如何正确的使用线程池,避免线上故障?
Posted 程序员泥瓦匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何正确的使用线程池,避免线上故障?相关的知识,希望对你有一定的参考价值。
点击蓝色“泥瓦匠BYSocket”,关注我哟 加个“星标”,不忘签到哦
文|陈阳 on 电商技术
一、悬案

正当虎峰两位同学焦急的以各种姿势查看应用的各项指标时,5分钟过去了,应用居然自己自动恢复了。看似虚惊一场,但果真如此吗?
二、勘查线索
2.1 QPS
“是不是又有商家没有备案就搞活动了啊”,小虎同学如此说道。的确,对于应用突然夯死,大家可能第一时间想到的就是流量突增。流量突增会给应用稳定性带来不小冲击,机器资源的消耗的增加至殆尽,就像我们去自助餐厅胡吃海喝到最后一口水都喝不下,当然也就响应不了新的请求。我们查看了 QPS 的状况。
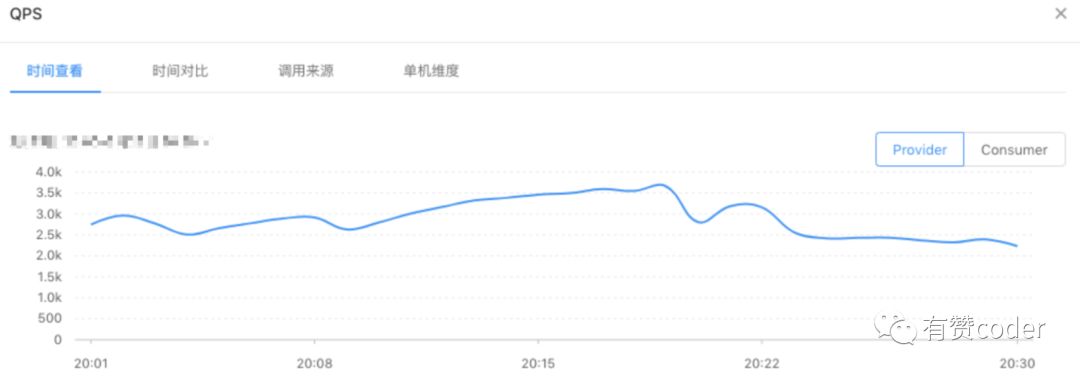
事实让人失望,应用的 QPS 指标并没有出现陡峰,处于一个相对平缓的上下浮动的状态,小虎同学不禁一口叹气,看来不是流量突增导致的.
2.2 GC
“是不是 GC 出问题了”,框架组一位资深的同学说道。JVM 在 GC 时,会因为 Stop The World 的出现,导致整个应用产生短暂的停顿时间。如果 JVM 频繁的发生 Stop The World,或者停顿时间较长,会一定程度的影响应用处理请求的能力。但是我们查看了 GC 日志,并没有任何的异常,看来也不是 GC 异常导致的。
