JDK 线程池源码实现解析
Posted 艾编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK 线程池源码实现解析相关的知识,希望对你有一定的参考价值。
JDK作为Java开发的核心,“线程池”顾名思义,就是存放线程的池子,这个池子可以存放多少线程取决于采用哪种线程池,取决于有多少并发线程,有多少计算机的硬件资源。使用线程池最直接的好处就是:线程可以重复利用、减少创建和销毁线程所带来的系统资源的开销,提升性能(节省线程创建的时间开销,使程序响应更快)。那么今天就给大家带来一个核心的知识体系,JDK线程池系列课程,欢迎大家来一起学习!
1.JDK 线程池基本概念
进程-运行中的运用程序
线程-由进程创建,可被系统调度和分派的基本单位
. 轻量级的进程
. 一个进程可拥有多个线程
.状态:新建,就绪,运行,阻塞,死亡
2.线程池的优势
背景:线程是一个重量级的对象,应该避免频繁创建和销毁。
.复用线程,降低线程创建和销毁造成的系统资源浪费和性能损耗
.提高系统响应速度
.方便管控线程
.支持定时任务
如果没有jdk自带线程池,该如何设计?目前业界普遍采用的是生产者-消费者模式,
为说明线程池工作原理,简化代码的示例如下:
class MyThreadPool{//利用阻塞队列实现生产者-消费者模式BlockingQueue<Runnable> workQueue;//保存内部工作线程List<WorkerThread> threads = new ArrayList<>();// 构造方法MyThreadPool(int poolSize, BlockingQueue<Runnable> workQueue) {this.workQueue = workQueue;// 创建工作线程for(int idx=0; idx<poolSize; idx++){WorkerThread work = new WorkerThread();work.start();threads.add(work);}}// 提交任务void execute(Runnable command){workQueue.put(command);}// 工作线程负责消费任务,并执行任务class WorkerThread extends Thread{public void run() {//循环取任务并执行while(true){Runnable task = workQueue.take();task.run();}}}}/** 下面是使用示例 **/// 创建有界阻塞队列BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(2);// 创建线程池MyThreadPool pool = new MyThreadPool(10, workQueue);// 提交任务pool.execute(()->{System.out.println("hello");});
3.JDK1.8线程池类型
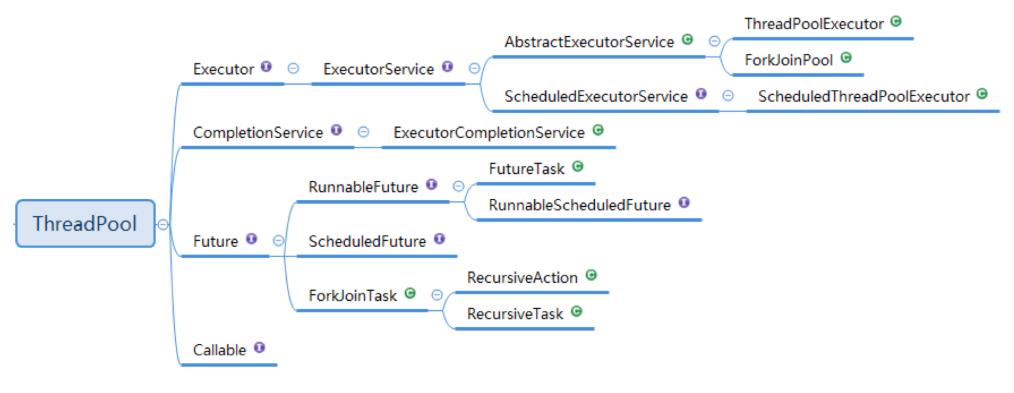
4.ThreadPoolExecutor
背景:jdk提供了静态工程类Executors来创建线程池,但是目前大厂基本都不建议使用,原因在于默认的线程池使用的是无界的BlockingQueue,容易导致OOM(Out Of Memory)
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {}
| corePoolSize | 核心线程数 |
|---|---|
| corePoolSize | 核心线程数 |
| maximumPoolSize | 允许创建的最大线程数 |
| keepAliveTime | 当线程总数>corePoolSize,空闲线程的最长等待时间 |
| workQueue | 阻塞队列,当线程数达到corePoolSize,会尝试往workQueue堆放 |
| threadFactory | 新建线程的工厂类 |
| Handler | 线程数达到maximumPoolSize的拒绝策略 |
5.工作原理示意图
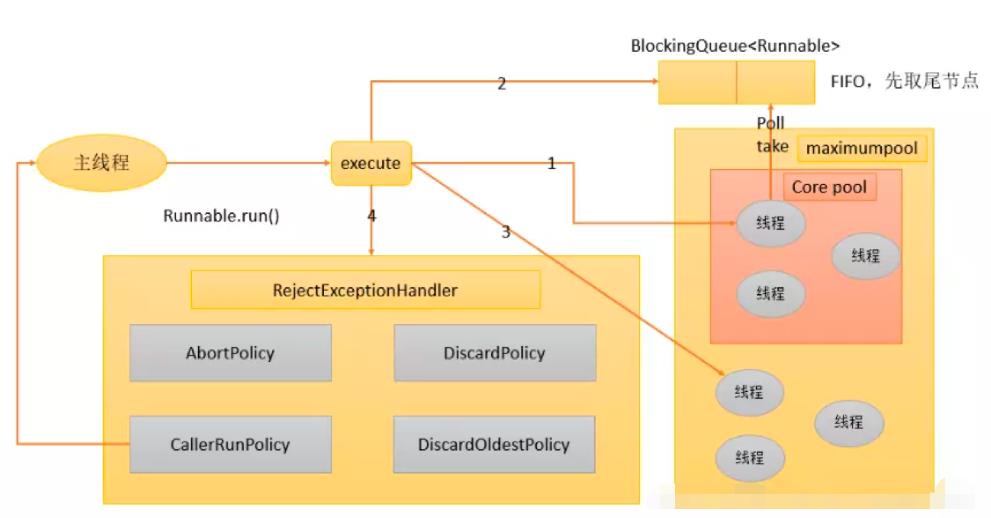
1 线程数<corePoolSize, 直接创建线程执行
2 线程数>=corePoolSize, 加到阻塞队列
