线程池(上)
Posted 带剑书生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池(上)相关的知识,希望对你有一定的参考价值。
线程池
什么是线程池?为什么要使用线程池?
进行数据库开发的时候,我们应该都接触过数据库连接池,为了避免每次进行数据库连接的时候都重新新建和销毁数据库连接,我们可以使用一个数据库连接池来维护一些数据库连接,让他们长期保持一个激活的状态,当系统需要使用使用数据库的时候,就从连接池中拿来一个可用的连接即可,而不是创建新的连接。反之,当我们需要关闭连接的时候,也不是真的关闭连接,而是将这个连接返还给连接池。通过这样的方式,可以节约不少的创建和销毁对象的时间。其实线程池也是类似的概念,线程池中总有那么几个活跃的线程,当你需要的时候可以从线程池里随便拿来一个空闲线程,当完成工作时并不着急关闭线程,而是返回给线程池,方便其他人使用。 这里我们肯定还有疑问为什么我们传统的创建自定义线程有什么问题?问题就是虽然线程是一种轻量级的工具,但它的创建和关闭都需要花费时间,如我们在程序中随意的创建线程而不加控制其数量,反而会耗尽cpu和内存资源。即便没有outofmemory异常,大量的回收线程也会导致GC停顿的时间延长。所以我们实际中可以优先考虑使用线程池对线程进行控制和管理,更加有效的合理的使用线程进行提高程序的性能。
JDK对线程池的支持
Jdk提供了一套Executor框架,核心成员如下图:
其中ThreadPoolExecutor是一个线程池,Executors扮演着一个线程工厂的角色,通过Executors类可以取得一个具有特定功能的线程池。通过UML图我们可以看到ThreadPoolExecutor实现Executor接口通过这个接口,任何Runable对象都可以被ThreadPoolExecutor线程池调度。 Executors主要提供以下工厂方法:
static ExecutorService newCachedThreadPool()
static ExecutorService newFixedThreadPool(int nThreads)
static ExecutorService newSingleThreadExecutor()
static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
static ScheduledExecutorService newSingleThreadScheduledExecutor()
newCachedThreadPool()方法:该方法返回一个会根据实际情况进行调整的线程池,线程数量不确定。但若有空闲的线程可复用,则优先选择可复用的线程。若当先线程都在工作,同时又有新的任务提交,则会创建新的线程来处理。所有线程在当前任务完成的时候,将返回线程池进行复用。 newFixedThreadPool(int nThreads)方法:该方法返回一个具有固定数量的线程的线程池。该线程池中的线程数量始终不变。当一个任务提交时,若有空闲线程则执行,若没有,会被交给一个任务队列,当有空闲线程的时候,就会处理任务队里的任务。 newScheduleThreadPool(int corePoolSize)方法:该方法会返回一个ScheduledExecutorService对象。ScheduledExecutorService接口在ExecutorService接口的基础上扩展了在给定时间执行某任务的功能,如某个固定时间后开始执行,或者周期性的执行某个任务。 newSingleThreadScheduleExecutor();也返回一个ScheduledExecutorService对象,不过线程池只有一个线程。
有时间计划的任务 newScheduleThreadPool(int corePoolSize)返回一个ScheduleExecutorService对象,可以根据时间需要对线程进行调度,它的主要方法如下:
ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit)
//创建并执行在给定延迟后启用的一次性操作。
ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
//创建并执行一个在给定初始延迟后首次启用的定期操作,后续操作具有给定的周期;也就是将在 initialDelay 后开始执行,然后在 initialDelay+period 后执行,接着在 initialDelay + 2 * period 后执行,依此类推。
ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)
//创建并执行一个在给定初始延迟后首次启用的定期操作,随后,在每一次执行终止和下一次执行开始之间都存在给定的延迟。
与其他线程池不同,ScheduledExecutorService并不一定会立即安排执行任务,它会在指定的时间,对任务进行调度,起到的计划任务的作用。 这里需要注意的就是scheduleAtFixedRate和scheduleWithFixedDelay这两个方法都是对任务进行周期性的调度,但是又有一点不同。 对于FixedRate的方式来说,任务调度的频率是一定的,它是以上一个任务开始执行的时间为起点,之后的period时间,调度下一次任务。而FixedDealy则是上一个任务结束后,在经过delay对下一次任务进行调度。 如果还有疑问,我们可以官方的文档对它两的解释: scheduleAtFixRate(Runnable command, long initialDealy, long period, TimeUnit unit): Creates and executes a periodic action that becomes enabled first after the given initial delay, and subsequently with the given period; that is executions will commence after initialDelay then initialDelay+period, then initialDelay + 2 * period, and so on. 翻译:创建一个周期性的任务,任务开始于指定的初始延迟,后续的任务按照给定的周期执行:后续第一个任务将会在initialDelay+period,下一个任务将在initialDelay+2period执行。 