图文详解Hadoop集群搭建(CentOs6.3)
Posted 程序员技术前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解Hadoop集群搭建(CentOs6.3)相关的知识,希望对你有一定的参考价值。
阅读目录
前期准备
开始安装
总结
问题解决
集群中各个端口
本文主要详细地描述了hadoop集群的搭建以及一些配置文件的说明,用于自己复习以及供新人学习,若有错误之处还请指出。
回到顶部
前期准备
先给出我的集群架构:
到hadoop官网下载好hadoop安装包http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
装好四台虚拟机(我的四台虚拟机是CentOs6.3系统)
四台虚拟机都装好jdk
四台虚拟机都配好免密登录
vim /etc/hosts
192.168.25.13 mini1192.168.25.14 mini2192.168.25.15 mini3192.168.25.16 mini4
以上步骤有不会的可查看我的其他几篇博客:
Linux下的常用配置
Linux下配置免密登录
回到顶部
开始安装
1、将hadoop安装包上传到mini1上,解压后改名,并创建目录hadoopdata与hadoop目录平行
tar -zxvf hadoop-2.6.5.tar.gz -C /root/apps/cd /root/apps/
mv hadoop-2.6.5 hadoopmkdir hadoopdata
2、进入hadoop配置文件目录下,可看到以下配置文件
cd hadoop/etc/hadoop/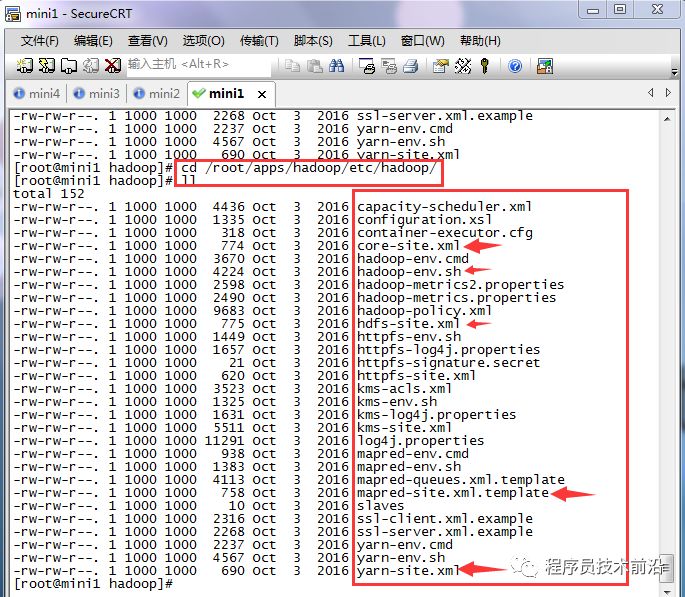
3、修改hadoop-env.sh配置文件
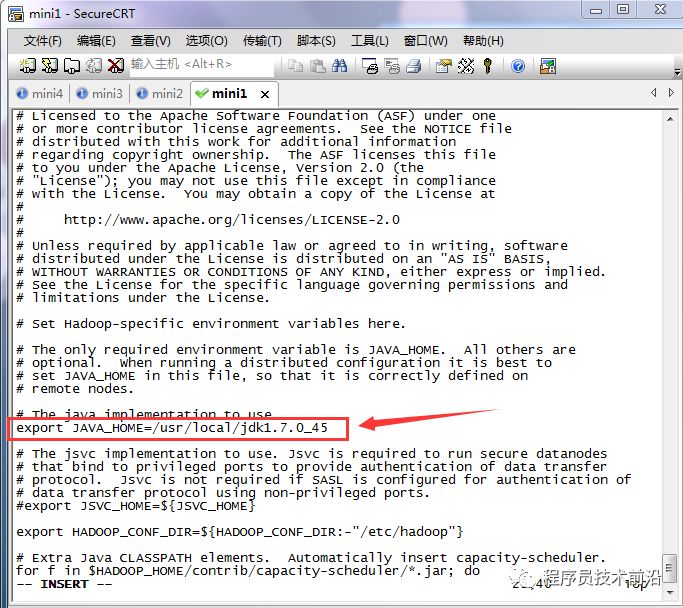
vim hadoop-env.sh#写上自己的JAVA_HOME4、修改core-site.xml配置文件
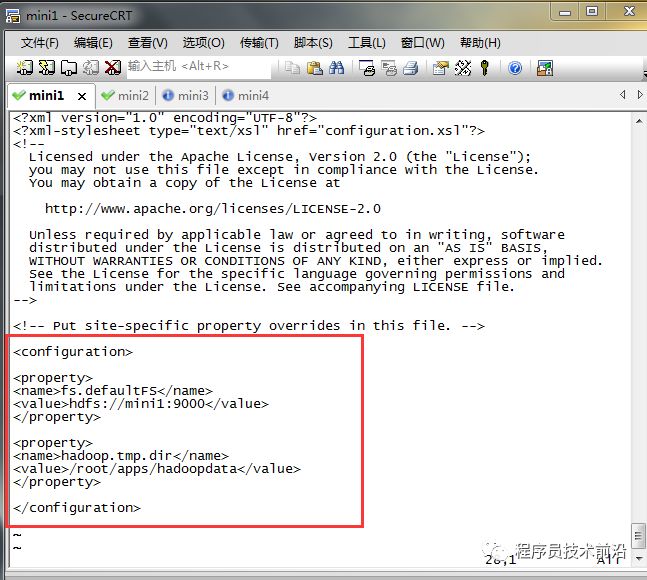
vim core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://mini1:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/apps/hadoopdata</value></property></configuration>配置说明:
fs.defaultFS:hadoop使用什么文件系统hdfs://mini1:9000:指定hadoop系统使用hdfs文件系统,并指明namenode为mini1,客户端访问端口为9000hadoop.tmp.dir:hadoop文件存储目录
有2个参数可配置,但一般来说我们不做修改。
fs.checkpoint.period表示多长时间记录一次hdfs的镜像,默认是1小时。
fs.checkpoint.size表示镜像文件快大小,默认64M。<property><name>fs.checkpoint.period</name><value>3600</value></property><property><name>fs.checkpoint.size</name><value>67108864</value></property>5、修改hdfs-site.xml(可不做任何配置,使用默认)
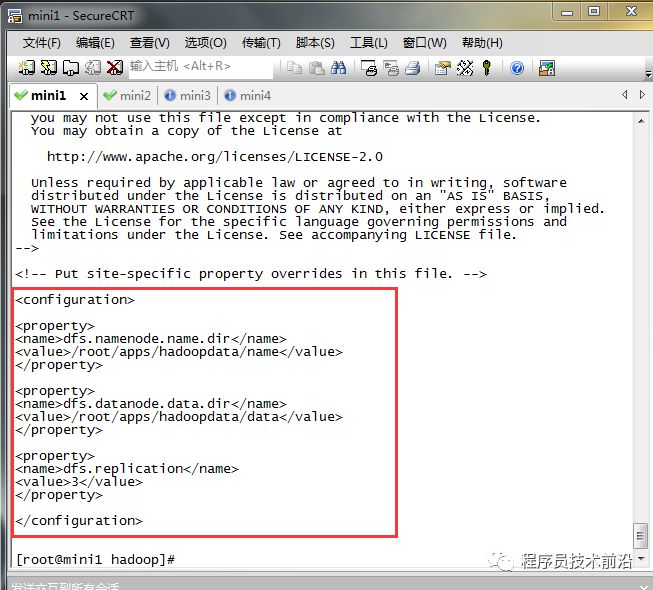
vim hdfs-site.xml<configuration><property><name>dfs.namenode.name.dir</name><value>/root/apps/hadoopdata/name</value></property><property><name>dfs.datanode.data.dir</name><value>/root/apps/hadoopdata/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>配置说明:
dfs.namenode.name.dir:namenode节点的数据存放目录dfs.datanode.data.dir:datanode节点的数据存放目录dfs.replication:集群中hdfs保存数据的副本数6、更改mapred-site.xml.template的配置文件名,并进行配置
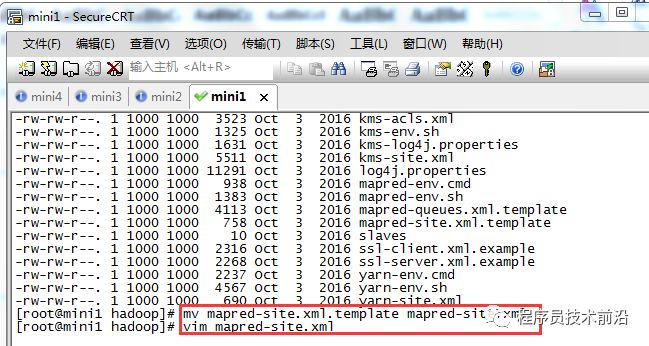
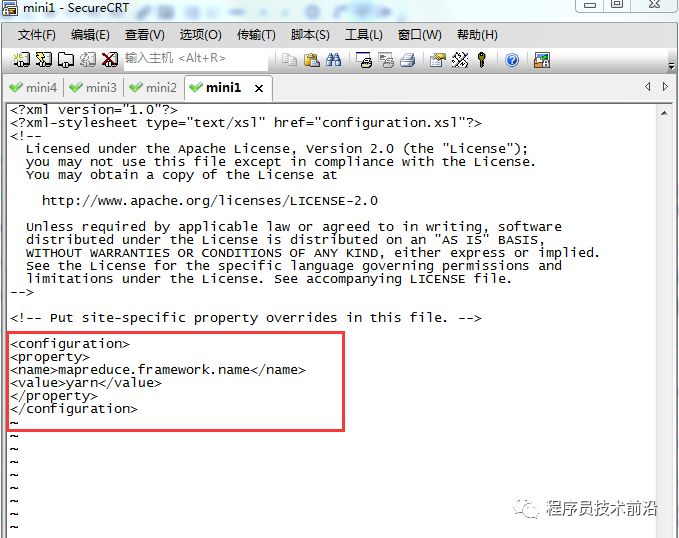
mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>配置说明:
mapreduce.framework.name:使用yarn运行mapreduce程序7、修改yarn-site.xml配置文件
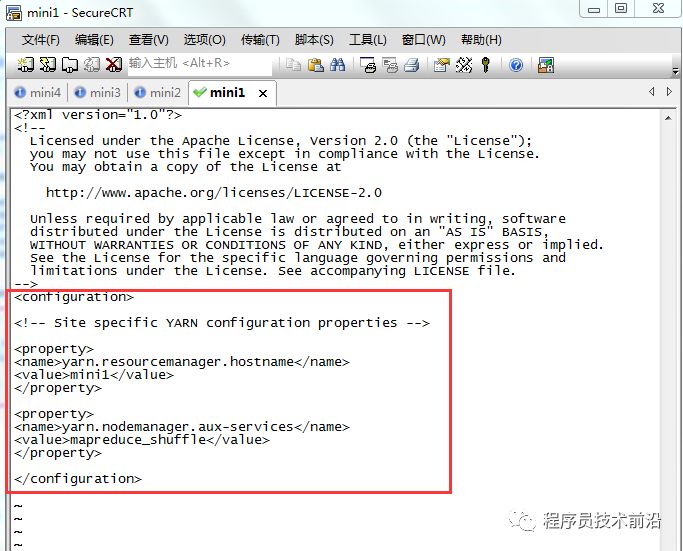
