线程池没你想象的那么简单丨文末送书
Posted 漫话编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池没你想象的那么简单丨文末送书相关的知识,希望对你有一定的参考价值。
前言
原以为线程池还挺简单的(平时常用,也分析过原理),这次是想自己动手写一个线程池来更加深入的了解它;但在动手写的过程中落地到细节时发现并没想的那么容易。结合源码对比后确实不得不佩服 DougLea 。
我觉得大部分人直接去看 java.util.concurrent.ThreadPoolExecutor 的源码时都是看一个大概,因为其中涉及到了许多细节处理,还有部分 AQS 的内容,所以想要理清楚具体细节并不是那么容易。
与其挨个分析源码不如自己实现一个简版,当然简版并不意味着功能缺失,需要保证核心逻辑一致。
所以也是本篇文章的目的:
自己动手写一个五脏俱全的线程池,同时会了解到线程池的工作原理,以及如何在工作中合理的利用线程池。
再开始之前建议对线程池不是很熟悉的朋友看看这几篇:
这里我截取了部分内容,也许可以埋个伏笔(坑)。

创建线程池
现在进入正题,新建了一个 CustomThreadPool 类,它的工作原理如下:
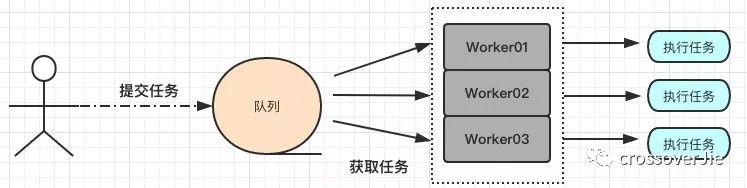
简单来说就是往线程池里边丢任务,丢的任务会缓冲到队列里;线程池里存储的其实就是一个个的 Thread ,他们会一直不停的从刚才缓冲的队列里获取任务执行。
流程还是挺简单。
先来看看我们这个自创的线程池的效果如何吧: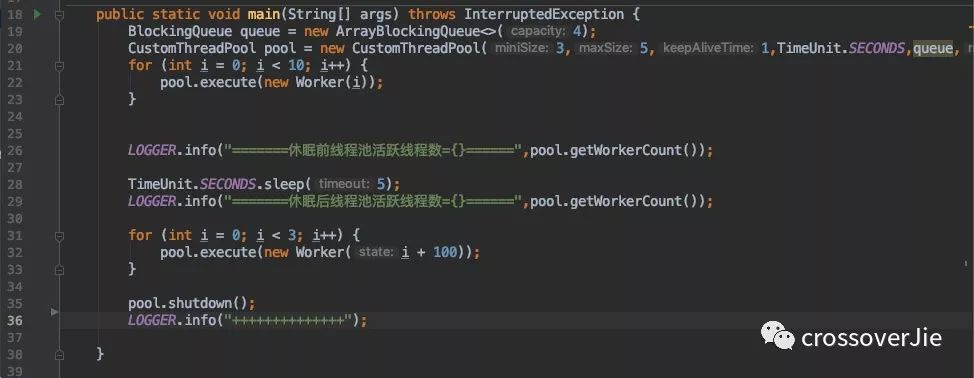
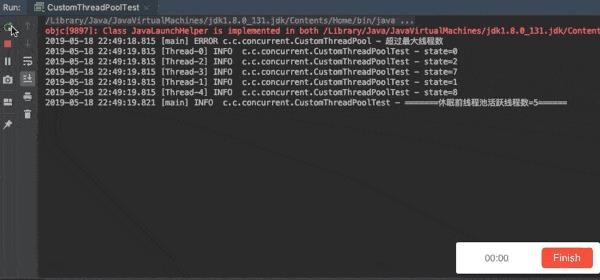
初始化了一个核心为3、最大线程数为5、队列大小为 4 的线程池。
