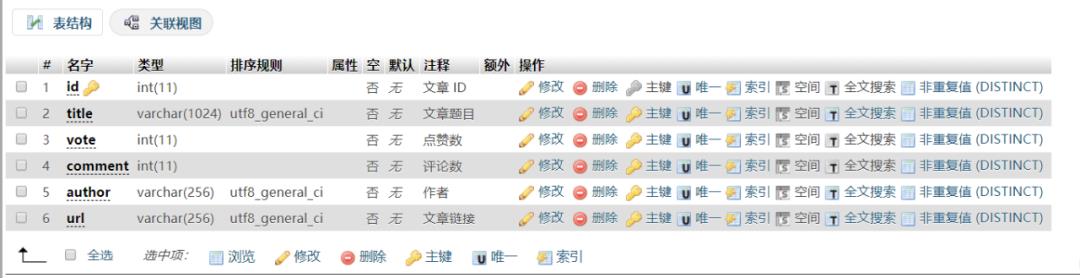
04 多线程准备
前面的代码是单线程爬取。如果不考虑效率的话,大家完全可以等待一个页签中的数据爬取完成之后,继续爬取下一个页签。
但是嘛,那样毕竟比较浪费时间。这里我打算用多线程来爬取,每一个线程爬取一个页签的数据,提高爬虫效率。
import threadingdef crawl_1(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_activity?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&after_id=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_讨论")def crawl_2(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/essence?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_精华")def crawl_3(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_question?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_等待回答")
def main():topicID = '20192351'try:t1 = threading.Thread(target=crawl_1, args=(topicID,))t2 = threading.Thread(target=crawl_2, args=(topicID,))t3 = threading.Thread(target=crawl_3, args=(topicID,))t1.start()t2.start()t3.start()except:print ("Error: 无法启动线程")
lock = threading.Lock()def saveQuestionDB(id, title, url):#插入数据lock.acquire()try:sql = "insert into questions values (%s,'%s','%s')"%(id, title, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)lock.release()
在数据库操作之前 lock.acquire() 上锁,操作完成之后,lock.release() 解锁。
最后,此爬虫的完整代码如下:
import requestsimport jsonimport pymysqlimport threadinglock = threading.Lock()db = pymysql.connect(host='xxx.xx.xx.xxx', port=3306, user='zhihuTopic', passwd='xxxxxx', db='zhihuTopic', charset='utf8')cursor = db.cursor()def saveQuestionDB(id, title, url):#插入数据lock.acquire()try:sql = "insert into questions values (%s,'%s','%s')"%(id, title, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)lock.release()def saveArticleDB(id, title, vote, cmts, auth, url):#插入数据lock.acquire()try:sql = "insert into article values (%s,'%s',%s,%s,'%s', '%s')"%(id, title, vote, cmts, auth, url)cursor.execute(sql)db.commit()except Exception as e:db.rollback()print(e)lock.release()def fetchHotel(url):# 发起网络请求,获取数据headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',}# 发起网络请求r = requests.get(url,headers=headers)r.encoding = 'Unicode'return r.textdef parseJson(text):json_data = json.loads(text)lst = json_data['data']nextUrl = json_data['paging']['next']if not lst:return;for item in lst:type = item['target']['type']if type == 'answer':# 回答question = item['target']['question']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)# 保存到数据库saveQuestionDB(id,title,url)elif type == 'article':#专栏zhuanlan = item['target']id = zhuanlan['id']title = zhuanlan['title']url = zhuanlan['url']vote = zhuanlan['voteup_count']cmts = zhuanlan['comment_count']auth = zhuanlan['author']['name']print("专栏:",id,title)# 保存到数据库saveArticleDB(id, title, vote, cmts, auth, url)elif type == 'question':# 问题question = item['target']id = question['id']title = question['title']url = 'https://www.zhihu.com/question/' + str(id)print("问题:",id,title)# 保存到数据库saveQuestionDB(id,title,url)return nextUrldef crawl_1(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_activity?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&after_id=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_1")def crawl_2(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/essence?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_2")def crawl_3(topicID):url = 'https://www.zhihu.com/api/v4/topics/' + topicID + '/feeds/top_question?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Canswer_type%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.paid_info%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.annotation_detail%2Ccontent%2Chermes_label%2Cis_labeled%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.annotation_detail%2Ccomment_count%3B&limit=10&offset=0'while url:text = fetchHotel(url)url = parseJson(text)print("crawl_3")if __name__ == '__main__':topicID = '20192351'try:t1 = threading.Thread(target=crawl_1, args=(topicID,))t2 = threading.Thread(target=crawl_2, args=(topicID,))t3 = threading.Thread(target=crawl_3, args=(topicID,))t1.start()t2.start()t3.start()except:print ("Error: 无法启动线程")
05 后记
之前的爬虫里我基本很少使用数据库,也很少使用多线程。
不使用数据库,一是因为爬取的数据量较小,保存到本地使用 excel 处理可能更方便;二是作为面向新手的实战教程,使用数据库会增加额外的学习成本(需要安装软件 MySQL,安装额外的库 pymysql,学习额外的语言 SQL)。
不使用多线程,一是没必要,因为数据量太小了;二是减少对方网站服务器的访问压力;三是减少新手学习难度。
但是说实话,在数据量大一些的情况下,使用数据库和多线程的优势立马出来了,数据的存取,爬取的效率等方面都很强悍。
爬取完成之后,总计获取到了 17375 条问题,403 篇专栏文章,共计 17375 条数据。
这是保存下来的Python 网络爬虫实战:爬取知乎一个话题下的全部问题,如有不足之处或更多技巧,欢迎指教补充。愿本文的分享对您之后爬虫有所帮助。谢谢~
编辑排版:筱筱 原创:机灵鹤
以上是关于方法教程 | Python 网络爬虫实战:采集知乎一个话题下的全部问题的主要内容,如果未能解决你的问题,请参考以下文章