解析线程池调度器之任务延迟调度实现机制
Posted 码农每日一题
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解析线程池调度器之任务延迟调度实现机制相关的知识,希望对你有一定的参考价值。

调度线程执行器 ScheduledThreadPoolExecutor 是线程执行器 ThreadPoolExecutor 的扩展,在 ThreadPoolExecutor 基础之上添加了在一定时间间隔之后调度任务的核心功能,也包括之后的按既定时间间隔去调度任务的功能。同时 ScheduledThreadPoolExecutor 是基于线程池的,因此它和 Timer 相比更容易扩展。作者认为任务延迟调度是 STPE 最核心的部分,因此这篇文章主要是通过分析源码来理解 ScheduledThreadPoolExecutor 的任务延迟调度实现机制。
构造方法
在探究 ScheduledThreadPoolExecutor 实现机制之前,我们必须要学会使用它,那么我们首先需要搞清楚两个问题:第一、如何获取 ScheduledThreadPoolExecutor 实例?第二、ScheduledThreadPoolExecutor 为我们提供了哪些接口以及他们的功能是什么?ScheduledThreadPoolExecutor 这个名字有点长,为了简单起见,后文我用(STPE)缩写来代表它。
为解答第一个问题我们先来看看 STPE 提供了哪些构造方法:

上图中我们可以看出 STPE 为我们提供了四个构造方法,用过 ThreadPoolExecutor(简称PTE)的同学都知道我们可以通过构造方法的参数来配置我们所需要线程池的多个参数,包括核心工作线程数、最大工作线程数、线程空闲回收时间、线程工厂、等待队列及队列大小等,但是从 STPE 的构造方法看来我们能配置的似乎并不多,这是因为什么呢?我们可以结合 PTE 的构造方法分析一下,除去核心线程数大小、线程工厂之外,STPE 和 TPE 构造方法的区别有线程数相关(包括核心线程数、最大工作线程数、线程空闲回收)和等待队列。线程数相关似乎和实现任务延迟调度没有什么关系,也的确关系不大,STPE 的实例只是控制了工作线程数为固定大小。那么问题就在于等待队列了。的确,STPE 的四个构造方法都默认使用了一个特殊的队列作为等待队列,叫做 DelayedWorkQueue,我们可以叫它延迟工作队列。
DelayedWorkQueue
DelayedWorkQueue(简称DWQ)和其他的队列有什么不同呢?DWQ 和实现延迟任务有什么关系呢?这是接下来要搞清楚的问题。
我们先来看看DWQ类的继承体系:
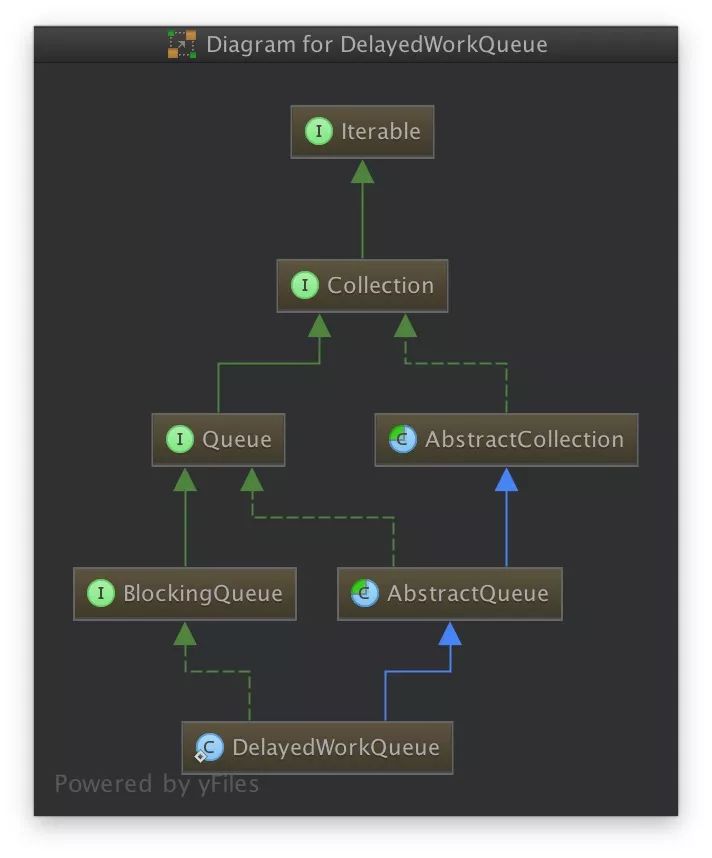
从上图看起来都是很常见的接口似乎没有什么特别之处,尽管这样我们还是简单过一下各个接口及父类给 DWQ 赋予的功能吧。
Iterable 提供了可以迭代的接口,也就是队列中的元素可以通过迭代的方式获取到。
Collection 提供了集合框架的基本接口,JAVA 集合我相信大家都很熟悉。
Queue 提供了队列相关的接口,包括获取队头元素、往队尾增加元素。
AbstractCollection 提供了 Iterable 以及 Collection 的一些默认实现。
BlockingQueue 提供了阻塞队列的相关接口,即表示当线程想从队列中获取元素而队列中没有元素的时候,线程需要被挂起。
剩下的就是 DWQ 的实现了,既然它的主要存储模型是队列,那么我们就看看这个队列的实现吧。
DWQ 的实现队列是由 RunnableScheduleFuture 数组实现的,我们看看存取相关的接口,发现往队列之中添加元素的实现主要是 offer 接口,看下关键实现:
try {
int i = size;
if (i >= queue.length)
grow();
size = i + 1;
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(i, e);
}
if (queue[0] == e) {
leader = null;
available.signal();
}
}
上面代码片段可以看出:如果当前元素数量到达了队列的长度,那么久扩充容量;如果当前队列没有元素,那么直接放在队头;否则调用 siftUp 方法。其实再接着往下看 siftUp 方法的实现,大概大家就明白了其实 DWQ 队列的实现是基于堆实现的:
/**
* Sift element added at bottom up to its heap-ordered spot.