先往其中丢了 10 个任务,由于阻塞队列的大小为 4 ,最大线程数为 5 ,所以由于队列里缓冲不了最终会创建 5 个线程(上限)。
过段时间没有任务提交后( sleep)则会自动缩容到三个线程(保证不会小于核心线程数)。
构造函数
来看看具体是如何实现的。
下面则是这个线程池的构造函数:
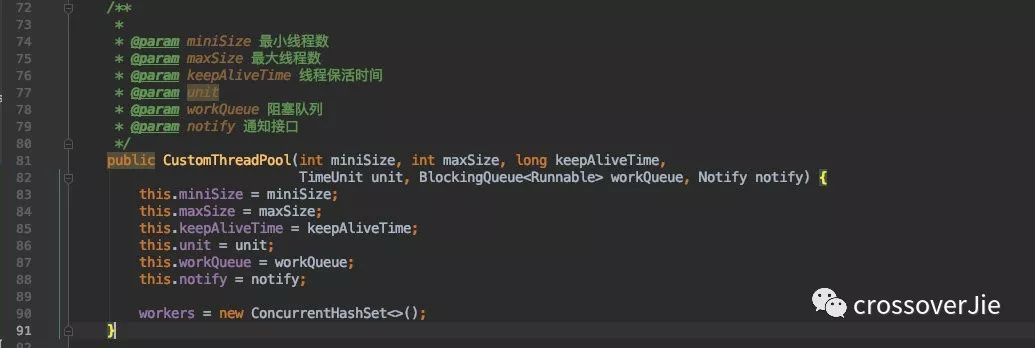
会有以下几个核心参数:
miniSize最小线程数,等效于ThreadPool中的核心线程数。maxSize最大线程数。keepAliveTime线程保活时间。workQueue阻塞队列。notify通知接口。
大致上都和 ThreadPool 中的参数相同,并且作用也是类似的。
需要注意的是其中初始化了一个 workers 成员变量:
/**
* 存放线程池
*/
private volatile Set<Worker> workers;
public CustomThreadPool(int miniSize, int maxSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue, Notify notify) {
workers = new ConcurrentHashSet<>();
}
workers 是最终存放线程池中运行的线程,在 j.u.c 源码中是一个 HashSet 所以对他所有的操作都是需要加锁。
我这里为了简便起见就自己定义了一个线程安全的 Set 称为 ConcurrentHashSet。
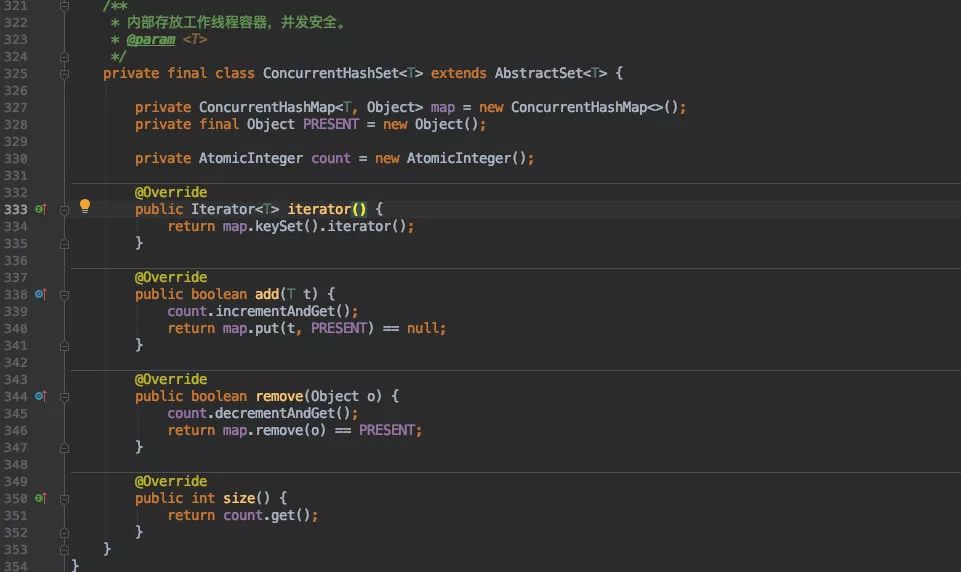
其实原理也非常简单,和 HashSet 类似也是借助于 HashMap 来存放数据,利用其 key 不可重复的特性来实现 set ,只是这里的 HashMap 是用并发安全的 ConcurrentHashMap 来实现的。
