线程池的探索(下)
Posted 大数据Kafka技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池的探索(下)相关的知识,希望对你有一定的参考价值。
第二章 JDK源码剖析-并发篇
第 33 节
ThreadPool(下)
上一节,带大家简单回顾了下线程池的类型和常用参数。由于不同线程池模型实现原理不同,这里带大家研究下ThreadPoolExecutor这个线程池模型的底层源码原理。相信当你掌握这种模型的原理,关于ForkJoinPool和自定义的模型比如Netty的EventLoop模型就可以自己去研究了。
简单摸一下ThreadPoolExecutor的脉络
还是先用分析JDK源码的利器-脉络法,简单看下ThreadPoolExecutor的源码脉络。如下图所示:
方法可以先不看,主要看下成员变量,能认识或者猜出的大概意思的变量,我用红线框出来了。
主要有corePoolSize、maximumPoolSize、keepAliveTime 拒绝策略等和之前7个参数是对应的。核心存储目前看到的是一个HashSet和BlockingQueue.Worker应该是指的Runnable定义的线程任务。
所以你可以得到如下核心组件图:
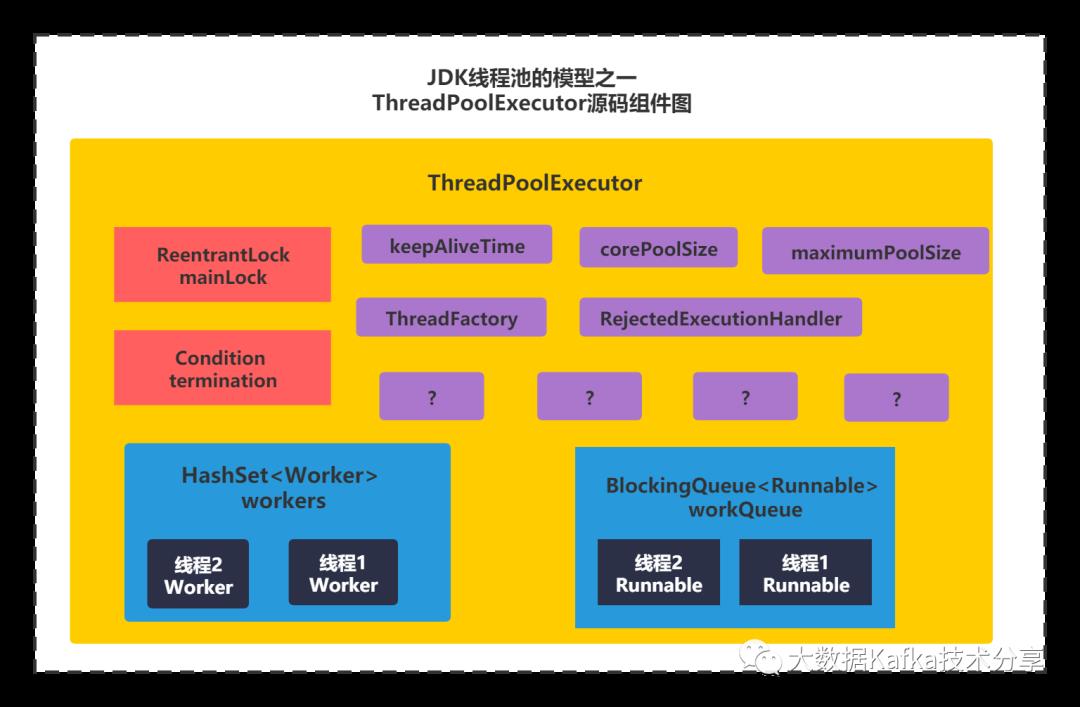
还有些属性看不出来是干什么的,一会会给大家解释的。
ThreadPoolExecutor的创建
还记得上一节创建线程池的例子么?
ExecutorService pool = new ThreadPoolExecutor(
5, //corePoolSize
200, //maximumPoolSize
0L, //keepAliveTime 线程空闲时多长时间被杀死D
TimeUnit.MILLISECONDS, //unit
new LinkedBlockingQueue<Runnable>(1024), //workQueue等待队列
new ThreadFactory() {
@Override
public Thread newThread(Runnable runnable) {
Thread thread = new Thread(runnable);
thread.setName("Hello-ThreadPool");
thread.setDaemon(true);
return thread;
}
}, //threadFactory 自定义线程工厂,如何创建工厂
new ThreadPoolExecutor.AbortPolicy()); //线程池策略
当new一个ThreadPoolExecutor发生了什么?
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
除了一些校验外,其实就是将七个参数保存在ThreadPoolExecutor的属性中,没有什么其他核心逻辑。
ThreadPoolExecutor核心提交线程任务的执行流程
接着我们看下核心的提交任务的源码原理:
pool.execute(()-> System.out.println(Thread.currentThread().getName()));
这一行做了什么呢?
