论文阅读 CVPR2017(Best Paper) Densely Connected Convolutional Networks
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读 CVPR2017(Best Paper) Densely Connected Convolutional Networks相关的知识,希望对你有一定的参考价值。
参考技术A大名鼎鼎的DenseNet,17年CVPR的best paper(当然有争议是后话),不得不读。黄高博士的扛鼎之作,之前在读他的Snapshot-Ensembles时感觉就很舒服,整个文章逻辑很清楚,实验对比做的也十分全面,相信这篇best paper更是没有问题,会给读者一种爽的感觉。
2019.2.20 2852次。绝对值很高,但相比其他经典网络,ResNet,GoogLeNet之类,有些差距。
本篇在16年8月挂到arXiv上,中了2017年CVPR,是继16年何大神的ResNet之后,第二个华人的best paper, 这里 有个作者本尊的talk,现场讲解。一作Gao Huang(黄高)05年北航的本科生(GPA第一),15年清华博士毕业(读了6年。。),后来在康奈尔待了3年做博后,此刻在清华作青椒,本篇是在康奈尔时的工作。二作刘壮(同等贡献)也是碉堡,现在在伯克利做博士生,之前是清华姚班的(13级),发这篇文章时还在清华,也就是说 本科生 。。。最近以一作的身份新发了一篇《Rethinking the Value of Network Pruning》,中了19年的ICLR,同时也是18年NIPS的best paper award。。这个世界太疯狂了,这都不是潜力股了,而是才华横溢溢的不行了。
官方实现在这里: https://github.com/liuzhuang13/DenseNet
黄高个人主页在这里: http://www.gaohuang.net/
刘壮个人主页在这里: https://liuzhuang13.github.io/
先前的研究中说明只要网络包含短路连接,基本上就能更深,更准确,更有效的训练。本文基于这个观察,引入了密集卷积网络(DenseNet),它以前馈方式将每个层连接到所有层。传统的卷积网络L层有L个连接,而DenseNet有 个直接连接。对于每一层,它前面所有层的特征图都当作输入,而其本身的特征图作为所有后面层的输入(短路连接被发挥到极致,网络中每两层都相连)。DenseNet具有几个引入注目的优点: 可以缓解梯度消失问题,加强特征传播,鼓励特征重用,并大幅减少参数数量。
随着CNN变得越来越深,一个新的研究问题出现了:随着输入信息或梯度通过多层,它在到达网络结尾(或开始)处就消失了。ResNets和Highway Networks通过恒等连接将信号从一层传输到下一层。Stochastic depth通过在训练期间随机丢弃层来缩短ResNets,以得到更好的信息和梯度流。FractalNets重复组合几个并行层序列和不同数量的卷积块,以获得较深的标准深度,同时在网络中保持许多短路径。尽管上述方法的网络结构都有所不同,但它们有一个共同特征:创建从早期层到后期层的短路径。
本文提出一个简单的连接模式:为了确保网络中各层之间的最大信息流, 将所有层(匹配特征图大小)直接相互连接 。为了保持前向传播性质,每个层从所有前面的层获得附加输入,并将其自身特征图传递给所有后续层。
至关重要的是,与ResNets相比,在传递给下一层之前, 不是通过求和来合并特征,而是通过concat来合并特征 。因此, 层有 个输入,包括所有先前卷积块的特征图。其特征图被传递到后续所有 层。这在L层网络中引入了 个连接,而不是传统架构的L个连接。正是因为这种密集连接模式,所以称本文方法为密集连接网络( Dense Convolutional Network DenseNet)。
相比传统卷积网络,这种密集连接模式有有一点可能违反直觉的是,它需要更少的参数,因为无需重新学习冗余的特征图。本文提出的DenseNet架构显式区分了添加到网络的信息和保留的信息。DenseNet的层非常窄(如每层只有12个滤波器),只给网络的"集体知识"增加一小组特征图,并保持其余的特征图不变。
除了更好的参数利用率之外,DenseNet的一大优势是它改善了整个网络中的信息流和梯度,使得网络更易于训练。每层都可以直接访问损失函数和原始输入信号的梯度( 我屮,这不就是GoogLeNet当时为解决梯度消失而在中间层引入分类器那种ugly办法的替代吗 ),从而导致隐式的深度监督。这有助于训练更深的网络。
与DenseNet相似的级联结构早在1989年就提出来了。。Adanet的提出差不多是与DenseNet并行的,跨层连接也相似(话说竞争真激烈。。)
本文作者提出的另一个网络Stochastic depth说明并非所有层都需要,在深度残差网络中存在大量冗余的层。本文的部分灵感也来源于此。