这样就能保证对它的写入、删除都是线程安全的。
不过由于 ConcurrentHashMap 的 size() 函数并不准确,所以我这里单独利用了一个 AtomicInteger 来统计容器大小。
创建核心线程
往线程池中丢一个任务的时候其实要做的事情还蛮多的,最重要的事情莫过于创建线程存放到线程池中了。
当然我们不能无限制的创建线程,不然拿线程池来就没任何意义了。于是 miniSize maxSize 这两个参数就有了它的意义。
但这两个参数再哪一步的时候才起到作用呢?这就是首先需要明确的。
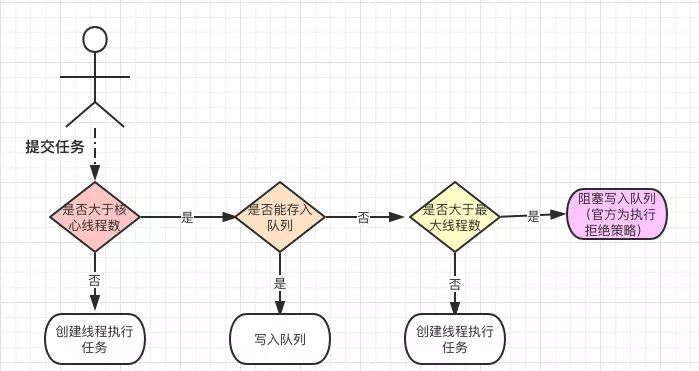
从这个流程图可以看出第一步是需要判断是否大于核心线程数,如果没有则创建。
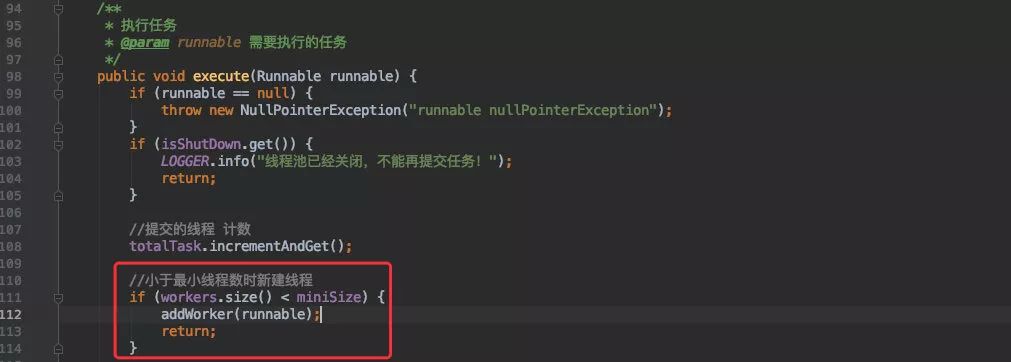

结合代码可以发现在执行任务的时候会判断是否大于核心线程数,从而创建线程。
worker.startTask()执行任务部分放到后面分析。

这里的 miniSize 由于会在多线程场景下使用,所以也用 volatile 关键字来保证可见性。
队列缓冲
结合上面的流程图,第二步自然是要判断队列是否可以存放任务(是否已满)。
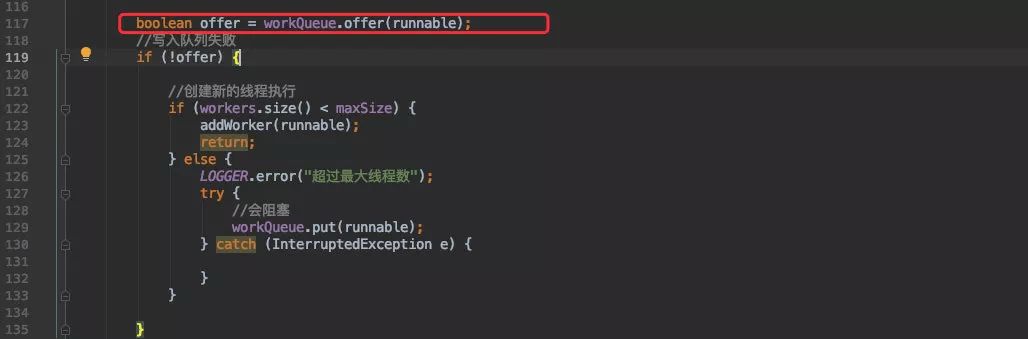
优先会往队列里存放。
上至封顶
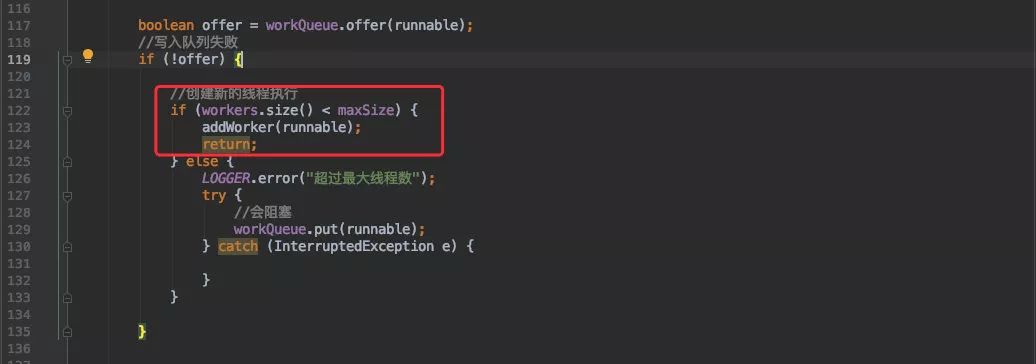
一旦写入失败则会判断当前线程池的大小是否大于最大线程数,如果没有则继续创建线程执行。
不然则执行会尝试阻塞写入队列( j.u.c 会在这里执行拒绝策略)
以上的步骤和刚才那张流程图是一样的,这样大家是否有看出什么坑嘛?