3 阻塞队列满,且线程数<maximumPoolSize,创建新线程
4 线程数>=maximumPoolSize,执行拒绝策略
6.关键执行步骤
6.1 添加执行任务
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();/*** 线程数少于corePoolSize, 直接新建*/if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}/*** 线程数>=corePoolSize,尝试加入阻塞队列*/if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}/*** 阻塞队列满, 尝试新建非核心线程,失败(线程数已达最大线程数)则执行拒绝策略*/else if (!addWorker(command, false))reject(command);}
6.2 将任务包装成Worker类并启动
private boolean addWorker(Runnable firstTask, boolean core) {...Worker w = null;try {/** 包装成Worker */w = new Worker(firstTask);/** Thread t 是任务所绑定的系统线程 */final Thread t = w.thread;if (t != null) {/** 对任务添加前需加锁 */final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive())throw new IllegalThreadStateException();workers.add(w);int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {/** 启动任务 */t.start();workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w);}...}
6.3 执行任务内容
/** Worker类实现了Runnable接口, 具体执行的方法体 */final void runWorker(Worker w) {/** 当前线程wt: w所绑定的线程 */Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {while (task != null || (task = getTask()) != null) {w.lock();// 检查线程池状态,如果关闭,则中断wtif ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task);Throwable thrown = null;try {/** 任务具体的执行内容 */task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {afterExecute(task, thrown);}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}}
6.4 获取执行结果
ThreadPoolExecutor提供了3个submit()方法和1个FutureTask工具类来支持获得任务执行结果的需求。
// 提交Runnable任务Future submit(Runnable task);// 提交Callable任务Future submit(Callable task);// 提交Runnable任务及结果引用Future submit(Runnable task, T result);
以上3个submit方法共同的返回值都是Future接口:
// 取消任务booleancancel(boolean mayInterruptIfRunning);// 判断任务是否已取消boolean isCancelled();// 判断任务是否已结束boolean isDone();// 获得任务执行结果V get();// 获得任务执行结果,支持超时V get(long timeout, TimeUnit unit);
get(timeout, unit) 支持超时机制,get()则是会阻塞线程,知道任务执行完成才会被唤醒。另外,我们也可以使用jdk提供的FutreTask工具类来投入ThreadPoolExecutor执行并获取结果(FutureTask实现了Runnable和Future接口):