scheduleWithFixedDelay(Runnable command, long initialDealy, long delay, TimeUnit unit): Creates and executes a periodic action that becomes enabled first after the given initial delay, and subsequently with the given delay between the termination of one execution and the commencement of the next. If any execution of the task encounters an exception, subsequent executions are suppressed. Otherwise, the task will only terminate via cancellation or termination of the executor. 翻译:创建一个周期性的任务,任务开始于指定的初始延迟,后续的任务按照给定的延迟执行,即上一个任务结束的时间到下一个任务开始时间的时间差。 下面可以简单演示下ScheduledExecutorService的scheduleAtFixedRate的方法:
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* ScheduledExecutorService的简单示例
* @author zdm
*
*/
public class ScheduleExecutorServiceDemo {
public static void main(String[] args) {
ScheduledExecutorService ses = Executors.newScheduledThreadPool(10);
ses.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println(System.currentTimeMillis()/1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}
这个任务执行使用一秒,周期为2秒,也就是2秒执行一次任务,刚好运行结果符合我们的预期目标。 但是这里有一个问题就是如果任务的执行时间大于调度周期的时间会发生怎么办?这里我们将TimeUnit.SECONDS.sleep(5)尝试一下
线程池的内部实现
对于核心的那几个线程池,尽管看上去功能各不相同其实内部都是使用ThreadPoolExecutor实现:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
从上面我们可以发现它们都是ThreadPoolExecutor的封装,为什么功能如此强大?我们可以看一下ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
方法的参数含义如下: corePoolSize:表示线程中的线程数量。 maximuumPoolSize:表示线程池中最大的线程数量。 keepAliveTime:当线程数量超过corePoolSize时,多余的空闲线程的存活时间 unit:表示存活时间单位 workQueue:任务队列,被提交但却没有没执行的任务。 threadFactory:线程工厂,用于创建线程,一般用默认的即可。 handler:拒绝策略,当任务太多来不及处理时,如何拒绝。 其中的参数workQueue是一个BlockingQueue
BlockingQueue介绍
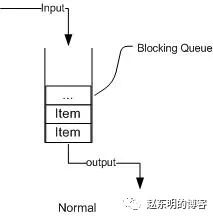
从上图我们可以很清楚看到,通过一个共享的队列,可以使得数据由队列的一端输入,从另外一端输出; 常用的队列主要有以下两种:(当然通过不同的实现方式,还可以延伸出很多不同类型的队列,DelayQueue就是其中的一种) 先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。从某种程度上来说这种队列也体现了一种公平性。 后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发生的事件。
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的数据处理完毕,反之亦然。然而,在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。好在此时,强大的concurrent包横空出世了,而他也给我们带来了强大的BlockingQueue。(在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒)
下面两幅图演示了BlockingQueue的两个常见阻塞场景:
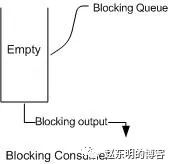
如上图所示:当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
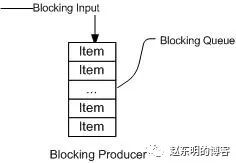
如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
这也是我们在多线程环境下,为什么需要BlockingQueue的原因。作为BlockingQueue的使用者,我们再也不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手包办了。既然BlockingQueue如此神通广大,让我们一起来见识下它的常用方法:
BlockingQueue的核心方法:
offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.(本方法不阻塞当前执行方法的线程)
offer(E o, long timeout, TimeUnit unit),可以设定等待的时间,如果在指定的时间内,还不能往队列中加入BlockingQueue,则返回失败。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻塞直到BlockingQueue里面有空间再继续.
poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null;
poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的数据被加入;
drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
BlockingQueue成员详细介绍
1.ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue;按照实现原理来分析,ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。而在创建ArrayBlockingQueue时,我们还可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。
2.LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。 作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。 ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
3.DelayQueue
DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue是一个没有大小限制的队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。 使用场景: DelayQueue使用场景较少,但都相当巧妙,常见的例子比如使用一个DelayQueue来管理一个超时未响应的连接队列。
4.PriorityBlockingQueue
基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定),但需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁。
5.SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,有点像原始社会中的生产者和消费者,生产者拿着产品去集市销售给产品的最终消费者,而消费者必须亲自去集市找到所要商品的直接生产者,如果一方没有找到合适的目标,那么对不起,大家都在集市等待。相对于有缓冲的BlockingQueue来说,少了一个中间经销商的环节(缓冲区),如果有经销商,生产者直接把产品批发给经销商,而无需在意经销商最终会将这些产品卖给那些消费者,由于经销商可以库存一部分商品,因此相对于直接交易模式,总体来说采用中间经销商的模式会吞吐量高一些(可以批量买卖);但另一方面,又因为经销商的引入,使得产品从生产者到消费者中间增加了额外的交易环节,单个产品的及时响应性能可能会降低。 声明一个SynchronousQueue有两种不同的方式,它们之间有着不太一样的行为。公平模式和非公平模式的区别: 如果采用公平模式:SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体系整体的公平策略。但如果是非公平模式(SynchronousQueue默认):SynchronousQueue采用非公平锁,同时配合一个LIFO队列来管理多余的生产者和消费者,而后一种模式,如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况,即可能有某些生产者或者是消费者的数据永远都得不到处理。所以在使用SynchronousQueue时会设置很大的maximumPoolSize,而否则会很容易执行拒绝策略。
小结
BlockingQueue不光实现了一个完整队列所具有的基本功能,同时在多线程环境下,他还自动管理了多线间的自动等待于唤醒功能,从而使得程序员可以忽略这些细节,关注更高级的功能。 由此可以知道,在使用newCachedThreadPool时,当提交的任务过多时,没有空闲的线程,使用SynchronousQueue,它是直接提交任务的队列,从而迫使线程池创建新的线程来处理任务。当任务执行完成,它会被指定的时间内被回收。因为maximumPoolSize=0。所以当有大量任务提交,而任务的处理又不是很快的情况下,会导致系统资源的耗尽。 使用newFixedThreadPool和newSingleThreadExecutor时应该注意无界的LinkedBlockingQueue的增长。 下面给出线程池的核心调度任务的代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
代码第五行的workerCountOf()方法取得当前线程池中的线程总数,当线程总数小于corePoolSize时,会将任务通过方法addWorker()直接调度。否则workQueue.offer()进入任务队列,如果进入任务队列失败(有界队列到达上限或者使用SynchronousQueue),则会执行17行,将任务提交到线程池,当前线程数达到maximumPoolSize,则提交失败,使用拒绝策略,未达到,则分配线程执行。
参考链接:https://www.cnblogs.com/KingIceMou/p/8075343.html
关于我
以上是关于线程池(上)的主要内容,如果未能解决你的问题,请参考以下文章