时刻小心
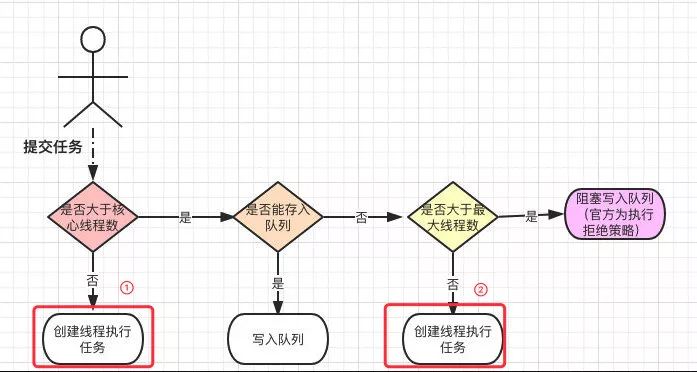
从上面流程图的这两步可以看出会直接创建新的线程。
这个过程相对于中间直接写入阻塞队列的开销是非常大的,主要有以下两个原因:
创建线程会加锁,虽说最终用的是 ConcurrentHashMap 的写入函数,但依然存在加锁的可能。
会创建新的线程,创建线程还需要调用操作系统的 API 开销较大。
所以理想情况下我们应该避免这两步,尽量让丢入线程池中的任务进入阻塞队列中。
执行任务
任务是添加进来了,那是如何执行的?
在创建任务的时候提到过 worker.startTask() 函数:
/**
* 添加任务,需要加锁
* @param runnable 任务
*/
private void addWorker(Runnable runnable) {
Worker worker = new Worker(runnable, true);
worker.startTask();
workers.add(worker);
}
也就是在创建线程执行任务的时候会创建 Worker 对象,利用它的 startTask() 方法来执行任务。
所以先来看看 Worker 对象是长啥样的:
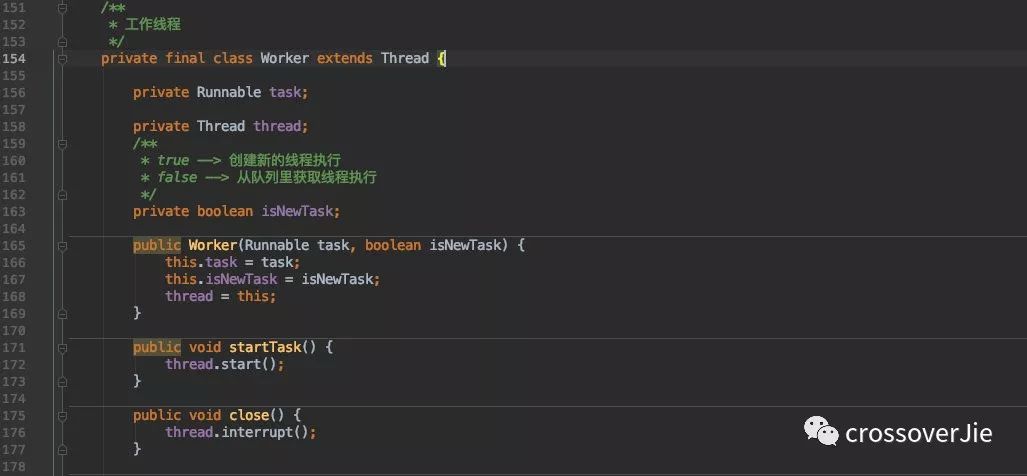
其实他本身也是一个线程,将接收到需要执行的任务存放到成员变量 task 处。
而其中最为关键的则是执行任务 worker.startTask() 这一步骤。
public void startTask() {
thread.start();
}
其实就是运行了 worker 线程自己,下面来看 run 方法。
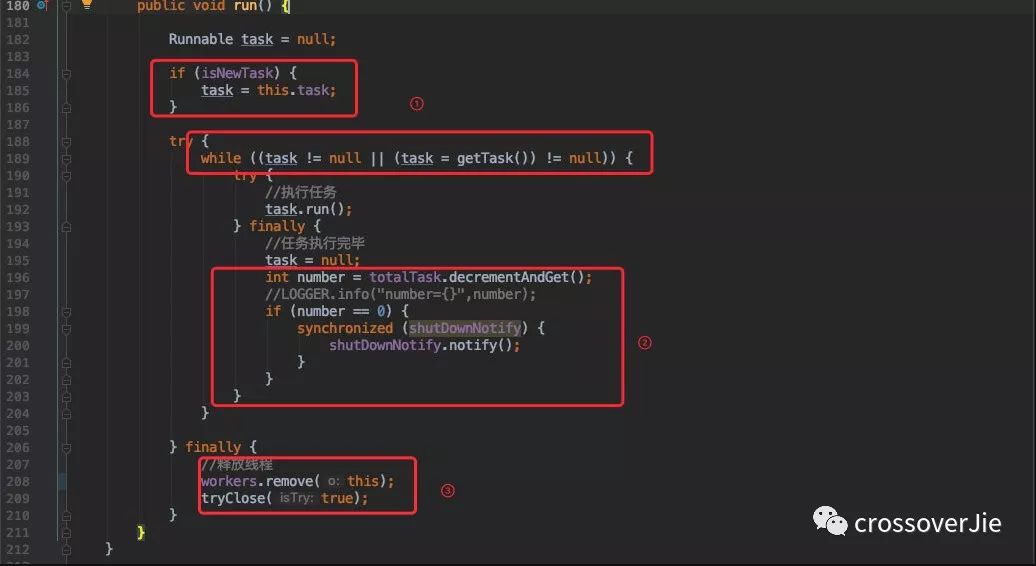
第一步是将创建线程时传过来的任务执行(