2.3 慢查
“是不是有慢查导致整个应用拖慢?”,DBA 同学提出了自己的看法。当应用的高 QPS 接口出现慢查时,会导致处理请求的线程池中(dubbo 线程池),大量堆积处理慢查的线程,占用线程池资源,使新的请求线程处于线程池队列末端的等待状态,情况恶劣时,请求得不到及时响应,引发超时。但遗憾的是,出问题的时间段,并未发生慢查。
2.4 TIMEDOUT
问题至此已经扑朔迷离了,但是我们的开发同学并没有放弃。仔细的小峰同学在排查机器日志时,发现了一个异常现象,某个平时不怎么报错的接口,在1秒内被外部调用了 500 多次,此后在那个时间段内,根据 traceid 这 500 多次请求产生了 400 多条错误日志,并且错误日志最长有延后好几分钟的。
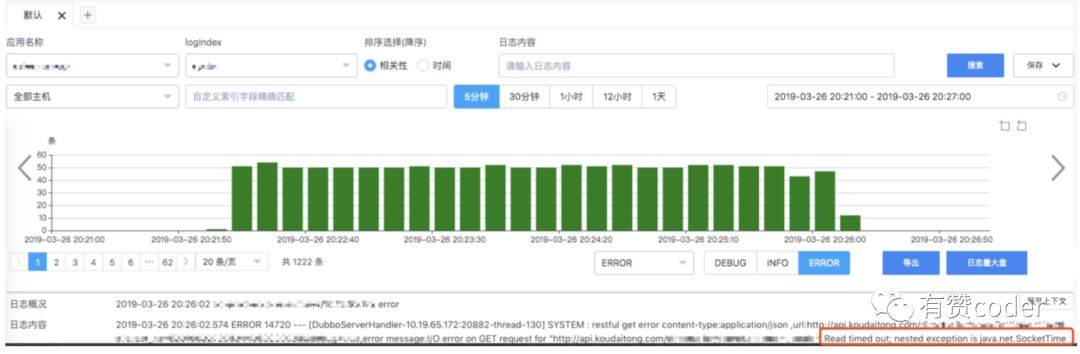
这是怎么回事呢?这里有两个问题让我们疑惑不解:
500 QPS 完全在这个接口承受范围内,压力还不够。
为什么产生的错误日志能够被延后好几分钟。
日志中明显的指出,这个 http 请求 Read timed out。http 请求中读超时设置过长的话,最终的效果会和慢查一样,导致线程长时间占用线程池资源(dubbo 线程池),简言之,老的出不去,新的进不来。带着疑问,我们翻到了代码。
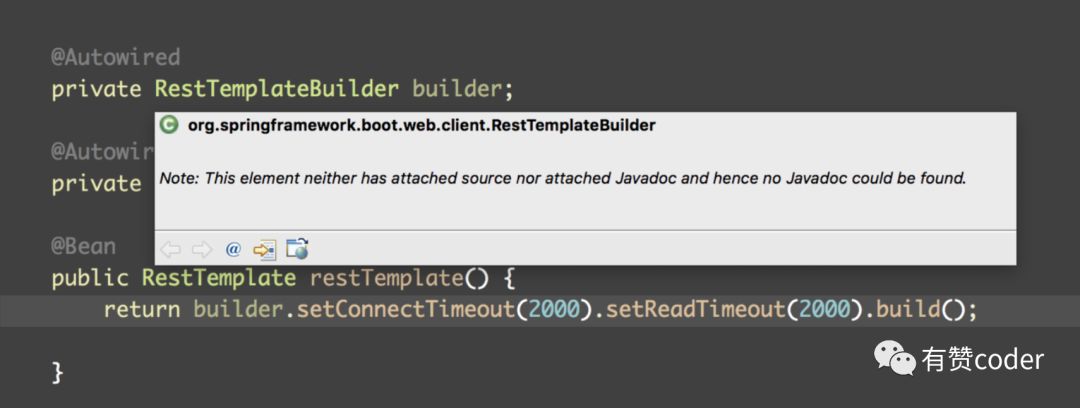
但是代码中确实是设置了读超时的,那么延后的错误日志是怎么来的呢?我们已经接近真相了吗?