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
这个方法的脉络很清晰:
1)如果小于核心线程数,就是创建一个workeraddWorker(command, true) (true来控制使用coresize)
2)否则Runnable任务pffer进入队列workQueue.offer(command)
3)如果入队失败了,直接创建一个worker,addWorker(command, false) (false来控制使用maxcoresize)
基本上就可以得到如下流程图:
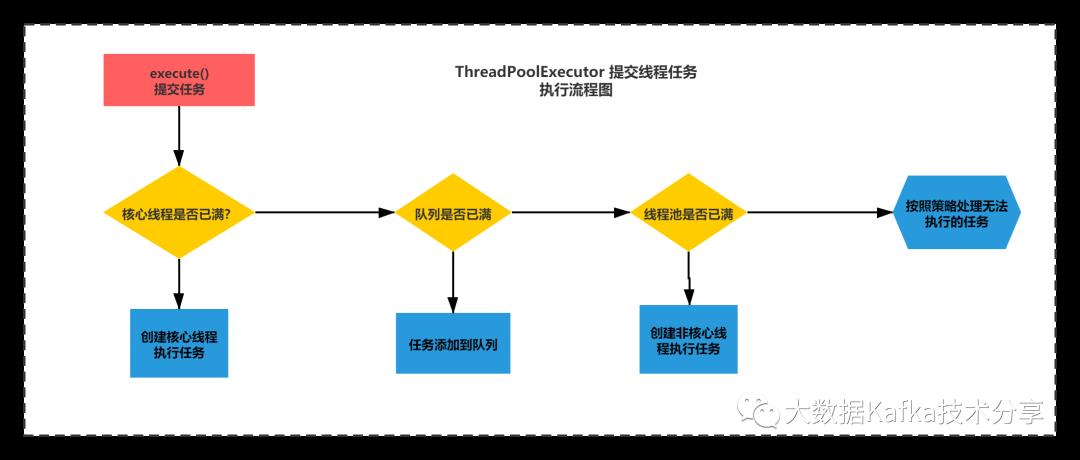
彻底了解ThreadPoolExecutor的底层原理
了解了执行的脉络,接着我们来看下细节。由于线程池的实现重点不是很突出,细节中很多是为了各种场景考虑的。这里直接给大家理出来主要的2个关键点。
1、AtomicInteger`ctl`变量,高3位表示线程池状态,低29位表示worker数量。
线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP< TIDYING < TERMINATED 分别有对应的数字对应。和一些操作状态的方法。当然也有一些操作个数的方法。比如workerCountOf是计数,类似于 getCount,runStateOf类似于getState等。
2、Runnable任务实际被Worker执行,所有线程都会被封装成Worker放入HashSet中,(放入时加ReentrantLock)执行Runnable任务是通过Worker的runWorker方法,这个方法会直接运行Runnable任务,或者 getTask方法从队列获取一个任务,来执行。
首先来看第一个关键点的源码:
// 1. `ctl`,可以看做一个int类型的数字,高3位表示线程池状态,低29位表示worker数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 2. `COUNT_BITS`,`Integer.SIZE`为32,所以`COUNT_BITS`为29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 3. `CAPACITY`,线程池允许的最大线程数。1左移29位,然后减1,即为 2^29 - 1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// 4. 线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0
private static int workerCountOf(int c) { return c & CAPACITY; }
// 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值
private static int ctlOf(int rs, int wc) { return rs | wc; }
// 8. `runStateLessThan()`,线程池状态小于xx
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
// 9. `runStateAtLeast()`,线程池状态大于等于xx
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
之后你会看到大量的对状态或者ctl个数,这2个变量的操作。机会是每执行几句代码,就会判断下,这里我们不是精度源码,没必要弄懂每一行。所以抓大放下,跳过这些无用的细节。
这里你重点知道状态和线程个数通过高3位和低29位的AtomicInteger维护这个才是核心。如下图:

接着我们来看下第二个关键点:
Runnable任务实际被Worker执行,所有线程都会被封装成Worker放入HashSet中,(放入时加ReentrantLock)执行Runnable任务是通过Worker的runWorker方法,这个方法会直接运行Runnable任务,或者 getTask方法从队列获取一个任务,来执行。
首先Worker是啥,怎么封装和运行Runnable任务的?