task.run),接着会一直不停的从队列里获取任务执行,直到获取不到新任务了。任务执行完毕后将内置的计数器 -1 ,方便后面任务全部执行完毕进行通知。
worker 线程获取不到任务后退出,需要将自己从线程池中释放掉(
workers.remove(this))。
从队列里获取任务
其实 getTask 也是非常关键的一个方法,它封装了从队列中获取任务,同时对不需要保活的线程进行回收。
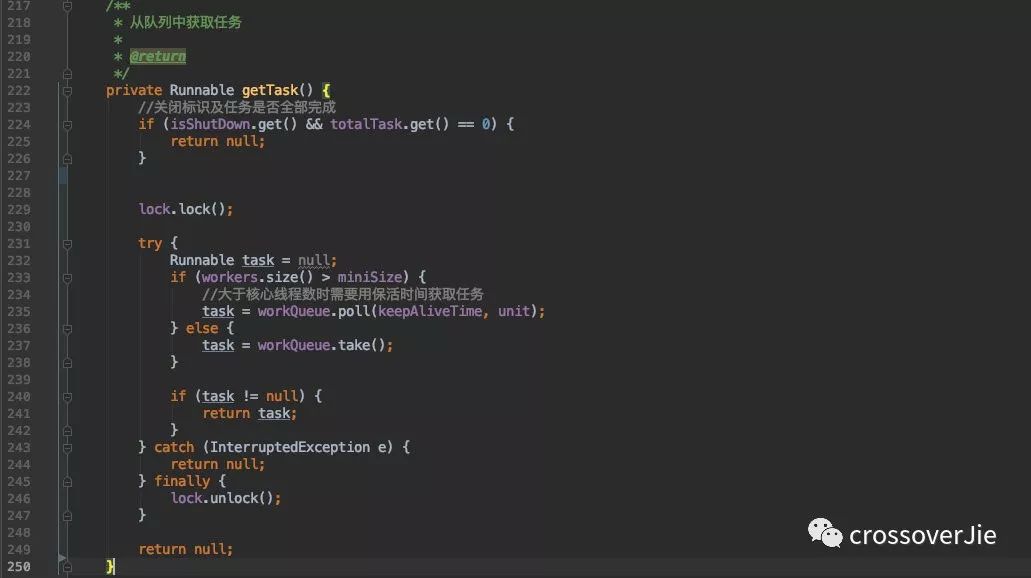
很明显,核心作用就是从队列里获取任务;但有两个地方需要注意:
当线程数超过核心线程数时,在获取任务的时候需要通过保活时间从队列里获取任务;一旦获取不到任务则队列肯定是空的,这样返回
null之后在上文的run()中就会退出这个线程;从而达到了回收线程的目的,也就是我们之前演示的效果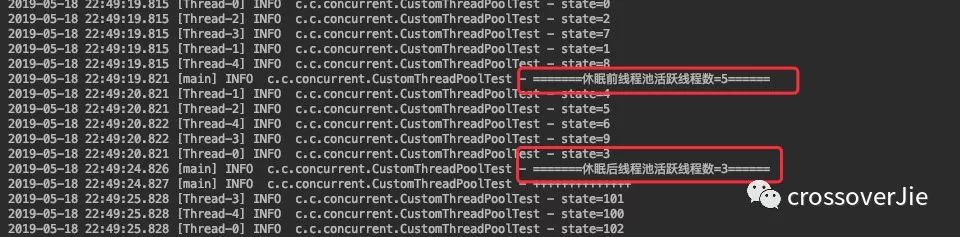
这里需要加锁,加锁的原因是这里肯定会出现并发情况,不加锁会导致
workers.size()>miniSize条件多次执行,从而导致线程被全部回收完毕。
关闭线程池
最后来谈谈线程关闭的事;
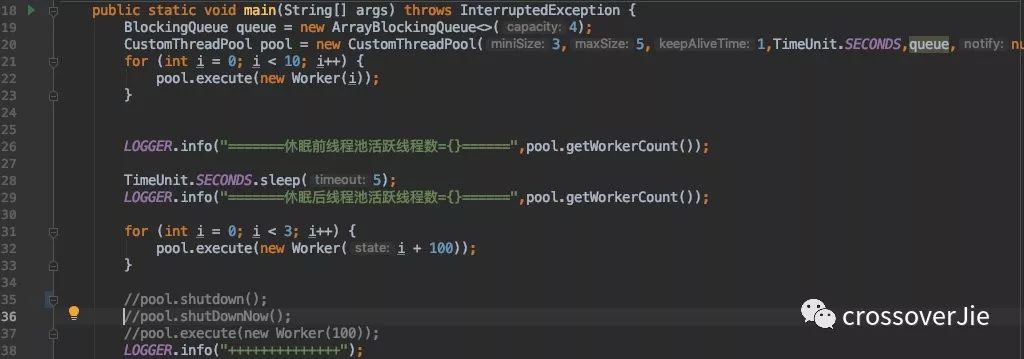
还是以刚才那段测试代码为例,如果提交任务后我们没有关闭线程,会发现即便是任务执行完毕后程序也不会退出。
从刚才的源码里其实也很容易看出来,不退出的原因是 Worker 线程一定还会一直阻塞在 task=workQueue.take(); 处,即便是线程缩容了也不会小于核心线程数。
通过堆栈也能证明:
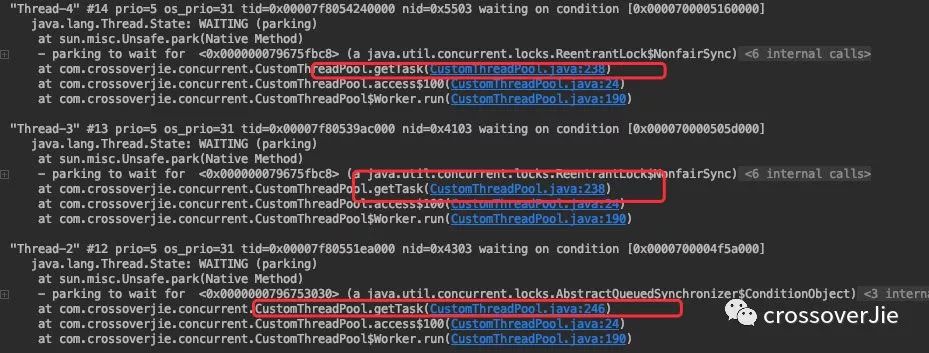
恰好剩下三个线程阻塞于此处。
而关闭线程通常又有以下两种:
立即关闭:执行关闭方法后不管现在线程池的运行状况,直接一刀切全部停掉,这样会导致任务丢失。
不接受新的任务,同时等待现有任务执行完毕后退出线程池。