/ 创建FutureTaskFutureTaskfutureTask = new FutureTask<>(()-> 1+2);// 创建线程池ExecutorService es = Executors.newCachedThreadPool();// 提交FutureTaskes.submit(futureTask);// 获取计算结果Integer result = futureTask.get();
6.5 示例
线程池是并发编程的常用工具,并发编程有3个核心问题:分工、同步和互斥。分工是第一步,分工合理高效之后才能投入线程池执行。举个例子,对于做饭程序,可分解成以下所示:
T1 洗电饭锅,洗米,烧饭,吃饭
T2 洗炒锅,洗菜,切肉,炒菜
其中,T1的吃饭这道工序需要等待T2完成炒菜工序。对于T1这个等待动作,你能想到Thread.join()、CountDownLatch,或者阻塞队列都能解决,这里我们使用Future的特性来实现。
import java.util.concurrent.Callable;import java.util.concurrent.FutureTask;import java.util.concurrent.TimeUnit;public class ThreadPoolCooking {// T1Task需要执行的任务:// 洗电饭锅,洗米,烧饭,吃饭static class T1Task implements Callable {FutureTask ft2;// T1任务需要T2任务的FutureTaskT1Task(FutureTask<String> ft2) {this.ft2 = ft2;}public String call() throws Exception {System.out.println("T1:洗电饭锅...");TimeUnit.SECONDS.sleep(1);System.out.println("T1:洗米...");TimeUnit.SECONDS.sleep(1);System.out.println("T1:烧饭...");TimeUnit.SECONDS.sleep(20);// 获取T2线程的炒菜String tf = (String)ft2.get();System.out.println("T1:获取炒菜:" + tf);System.out.println("T1:吃饭...");return "吃饭:" + tf;}}// T2Task需要执行的任务:// 洗炒锅,洗菜,切肉,炒菜static class T2Task implements Callable<String> {public String call() throws Exception {System.out.println("T2:洗炒锅...");TimeUnit.SECONDS.sleep(2);System.out.println("T2:洗菜...");TimeUnit.SECONDS.sleep(3);System.out.println("T2:切肉...");TimeUnit.SECONDS.sleep(5);System.out.println("T2:炒菜...");TimeUnit.SECONDS.sleep(10);return "青椒炒肉丝";}}public static void main(String[] args) throws Exception {// 创建任务T2的FutureTaskFutureTask ft2 = new FutureTask<String>(new T2Task());// 创建任务T1的FutureTaskFutureTask ft1 = new FutureTask<String>(new T1Task(ft2));// 线程T1执行任务ft1Thread T1 = new Thread(ft1);T1.start();// 线程T2执行任务ft2Thread T2 = new Thread(ft2);T2.start();// 等待线程T1执行结果System.out.println(ft1.get());}}
执行结果:
T1:洗电饭锅...
T2:洗炒锅...
T1:洗米...
T2:洗菜...
T1:烧饭...
T2:切肉...
T2:炒菜...