Worker其实本质就是对Runnable的封装,自身也是一个线程,通过运行自身线程来执行Runnable线程任务。自身也是一个AQS组件,可以通过lock操作一些资源,比如HashSet等。
整个Worker结构如下图所示:
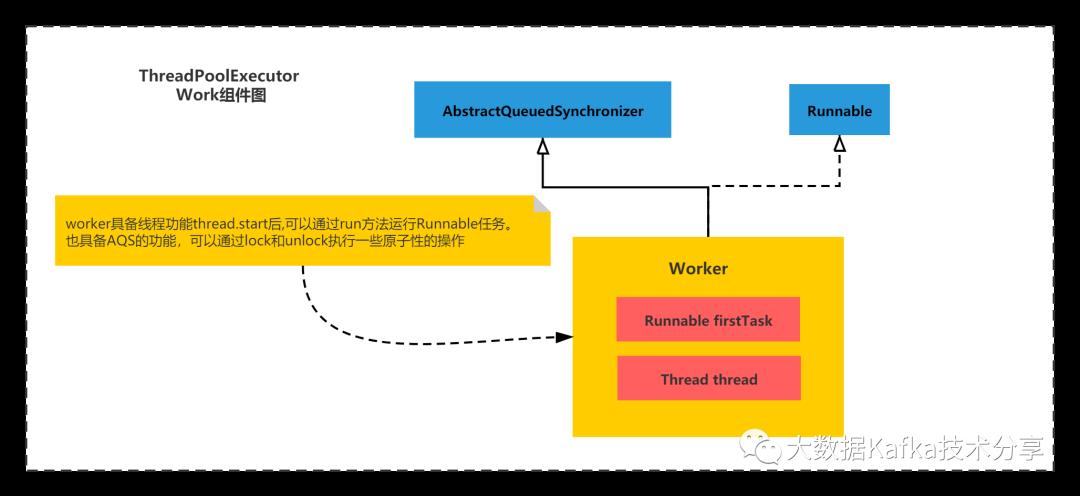
创建Worker运行核心的源码如下:
private boolean addWorker(Runnable firstTask, boolean core) {
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
//省略无关代码(一堆对状态和个数的判断处理)
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// worker的添加必须是串行的,因此需要加锁
mainLock.lock();
try {
//省略无关代码(一堆对状态和个数的判断处理)
workers.add(w);
//省略无关代码
} finally {
mainLock.unlock();
}
// 启动worker线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
知道了Worker如何封装Runnable,接下来看下它是如何运行Runnbale任务的呢?
其实和之前的流程图有关系的。按照之前的流程,创建了Worker可能被放入队列或者直接执行。
到底是怎么做到的呢?先来看如下图:
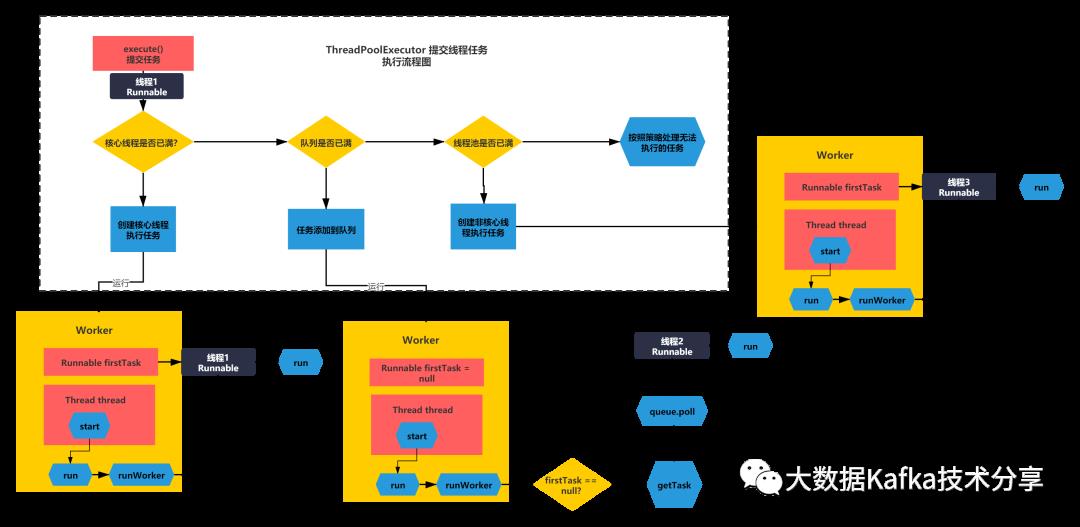
核心脉络基本就是:
1)执行逻辑1:core和非core线程会直接运行一个Worker执行Runnable
2)执行逻辑2:从队列中获取Runnable任务执行。(之前如果运行的线程达到coresize,会进入队列)、
直接运行的源码逻辑如下:
如果task=null,说明不是直接运行,运行任务则是通过一个getTask方法从队列获取数据的。
至于线程池的关闭,shutdown实际是根据线程池状态,不会在提交新的线程,等待原来线程运行结束,线程池就释放资源了。这块就不带大家研究了,有兴趣的可以自己下去研究下。
小结
ThreadPoolExecutor其实逻辑并不复杂。只是代码写了很多其他逻辑,所以要抓大放小,找核心源码逻辑来理解就好了。
简单小结下今天ThreadPoolExecutor的原理:
1)线程内部通过一个AtomicInteger ctl变量,高3为表示状态,其余29位表示线程个数统计。
2)提交线程任务的流程,核心就是从core到队列再到非core的执行过程。(通过七大参数可以配置第一步或者第二步可以省略,直接通过第三步创建线程,比如CachedThreadPool。注意这里只是通用的执行顺序,不同线程池可以实现不同的控制。)
3)提交的线程任务通过HashSet记录所有任务,通过Queue可以缓存等待的任务。
4)使用了Worker封装了Runnable的执行逻辑,可以很方便的通过队列、提交时task是否为空,coresize、keepAliveTime等参数灵活的控制线程的执行。
好了,今天的文章就到这里,之后的一节会总结之前JDK集合篇和并发篇的所有核心知识。会以Xmind思维导图的方式展现。
以上是关于线程池的探索(下)的主要内容,如果未能解决你的问题,请参考以下文章