立即关闭
我们先来看第一种 立即关闭:
/**
* 立即关闭线程池,会造成任务丢失
*/
public void shutDownNow() {
isShutDown.set(true);
tryClose(false);
}
/**
* 关闭线程池
*
* @param isTry true 尝试关闭 --> 会等待所有任务执行完毕
* false 立即关闭线程池--> 任务有丢失的可能
*/
private void tryClose(boolean isTry) {
if (!isTry) {
closeAllTask();
} else {
if (isShutDown.get() && totalTask.get() == 0) {
closeAllTask();
}
}
}
/**
* 关闭所有任务
*/
private void closeAllTask() {
for (Worker worker : workers) {
//LOGGER.info("开始关闭");
worker.close();
}
}
public void close() {
thread.interrupt();
}
很容易看出,最终就是遍历线程池里所有的 worker 线程挨个执行他们的中断函数。
我们来测试一下:
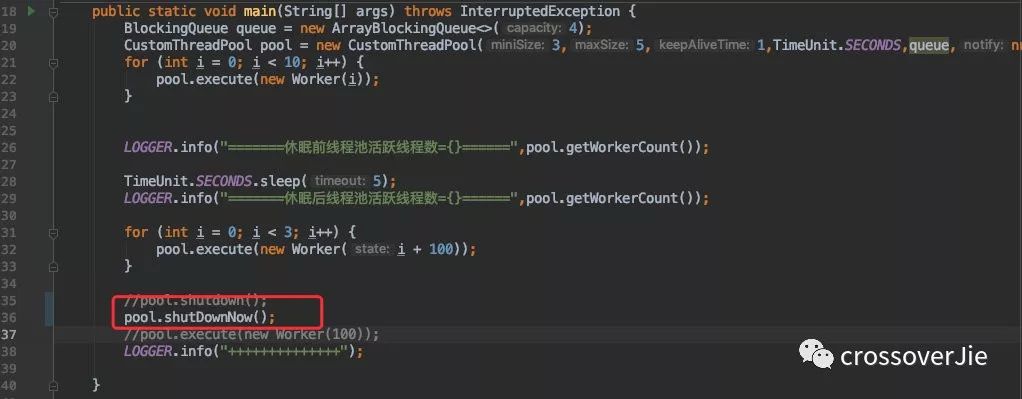
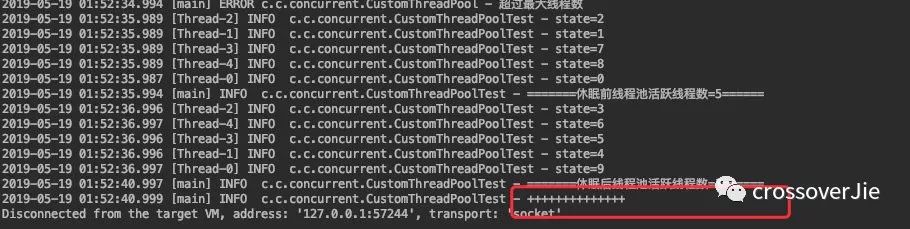
可以发现后面丢进去的三个任务其实是没有被执行的。
完事后关闭
而正常关闭则不一样:
/**
* 任务执行完毕后关闭线程池
*/
public void shutdown() {
isShutDown.set(true);
tryClose(true);
}
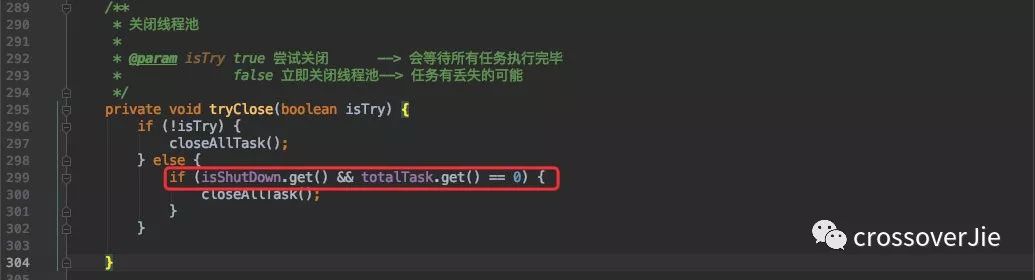