* Call only when holding lock.
*/
private void siftUp(int k, RunnableScheduledFuture key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
而这个堆的顺序,也即大根堆还是小根堆是基于队列中元素实现的 comparable 接口来决定的,但是上面这段代码我们可以确定的是当堆尾元素 compareTo 他的父亲节点 >=0 的时候位置是不用改变的。我们也可以确定一件事情,即当这个堆是小根堆的时候我们从基于小根堆的队列头部获取的元素总是最小的那个,而当这个根是大根堆的时候我们从基于大根堆的队列头部获取的元素总是最大的那个。
RunableScheduleFuture
下面我们再看看队列元素的实现,上文中我们可以知道,DWQ 这个队列只能存储 RunableScheduleFuture(简称RSF)这个类型的元素,我们看看 RSF 的继承体系:
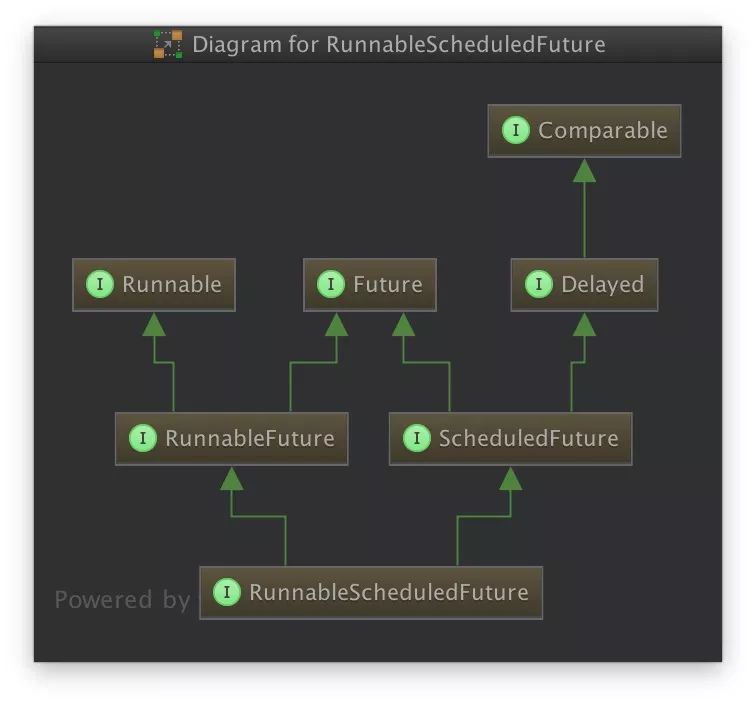
从上面这张图我们可以看出什么呢?来一起简单的过一下:
Comparable 表示 RSF 是可以用来比较的。
Delayed 表示 RSF 是有时间状态的,因此可以用来获取 RSF 对象的在与某个时间比较之后的剩余时间。
Future 表示 RSF 是能够获取异步计算结果的对象。
Runnable 表示 RSF 是个线程对象。
RunnableFuture 表示 RSF 是个可以用来执行的并且能够获取异步计算结果的对象。
ScheduledFuture 表示 RSF 是个可以在指定时间延迟后获取异步计算结果的对象。
RunnableScheduledFuture 表示 RSF 是个可以被执行、且可以在指定时间延迟后获取异步计算内容的线程对象。
最后一步我们通过 RSF 的集成体系总结了 RSF 对象的功能。为了衔接上一部分,我们还需要看看下面的实现:
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) -
other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
这里的实现决定了堆的存储顺序,上面可以看出 RSF 对象的比较其实是按照 time 的自然顺序,time 是什么呢?time 是提交任务的时候设置的延迟时间,也就是我们的任务会在 time 时间之后被调度,那么我们可以得出结论:上文中的队列中,任务的顺序是按照剩余时间基于小根堆排列的,每次调度任务的时候从队列的头部取到的线程对象肯定是最近需要调度的线程对象。