三、破案
我们不免对这个 RestTemplateBuilder 起了疑心,是这个家伙有什么暗藏的设置嘛?机智的小虎同学,针对这个工具类,将线上的情况回放到本地进行了模拟。我们构建了 500 个线程同时使用这个工具类去请求一个 http 接口,这个 http 接口让每个请求都等待 2 秒后再返回,具体的做法很简单就是 Thread.sleep(2000),然后观察每次请求的 response 和 rt。
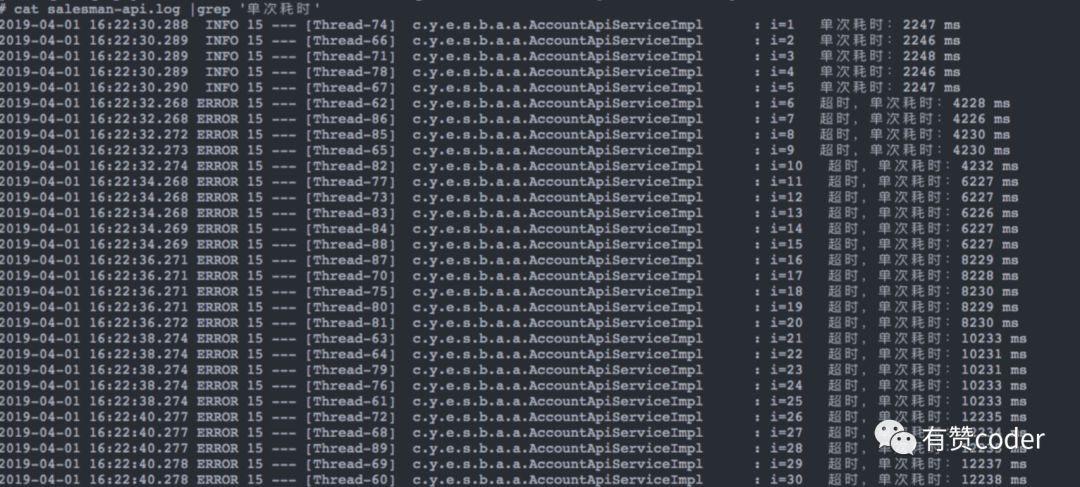
我们发现 response 都是正常返回的(没有触发 Read timed out),rt是规律的5个一组并且有 2 秒的递增。看到这里,大家是不是感觉到了什么?对!这里面有队列!通过继续跟踪代码,我们找到了“元凶”。
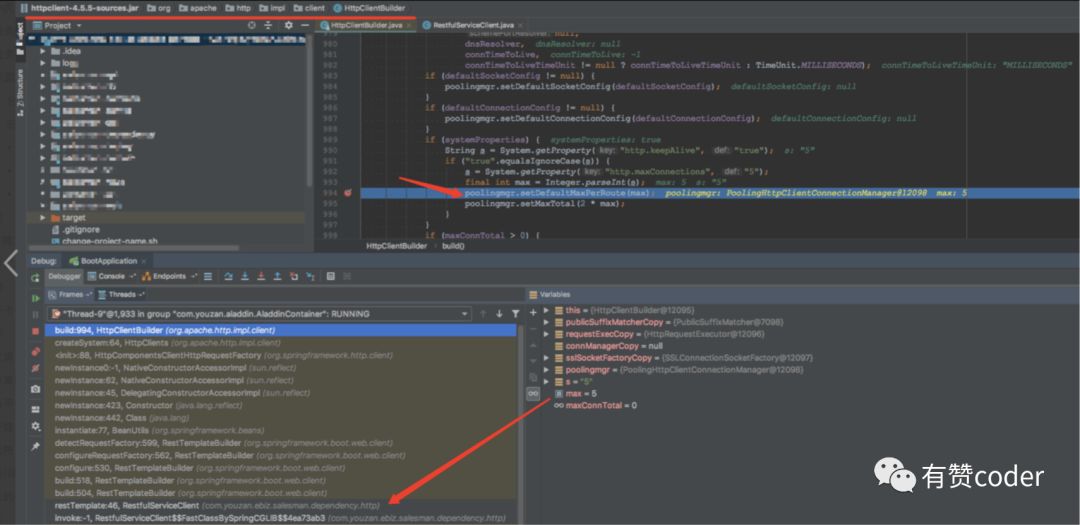
这个工具类默认使用了队列去发起 http 请求,形成了类似 pool 的方式,并且 pool active size 仅有 5。
现在我们来还原下整个案件的经过:
500 个并发的请求同时访问了我们应用的某个接口,将 dubbo 线程池迅速占满(dubbo 线程池大小为 200),这个接口内部逻辑需要访问一个内网的 http 接口
由于某些不可抗拒因素(运维同学还在辛苦奋战),这个时间段内这个内网的 http 接口全部返回超时
这个接口发起 http 请求时,使用队列形成了类似 pool 的方式,并且 pool active size 仅有 5,所以消耗完 500 个请求大约需要 500/5*2s=200s,这 200s 内应用本身承担着大约 3000QPS 的请求,会有大约 3000*200=600000 个任务会进入 dubbo 线程池队列(如悬案中的日志截图)。PS:整个应用当然就凉凉咯。
消耗完这 500 个请求后,应用就开始慢慢恢复(恢复的速率与时间可以根据正常 rt 大致算一算,这里就不作展开了)。
四、思考
到这里,大家心里的一块石头已经落地。但回顾整个案件,无非就是我们工作中或者面试中,经常碰到或被问到的一个问题:“对象池是怎么用的呢?线程池是怎么用的呢?队列又是怎么用的呢?它们的核心参数是怎么设置的呢?”。答案是没有标准答案,核心参数的设置,一定需要根据场景来。拿本案举例,本案涉及两个方面:
4.1 发起 http 请求的队列