T1:获取炒菜:青椒炒肉丝
T1:吃饭...吃饭:青椒炒肉丝
7.ForkJoinPool简介
. ForkJoinPool是Executor的一个「补充」,而不是「替代品」
.特别适合用于“分而治之”,递归计算的场景
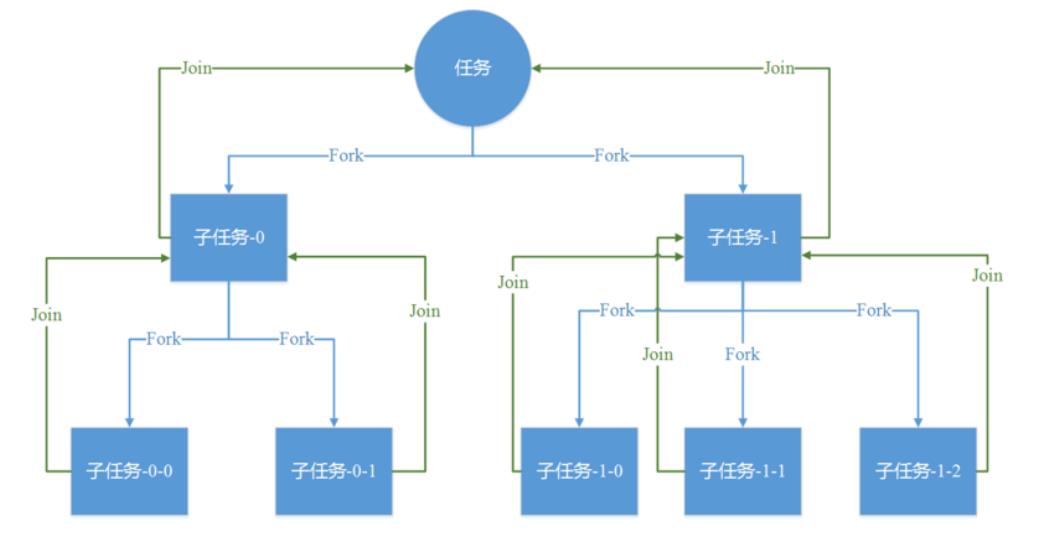
7-1.和ThreadPoolExecutor的对比

补充点:对于可分解成类似的子任务的大任务,「分治」是一种有效的解决方式。例如:归并排序、Map/Reduce。
分治步骤如下:
. 任务分解
. 结果合并
示例:1+2+...+100
import java.util.concurrent.ForkJoinPool;import java.util.concurrent.RecursiveTask;public class ForkJoinCalculate {public static void main(String[] args) {ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors());System.out.println(forkJoinPool.invoke(new N(1, 100)));}static class N extends RecursiveTask<Integer> {final int start, end;N(int start, int end) {this.start = start;this.end = end;}protected Integer compute() {if (start == end) {return start;}int m = (start + end) / 2;N n1 = null;if (m+1 <= end) {n1 = new N(m + 1, end);n1.fork();}N n2 = new N(start, m);return n2.compute() + (n1 == null ? 0 : n1.join());}}}
7-2.ForkJoinWorkerThread的work-stealing机制
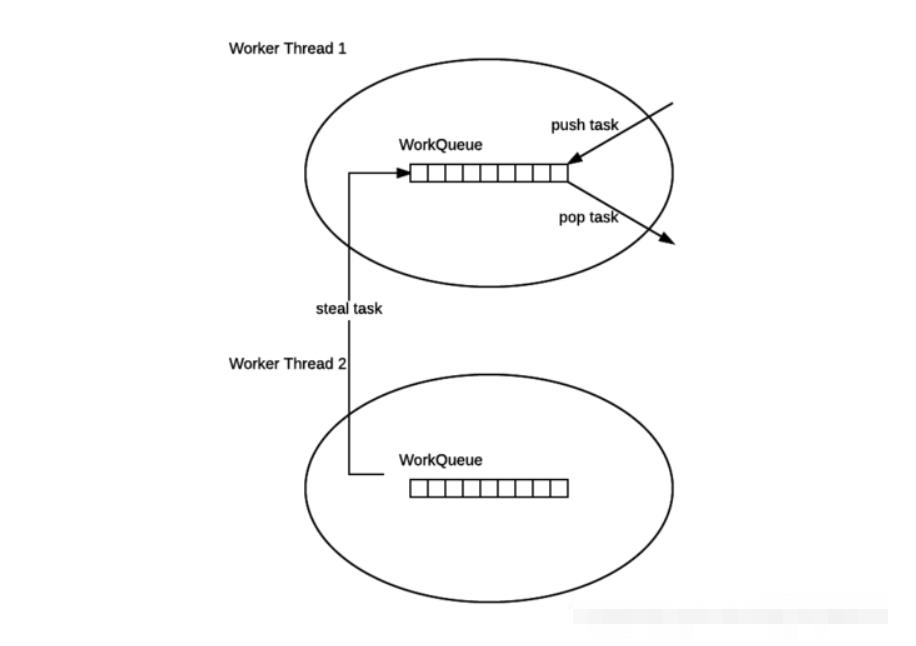
提示:如果所有并行任务都是CPU密集型的,可以使用ForkJoinPool,但如果存在IO密集型的并行任务,很可能因为一个很慢的IO计算而拖慢整个系统性能。
关于ForkJoinPool的实现细节,可以参考Doug Lea的论文 http://gee.cs.oswego.edu/dl/papers/fj.pdf
8.CompletionService(JDK1.8)
8.1 接口定义
public interface CompletionService<V> {Future submit(Callable task);Future submit(Runnable task, V result);/** 阻塞方式获取计算结果 */Future take() throws InterruptedException;/** 非阻塞方式获取计算结果 */Future poll();/** 添加了超时机制的poll */Future poll(long timeout, TimeUnit unit) throws InterruptedException;}
. ExecutorService 继承自 Executor,CompletionService是一个独立接口
. CompletionService可看做是Executor + BlockingQueue,任务运行在Executor,结果获取在BlockingQueue