他会在这里多了一个判断,需要所有任务都执行完毕之后才会去中断线程。
同时在线程需要回收时都会尝试关闭线程:

来看看实际效果:
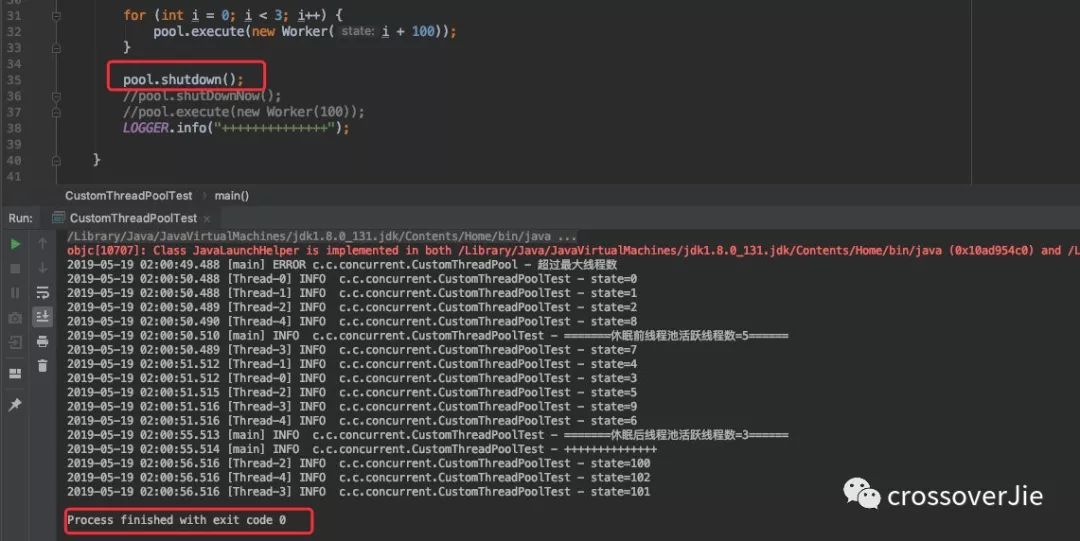
回收线程
上文或多或少提到了线程回收的事情,其实总结就是以下两点:
一旦执行了
shutdown/shutdownNow方法都会将线程池的状态置为关闭状态,这样只要worker线程尝试从队列里获取任务时就会直接返回空,导致worker线程被回收。一旦线程池大小超过了核心线程数就会使用保活时间来从队列里获取任务,所以一旦获取不到返回
null时就会触发回收。
但如果我们的队列足够大,导致线程数都不会超过核心线程数,这样是不会触发回收的。
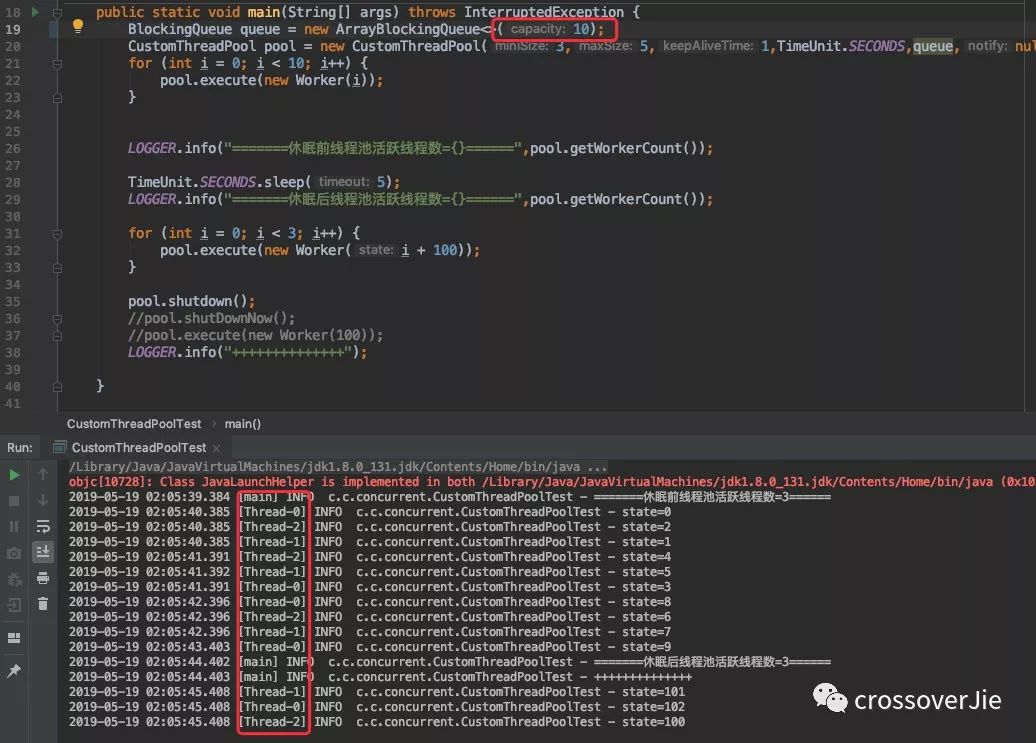
比如这里我将队列大小调为 10 ,这样任务就会累计在队列里,不会创建五个 worker 线程。
所以一直都是 Thread-1~3 这三个线程在反复调度任务。
总结
本次实现了线程池里大部分核心功能,我相信只要看完并动手敲一遍一定会对线程池有不一样的理解。
结合目前的内容来总结下:
线程池、队列大小要设计的合理,尽量的让任务从队列中获取执行。
慎用
shutdownNow()方法关闭线程池,会导致任务丢失(除非业务允许)。如果任务多,线程执行时间短可以调大
keepalive值,使得线程尽量不被回收从而可以复用线程。
同时下次会分享一些线程池的新特性,如:
执行带有返回值的线程。
异常处理怎么办?
所有任务执行完怎么通知我?
本文所有源码:
https://github.com/crossoverJie/JCSprout/blob/master/src/main/java/com/crossoverjie/concurrent/CustomThreadPool.java