相比从极深或极宽的架构中提取表示能力,DenseNet是通过 特征重用 来利用网络的潜力,得到易于训练和高参数效率的压缩模型。相比从不同层拼接特征的Inception网络,DenseNet更简单有效(看来Inception因其结构复杂性没少被批判)。
定义 为单张输入图像,网络由 层组成,每一层实现非线性变换 ,其中 为层的索引号。 可以是BN,ReLU,Pooling,Conv等操作的复合函数,定义 层的输出为 。
传统的层连接: 。ResNets增加了跳跃连接: 。ResNets的一个优势是梯度可以通过恒等函数直接从后面的层流向前面的层。然而,恒等函数和 的输出通过加法合并,有可能会阻碍网络的信息流。
本文引入与ResNets不同的连接模式:从任意层到所有后续层的直接连接(图1)。结果就是,第 层接收所有之前层的特征图作为输入: 。为了便于实现,concat 的多个输入为单一张量。
受ResNet v2启发,定义 为三个连续运算的复合函数:BN,ReLU,3 x 3 Conv
当特征图的大小改变时,concat运算是不可能的,然鹅,卷积网络的一个关键组成部分就是下采样层,通过它可以改变特征图大小。为了便于在架构中进行下采样,将网络划分为多个密集连接的密集块(dense blocks),如图2所示。
将密集块之间的层称为过渡层(transition layers),它们进行卷积和池化。本文实验中的过渡层由BN,1 x 1卷积和 2 x 2平均池化组成。
如果每个函数 生成 个特征图,它后面跟着的 层有 个输入特征图,其中 是输入层的通道数。DenseNet和现有网络架构的一个重要区别是DenseNet可以有非常窄的层,如 。本文将超参数 定义为网络的成长率(growth rate)。对此的一种解释是,每一层都可以访问其块中所有前面的特征图,即,网络的『集体知识』。可以将特征图视为网络的全局状态。每一层增加自己的 个特征图到这个状态。成长率反映了每层由多少新信息对全局状态有贡献。全局状态一旦写入,就可以被网络中的任何地方访问,而不像传统网络那样,无需从一层复制到另一层。(全文精华应该就是这一段了)
1x1 conv非常有用(提升计算效率),本文也大用特用。本文定义DenseNet-B的 为 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)
为了使模型更紧凑,可以减少过渡层的特征图数量。如果密集块包含 个特征图,定义接下来的过渡层生成 个特征图,其中 表示压缩率。定义 的DenseNet为DenseNet-C,本位实验中设置为 。当同时使用瓶颈层和压缩过渡层时,定义模型为DenseNet-BC。
非ImageNet数据集采用同一个架构,由3个密集块构成。ImageNet的架构如表1所示
CIFAR SVHN ImageNet
所有网络都用SGD。
CIFAR和SVHN的batch size为64,epoch分别为300和40,初始学习率为0.1,在50%和75%的epoch时分别除10。
ImageNet的batch size为256,90个epoch,初始学习率为0.1,在30和60epoch时分别除10。
weight decay为 ,动量为0.9。用He初始化。
对于CIFAR和SVHN,还在每个卷积层后接了dropout层(除第一个卷积层外),丢失率为0.2。
看表2的最后一行
DenseNet可以利用更大更深模型表示能力的增长。
如图4所示
主要用DenseNet-BC和ResNet作比较。
表面上看,DenseNets和ResNets没什么不同,两个式子的差别仅仅是输入从加法变为concat,然而,这种看似很小的修改导致两种网络架构的行为明显不同。
因为鼓励特征重用,所以得到更紧凑的模型。
如图4所示。
对DenseNets准确率提升的一种解释是各个层通过短路连接从损失函数接收额外的监督(某种深度监督)。DenseNets用隐式的方式执行相似的深度监督:网络顶部的单个分类器通过最多两到三个过渡层为所有层提供直接监督。 然而,由于在所有层之间共享相同的损失函数,因此DenseNets的损失函数和梯度基本上不那么复杂。
和随机深度的对比,随机深度有点类似DenseNet:如果所有中间层都随机丢弃,那么在相同的池化层之间的任意两层都有可能直接连接。
DenseNet就是好,就是好啊就是好。在遵循简单的连接规则的同时,DenseNets自然地整合了恒等映射,深度监督和多样化深度的属性。
又是一篇没有什么数学公式的paper,越来越感觉深度学习像物理,很多结果都是基于做实验得到的。通过对实验的观察对比分析,找出实验中的缺陷不足,从而去改进,然后发paper。黄高博士的写作套路还是非常讨喜的,特别是开头的地方,娓娓道来,一步一步告诉你为什么要这么做,为什么要引入这一步。此外,DenseNets和作者本人的工作『随机深度』也有千丝万缕的关系,看来功夫做扎实了,沿着一条道路是可以出一系列成果的。
这是个好问题。。是要进一步衍生ResNet吗?
