巧用线程池
Posted 58招聘技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了巧用线程池相关的知识,希望对你有一定的参考价值。
说起线程池相信很多同学并不陌生,它在多线程开发中占据了重要角色,本文主要介绍线程池的一些使用场景和技巧,以及使用上的误区。
1、线程池使用场景
当我们想在开发过程中借助服务器的多核资源提升程序运行效率时,使用多线程能很好的满足需求,但在这个过程中,频繁的创建和销毁线程会极大的损耗系统资源,而且过多的线程创建会容易导致jvm的内存耗尽和系统线程间过度切换等问题,因而需要我们对多线程进行有效管理,线程池由此被广泛使用。
了解了多线程的背景后那哪些场景适合用线程池来优化处理呢?
1> 减少循环处理同一耗时逻辑时间。当同一逻辑或方法被多次循环调用处理,且多次循环见没有相互依赖关系时,可以使用多线程对其进行优化(如并发调用下游服务或分库查询数据等)。当然,如果整体调用耗时极短则没有必要强行使用线程池,而若将多次循环逻辑拆分出的线程数太多时,则会增加创建线程的开销,需要平衡考量。
2> 提升站点多任务并发处理能力。当需要提升单台站点请求吞吐量时,借助线程池能有效提升整个系统并发处理能力。常见如消息接收处理、服务或web端请求接收等均使用到了线程池,极大提升了集群请求承载能力。
上述是线程池的应用较多的场景,下面介绍下java常用线程池
2、常见线程池介绍
jdk的concurrent并发包为我们提供了多种创建线程池方式,如下所示:
1> newSingleThreadExecutor:创建只有一个线程的线程池。该线程池只有一个线程串行执行所有任务,当该线程出现异常结束时,会重启一个新的线程继续完成后续任务,可保证所有任务执行顺序和提交顺序完全一致。但该线程池内部创建了一个无界等待队列存放请求,当单线程任务处理慢,导致请求队列堆积过大时,甚至引发jvm内存溢出,在高并发场景下不建议使用。
2> newFixedThreadPool:创建固定大小线程池。每当新任务到来便会创建一个线程,直到线程数达到线程池上限。当然该线程池内部创建的仍然是无界队列,因此对线程数大小评估很重要,以免等待队列引发内存溢出。
3> newCachedThreadPool:创建可缓存线程的线程池。当线程池无空闲线程时,会创建新线程(内部使用直接提交队列SynchronousQueue,不缓存任务),当然空闲线程达到失效时间时也会自动回收。而线程数是无上限的,这完全取决于jvm或操作系统所能支持的最大线程数。不过在没有线程数上限情况下,若因单线程处理变慢导致线程数急剧膨胀,也会给内存和系统线程切换造成不可估量的影响,未尝不会出现站点瘫痪的可能。
4> newScheduledThreadPool:创建一个无大小限制的线程池,支持定时和周期性的执行任务。
5> ThreadPoolExecutor:线程池ExecutorService接口的默认实现版本,上面介绍过的四种线程池均为Executors线程池工厂基于ThreadPoolExecutor封装过后的线程池版本。
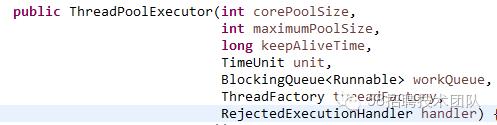
如上所示,ThreadPoolExecutor线程池提供了初始线程数,最大线程数,空闲线程存活时间,等待队列,自定义线程工厂和抛弃策略参数,我们可以灵活的使用这些参数来满足我们的应用场景。
当新任务提交由线程池处理时,其内部执行顺序如下图所示:
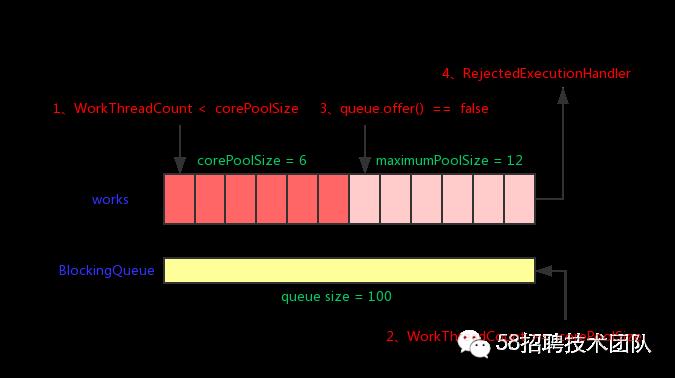
如上图所示,当新任务提交给创建好的线程池时,在线程数未达到corePoolSize数时(1、workThreadCount < corePoolSize)会先创建新线程,而当空闲线程数达到corePoolSize时(2、workThreadCount>= corePoolSize),首先会将任务放到等待队列中,当等待队列放满后(3、queue.offer() == false)才会开辟新的处理线程。最后,当线程数达到最大上限,此时线程池仍未能满足性能要求,则会对新加入的任务调用初始化设置的抛弃策略(4、RejectedExecutionHandler)。