福利时间
感谢大家一直以来的支持,本次送出技术书籍5本。书籍是出自著名Java劝退师小马哥之手的《Spring Boot编程思想(核心篇)》
本书的讨论范围并不会局限在Spring Boot 或Spring Framework,会将Spring Cloud 甚至Spring Cloud Data Flow 纳入参考,探讨Spring Boot 在两者中的运用。
本书从源码的角度探讨Spring Boot的核心特性,深入探究Spring Boot的实现原理,期待读者掌握阅读源码的方法和技巧,全面提升研发能力,进军架构师队伍。
如何更好地学习Spring Boot
为了使Spring Boot的学习曲线平滑,本书在内容结构上,采用“总分总”的方式,首先总体介绍讨论范围,随后深入展开细节的讨论,最后予以总结。同时,为了避免先入为主的影响,本书将会针对官方文档的描述内容提出疑问或假设,大胆地猜测其可能实现的方式,再结合实现源码加以验证,随后将通过示例代码巩固理解。
系统掌握Spring Boot 1.x到2.0的各个版本
本书将Spring Boot 2.0与1.x的版本加以对比,探索从1.0到2.0版本之间的重要变化,便于读者后续架构、整合及迁移等工作。
完善的示例代码
本书所有的示例代码均存放在GitHub,不必担心商业用途所带来的风险。
配套的视频
本书在慕课网发布免费配套视频:
Spring Boot 2.0深度实践——初遇Spring Boot
https://www.imooc.com/learn/933
Spring Boot 2.0深度实践之系列总览
https://www.imooc.com/learn/1058
粉丝福利
京东专供签名书签(2500个),先到先得!!!!!!!!!!
PS:只有京东自营店有哦:)
以上是关于线程池没你想象的那么简单丨文末送书的主要内容,如果未能解决你的问题,请参考以下文章