提出密集连接结构,将ResNet的跳跃连接发扬光大为两两连接
效果比ResNet还好,通过减少滤波器个数(文中称作成长率),参数量也下来了
感觉效果提升并没有那么明显,被后续出来的ResNeXt超过了
各种网络结构的实现: https://towardsdatascience.com/history-of-convolutional-blocks-in-simple-code-96a7ddceac0c
黄高本人视频讲解: https://zhuanlan.zhihu.com/p/53417625
作者本人的解答: CVPR 2017最佳论文作者解读:DenseNet 的“what”、“why”和“how”
DenseNet的3个优势:
https://towardsdatascience.com/history-of-convolutional-blocks-in-simple-code-96a7ddceac0c
论文阅读:You Only Look Once: Unified, Real-Time Object Detection
Preface
今天详细的看一下 CVPR 2016 年这篇:You Only Look Once: Unified, Real-Time Object Detection。另外,这篇的作者也有Ross B. Girshick。
这篇 Paper 的项目主页在这里:http://pjreddie.com/darknet/yolo/
注:这篇今年 CVPR 2016 年的检测文章 YOLO,我之前写过这篇文章的解读。但因为不小心在 Markdown 编辑器中编辑时删除了。幸好同组的伙伴转载了我的,我就直接考过来了,重新发一下。以后得给自己的博文留个备份。
abstract
这篇文章提出了一个新的物体检测的方法:You Only Look Once(YOLO)。
之前的物体检测方法通常都转变为了一个分类问题,如 R-CNN、Fast R-CNN 等等。另外,关于对 R-CNN、Fast R-CNN、Faster R-CNN 这一系列方法,知乎上有个特别好的帖子:如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法?
而这篇文章将检测变为一个 regression problem,YOLO 从输入的图像,仅仅经过一个 neural network,直接得到 bounding boxes 以及每个 bounding box 所属类别的概率。正因为整个的检测过程仅仅有一个网络,所以它可以直接 end-to-end 的优化。
YOLO 结构十分的快,标准的 YOLO 版本每秒可以实时地处理 45 帧图像。一个较小版本:Fast YOLO,可以每秒处理 155 帧图像,它的 mAP(mean Average Precision) 依然可以达到其他实时检测算法的两倍。
同时相比较于其他的 state-of-art detection systems。尽管 YOLO 的定位更容易出错,这里的 定位出错,即是指 coordinate errors。
但是 YOLO 有更少的 false-positive,文章这里提到了一个词:background errors,背景误差。这里所谓的 背景误差 即是指 False Positive。在这篇 Paper 的Assigned Reviewer 里,有 Reviewer 提到了这个问题:
On overall, the paper reads well, even if some terms such as IOU (I guess it’s the abbreviation of intersection over union but it would be better to say it as it’s not a standard abbreviation) or “background errors” (I’m not really sure of the meaning of this expression. Are they False Positive? If yes, it should be better to use False Positive instead).

最后,YOLO 可以学习到物体的更加泛化的特征,在将 YOLO 用到其他领域的图像时(如 artwork 的图像上),其检测效果要优于 DPM、R-CNN 这类方法。
Introduction
现在的 detection systems 将物体检测问题,最后会转变成一个分类问题。在检测中,detection systems 采用一个 classifier 去评估一张图像中,各个位置一定区域的 window 或 bounding box 内,是否包含一个物体?包含了哪种物体?