队列内容的获取-线程的延迟调度
上文中我们知道了 DWQ 这个队列本质,那么我们再来看看线程调度的必经之路,调度器是如何从队列中获取内容的。相关接口包括 poll 和 take,poll 和 take 分别是对 Queue 和 BlockingQueue 的实现,他们的主要区别是 poll 在没有获取到内容的时候会直接返回 null,而 take 在没有获取到内容的时候会阻塞。然而、无论是 poll 还是 take,我们都能够从实现中得到一条重要的线索,所有能够获取到的对象必须要满足一个条件:RSF 对象的 getDelay 对象必须要 <=0,也就是线程对象的时间到了,可以被执行了,那么我们才可以获取线程对象并进行调度。
文章到这个时候,我们至少应该非常清楚下面两点:
任务的延迟调度是如何实现的。
任务的调度顺序和任务提交的先后并没有关系。
啊,我好像忘记了介绍 STPE 提供的主要接口和功能,虽然不了解他们并不影响我们队延迟调度实现机制的理解,为了保证文章的完整性,我们再一起看看吧。
STPE 的主要功能
我们先看看 STPE 提供哪些主要接口:

下面四个不需要纠结,他们并不是用来作为提交延迟任务的,而是立即调度。前两个呢,第一个和第二个的都是在指定时间之后调度任务,不同的是 Runnable 和 Callable 的区别。Callable 允许用户获取线程的返回值,而 Runnable 没有。
最重要的就是第三个和第四个了,他们的实现也是很有意思的,看下源代码:
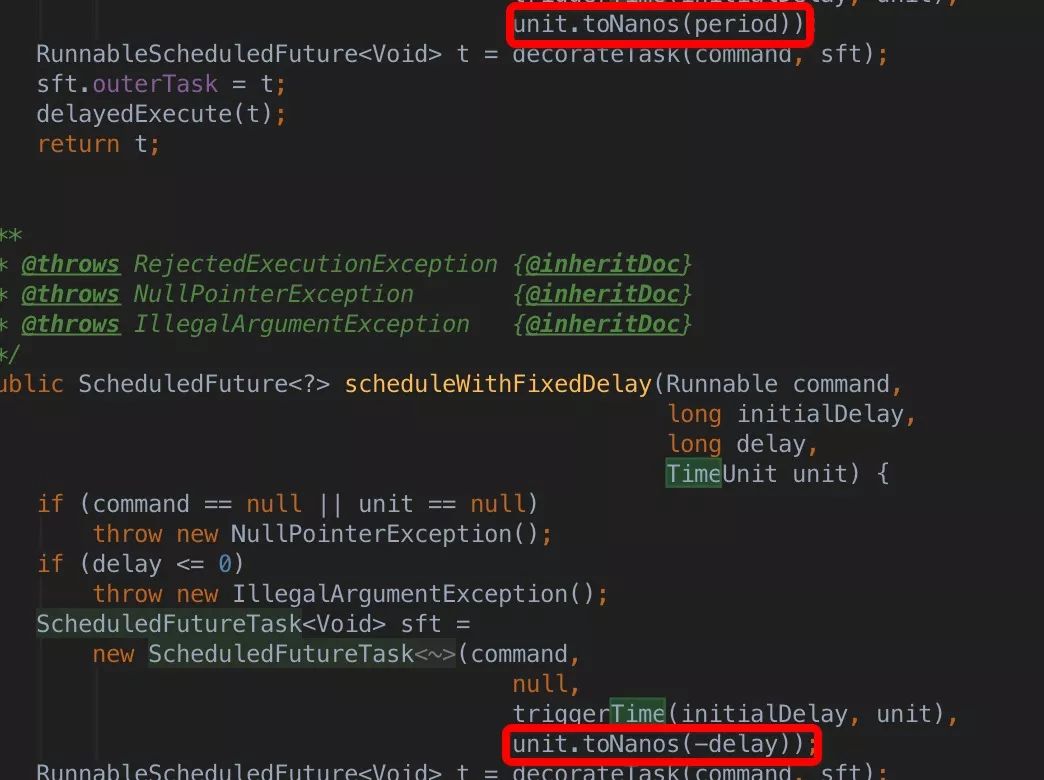
两个方法的实现不同点仅仅在于上图的红框处,博主找了半天,o(╯□╰)o。简单介绍就是上面那个是按照固定时间去调度的,比如设置的初始时间是 2,调度时间间隔是 5,那么低二次调度时间是 2+5,第三次是 2+5*2,依次类推。下面的方法是按照固定的延迟时间去调度,比如初始时间是 2,任务执行长度是 1,那么第二次调度时间是 2+1+5。
本文留下一个问题,上图中的不同是如何巧妙的实现这两种不同的需求的呢?
本文由原作者原创,如有问题欢迎留言。

看完顺手 Option 咯~
本号主打短小精干,点击左下角阅读原文查看历史经典题目汇总~
以上是关于解析线程池调度器之任务延迟调度实现机制的主要内容,如果未能解决你的问题,请参考以下文章