这个使用队列形成的 pool 的场景是侧重 IO 的操作,IO 操作的一个特性是需要有较长的等待时间,那我们就可以为了提高吞吐量,而适当的调大 pool active size(反正大家就一起等等咯),这和线程池的的 maximum pool size 有着异曲同工之处。那调大至多少合适呢?可以根据这个接口调用情况,平均 QPS 是多少,峰值 QPS 是多少,rt 是多少等等元素,来调出一个合适的值,这一定是一个过程,而不是一次性决定的。那又有同学会问了,我是一个新接口,我不知道历史数据怎么办呢?对于这种情况,如果条件允许的话,使用压测是一个不错的办法。根据改变压测条件,来调试出一个相对靠谱的值,上线后对其观察,再决定是否需要调整。
4.2 dubbo 线程池
在本案中,对于这个线程池的问题有两个,队列长度与拒绝策略。队列长度的问题显而易见,一个应用的负载能力,是可以通过各种手段衡量出来的。就像我们去餐厅吃饭一样,顾客从上桌到下桌的平均时间(rt)是已知的,餐厅一天存储的食物也是已知的(机器资源)。当餐桌满了的时候,新来的客人需要排队,如果不限制队列的长度,一个餐厅外面排上个几万人,队列末尾的老哥好不容易轮到了他,但他已经饿死了或者餐厅已经没吃的了。这个时候,我们就需要学会拒绝。可以告诉新来的客人,你们今天晚上是排不上的,去别家吧。也可以把那些吃完了,但是赖在餐桌上聊天的客人赶赶走(虽然现实中这么挺不礼貌,但也是一些自助餐限时2小时的原因)。回到本案,如果我们调低了队列的长度,增加了适当的拒绝策略,并且可以把长时间排队的任务移除掉(这么做有一定风险),可以一定程度的提高系统恢复的速度。
最后补一句,我们在使用一些第三方工具包的时候(就算它是 spring 的),需要了解其大致的实现,避免因参数设置不全,带来意外的“收获”。
总结了这么多,小虎和小峰同学,终于心满意足的走向了自助餐厅,开始享用他们的晚餐。
热门推荐
回复 [优惠券],领取极客时间最优惠的优惠券
回复 java 或 666 ,领取 Spring 等最新教程
回复 webflux 或 888,领取《Spring Boot 2 WebFlux 教程》
最新整理:回复 [获取资源], 领取》
长按二维码,扫扫关注哦
✬关注即可得 Spring Boot Cloud、微服务等干货✬
如果文章对你有帮助的话
转发一下是最好的在看 ❤️
以上是关于如何正确的使用线程池,避免线上故障?的主要内容,如果未能解决你的问题,请参考以下文章