一些 detection systems,如 Deformable Parts Models(DPM),采用的是 sliding window 的方式去检测。
最近的 R-CNN、Fast R-CNN 则采用的是 region proposals 的方法,先生成一些可能包含待检测物体的 potential bounding box,再通过一个 classifier 去判断每个 bounding box 里是否包含有物体,以及物体所属类别的 probability 或者 confidence。这种方法的 pipeline 需要经过好几个独立的部分,所以检测速度很慢,也难以去优化,因为每个独立的部分都需要单独训练。
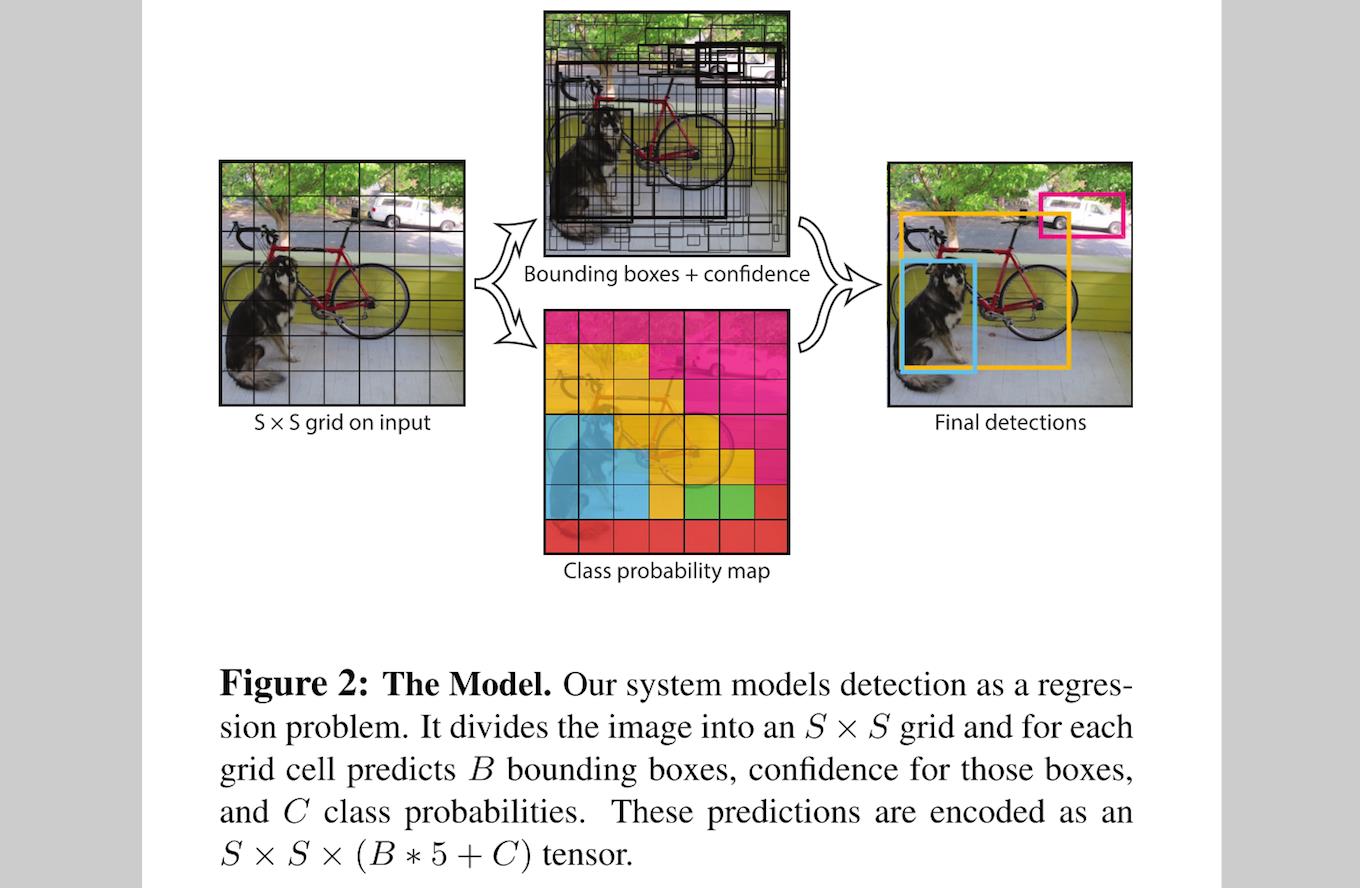
本文将 object detection 的框架设计为一个 regression problem。直接从图像像素到 bounding box 以及 probabilities。这个 YOLO 系统如图看了一眼图像就能 predict 是否存在物体,他们在哪个位置,所以也才叫 You Only Look Once。
YOLO 的 idea 十分简单,如 Figure 1:
将图像输入单独的一个 CNN 网络,就会 predict 出 bounding boxes,以及这些 bounding boxes 所属类别的概率。YOLO 用一整幅图像来训练,同时可以直接优化 detection performance。

这样的统一的架构,对比之前如 R-CNN、Fast R-CNN 的 pipeline,有以下几点好处:
(1)YOLO 检测系统非常非常的快。受益于将 detection 架构设计成一个 regression problem,以及简单的 pipeline。在 Titan X 上,不需要经过批处理,标准版本的 YOLO 系统可以每秒处理 45 张图像;YOLO 的极速版本可以处理 150 帧图像。这就意味着 YOLO 可以以小于 25 毫秒延迟的处理速度,实时地处理视频。同时,YOLO 实时检测的mean Average Precision(mAP) 是其他实时检测系统的两倍。
(2)YOLO 在做 predict 的时候,YOLO 使用的是全局图像。与 sliding window 和 region proposals 这类方法不同,YOLO 一次“看”一整张图像,所以它可以将物体的整体(contextual)的 class information 以及 appearance information 进行 encoding。目前最快最好的Fast R-CNN ,较容易误将图像中的 background patches 看成是物体,因为它看的范围比较小。YOLO 的 background errors 比 Fast R-CNN 少一半多。
(3)YOLO 学到物体更泛化的特征表示。当在自然场景图像上训练 YOLO,再在 artwork 图像上去测试 YOLO 时,YOLO 的表现甩 DPM、R-CNN 好几条街。YOLO 模型更能适应新的 domain。
Unified Detection
YOLO 检测系统,先将输入图像分成 S×S 个 grid(栅格),如果一个物体的中心掉落在一个 grid cell 内,那么这个 grid cell 就负责检测这个物体。
每一个 grid cell 预测 B 个 bounding boxes,以及这些 bounding boxes 的得分:score。这个 score 反应了模型对于这个 grid cell 中预测是否含有物体,以及是这个物体的可能性是多少。正式的公式: Pr(Object)∗IOUtruthpred 。如果这个 cell 中不存在一个 object,则 score 应该为 0 ;否则的话,score 则为 predicted box 与 ground truth 之间的 IoU(intersection over union)。