由于开始介绍的前四种ThreadPoolExecutor线程池,使用自定义ThreadPoolExecutor线程池可以避免上述Executors工厂所提供的各种线程池在队列堆积、线程数动态调整、抛弃策略等方面的局限性,建议大家使用自定义线程池来更灵活的支撑我们的应用场景。
3、自定义线程池参数设置
1> 初始线程数设置
ThreadPoolExecutor线程数设置多少很大程度上取决于系统的并发量。以异步消息接收处理为例:我们可以通过压测、观察线上任务耗时,得出单线程平均执行时间t(ms),同时可得到单个线程每秒请求处理个数1000/t,之后根据每秒峰值系统最大请求数q,计算出所需要的最大线程数q/(1000/t)。当然,我们需要为峰值流量预留一定的空闲空间,而集群环境下也要考虑所需的最大线程数需要几台机器来分摊流量,综合考虑后便可得出我们所需的初始化线程数。
当然单台机器可支持的最大线程数并不简单的等同于机器可用核数,这和当前任务归属于cpu密集型还是io密集型有关。对与cpu密集型的计算任务,通常可开最大线程数为机器空闲核数。而io密集型任务,如任务中有大量对磁盘io(文件读写)或者网络io(如下服务调用等)操作时,当前机器可支持的最大线程数通常远大于机器可用核数,我们可通过估算io操作在整个任务中的耗时占比来得到可支持最大线程数是机器可用核数的多少倍,通常对于io密集性操作最大线程可设上限是机器可用核数的10倍甚至更多。
2> 队列长度设置。
线程池的等待队列对整个线程池的请求起到了缓冲作用,有效防止瞬时任务过多,或峰值流量激增所导致的任务丢弃等异常。
对线上实时任务来说,通常不建议将队列长度设置太长或使用无界队列,这样会导致站点重启或站点异常时,堆积在队列的数据丢失。当然,如果业务场景可以接受流量瞬时激增导致的请求抛弃,可将队列长度设置为最大线程数的几倍到几十倍之间即可,快速丢弃到容易堵塞队列的请求(快速失败,避免阻塞)。而如果无法容忍请求丢弃行为,那可以适当延长队列程度来缓解,但是当这种情况频繁发生时且持续时间较长时,你更需要重新评估线程池大小或增加机器部署来满足业务需要。
3> 抛弃策略。
ThreadPoolExecutor提供了四种抛弃策略,最简单的方式是直接丢弃任务。我们可以丢弃当前将要加入队列的任务(1、DiscardPolicy)或丢弃任务队列中最旧的任务(2、DiscardOldestPolicy)。丢弃最旧任务也不是简单的丢弃最老的(即将被执行的)任务,它会尝试重新提交当前任务。我们还可以通过抛出RejectedExecutionException异常的方式(3、AbortPolicy)丢弃任务,不过尽管抛出异常的方式较为简单,但由于抛出了一个RuntimeException,因此会中断调用者的处理过程。最后,还提供了不进入线程池执行的抛弃方式(4、CallerRunsPolicy),将该任务交由调用者线程去执行,虽然并不会真实抛弃任务,但会影响调用者线程性能。
除了上述四种ThreadPoolExecutor定义好的抛弃策略,我们还可以扩展RejectedExecutioHandler接口来实现自定义的抛弃策略,比如发送报警短信&邮件、将抛弃数据持久化存储等,更加灵活的满足我们需求场景。
4、线程池监控
线程池的参数配置设置好后,很难保证随着业务的发展或流量激增,引发线程队列抛弃、线程数资源不足,处理线程异常等问题,这就需要我们对线程池进行监控。常用监控方式如下:
1> 通过线程池抛弃策略监控。可以通过对抛弃次数做全局计数进行报警,也可实时对异常结果做重试补偿、存储等措施,减小因队列溢出或异常提升的失败概率。
2> 定时获取ThreadPoolExecutor状态信息监控。通过ThreadPoolExecutor里提供的获取队列信息(getQueue)、存活线程数(getActiveCount)、运行线程数(getPoolSize)等参数,来监控当前线程数使用情况和线程队列堆积状况,当持续时间较长或达到阀值时,进行报警监控、扩容切换等操作。
通过上述对线程池开发中常用点的介绍,希望帮助大家规避开发过程中的一些常见问题,而对于和线程池相结合使用的多线程回调(Callable&Future)、线程同步策略(CountDownLatch)等就不在此赘述了,欢迎大家补充指正。最后希望大家都能巧线程池,使我们的站点性能更上一层楼。

我们是
58招聘技术
在这里
有我们的技术实践
我们探索新技术
带给你不一样的收获
以上是关于巧用线程池的主要内容,如果未能解决你的问题,请参考以下文章