. CompletionService的BlockingQueue可按照任务执行完成顺序获取先执行完成的结果,ExecutorService可能会 阻塞在个别任务执行结果的获取(Future.get())。
// ExecutorCompletionService实现类public class ExecutorCompletionService<V> implements CompletionService<V> {private final Executor executor;private final AbstractExecutorService aes;private final BlockingQueue<Future<V>> completionQueue;...// 构造函数1public ExecutorCompletionService(Executor executor) {...}/** 构造函数2* 如果不指定 completionQueue,那么默认会使用无界的 LinkedBlockingQueue。* 任务执行结果的 Future 对象就是加入到 completionQueue 中。*/public ExecutorCompletionService(Executor executor,BlockingQueue<Future<V>> completionQueue) {...}}
8.2 ExecutorService例子:10张图片的下载任务。
// 创建线程池ExecutorService executor = Executors.newFixedThreadPool(8);// 创建CompletionServiceCompletionService cs = new ExecutorCompletionService<>(executor);// 用于保存Future对象List<Future<Integer>> futures = new ArrayList<>(10);//提交异步任务,并保存future到futuresfor (int i = 0; i < remain; ++i) {futures.add( cs.submit(()->downloadImage(i)));}// 累计剩下的Integer remain = 10;try { // 对于返回结果的任务,立即处理,无需等待所有的都完成for (int i = 0; i < remain; ++i) {int res = cs.poll();//简单地通过判空来检查是否成功返回if (res != null) {remain--;// 处理成功的返回,省略。}} finally {//取消所有任务for(Future f : futures) f.cancel(true);}// 返回结果return r;
9.线程池案例
9.1 mysql连接池
9.2 Netty线程模型
9.3 Guava 限流器
10.其他并发模型
10.1 MySQL并发控制方案MVCC
10.2 协程:更轻量的线程
今天给大家整理了一个系列的教程Java架构师系列的教程,包含了系统架构、Java相关、编码规范、消息队列、Maven、nginx、Redis、MySQL、TomCat相关、Git等系列的电子书,回复关键词就可以下载哦
同时还有精彩教程就、更多视频+代码资料文档等你挖掘
回复关键词
Redis 分布式限流 消息队列 alibaba JVM性能调优
看更多精彩教程
喜欢本文,记得点击个在看,或者分享给朋友哦!
以上是关于JDK 线程池源码实现解析的主要内容,如果未能解决你的问题,请参考以下文章