本文中的每一个 bounding box 包含了 5 个 predictions: x,y,w,h,confidence ,坐标 (x,y) 代表了 bounding box 的中心与 grid cell 边界的相对值。width、height 则是相对于整幅图像的预测值。confidence 就是 IoU 值。
每一个 grid cell 还要预测 C 个 conditional class probability(条件类别概率): Pr(Classi|Object) 。这个 C 基于 gird cell 包含了哪个物体(所以为 conditional probabilities)。不管 grid cell 中包含的 boxes 有多少 B ,每个 grid cell 只 predict 每个类别的 conditional probabilities。
在测试阶段,将每个 grid cell 的 conditional class probabilities 与每个 bounding box 的 confidence 相乘:
上面得到每个 bounding box 的具体类别的 confidence score。这样就把 bounding box 中预测的 class 的 probability,以及 bounding box 与 object 契合的有多好,都进行了 encoding。
将 YOLO 用于 PASCAL VOC 数据集时:
- 本文使用的 S=7 ,即将一张图像分为 7×7=49 个 grid cells
- 每一个 grid cell 预测 B=2 个 boxes(每个 box 是 (x,y,w,h,confidence) , 5 个数值)
- 同时,PASCAL 数据集中有 20 个类别,则,上面的 C=20
因此,最后的 prediction 是
7×7×30
的 tensor
Network Design
YOLO 仍是 CNN 的经典形式,开始是 convolutional layers 提取特征,再是 fully connected layers 进行 predict 结果:probabilities 以及 coordinates。
YOLO 的 CNN 结构取自两篇论文:GoogLeNet、Network in Network. YOLO 有
24
个卷积层,随后就是全连接层。不像 GoogLeNet 中使用的 inception modules,YOLO 采用了 Network in Network 中的结构,在
3×3
卷积层之后,跟着一个
1×1
的层。如下图 Figure 3 所示:

网络结构,更详细的如下表所示:
| Layers | Parameters |
|---|---|
| Input Data | Images Size: 448×448 |
| Convolution | num_filters: 64 , kernel size: 7×7 , stride: 2 |
| Max Pooling | kernel size: 2×2 , stride: 2 |
| Convolution | num_filters: 192 , kernel size: 3×3 , stride: 1 |
| Max Pooling | kernel size: 2×2 , stride: 2 |
| Convolution | num_filters: 128 , kernel size: 1×1 , stride: 1 |
| Convolution | num_filters: 256 |