vim yarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>mini1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>配置说明:
yarn.resourcemanager.hostname:指定YARN的老大(ResourceManager)的地址yarn.nodemanager.aux-services:指定reducer获取数据的方式8、修改slaves文件
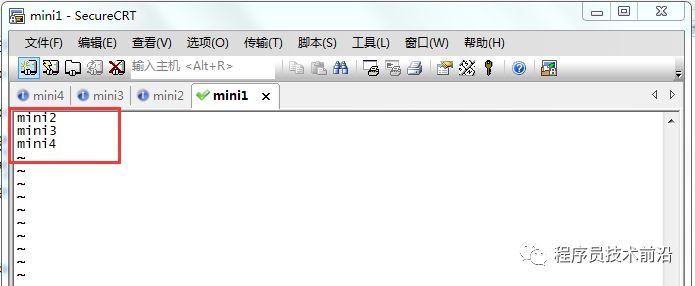
vim slaves# 在此文件下写入需要启动datanode和nodemanager的机器(往往datanode和nodemanager在一台机器上启动),一行代表一台机器。9、将hadoop添加到环境变量,并重新加载环境变量
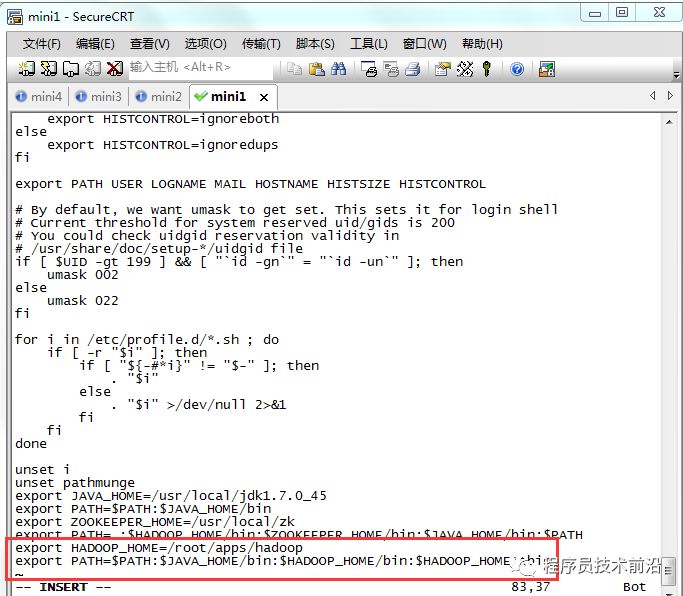
vim /etc/profileexport HADOOP_HOME=/itcast/hadoop-2.4.1export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile重要!重要!重要!!!
Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己对源码进行编译64位的版本。
自己编译比较麻烦,可以去网站:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下载对应的编译版本。
准备好64位的lib包后做以下操作:
#解压到已经安装好的hadoop安装目录的lib/native 和 lib目录下tar -zxvf hadoop-native-64-2.6.0.tar -C hadoop/lib/native
tar -zxvf hadoop-native-64-2.6.0.tar -C hadoop/lib#配置环境变量 vi /etc/profile
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" source /etc/profile#hadoop检测本地库hadoop checknative –a 10、将hadoop和配置文件分别分发给另外三台机器(mini2,mini3,mini4)
scp -r /root/apps/hadoop mini2:/root/apps/scp -r /root/apps/hadoop mini3:/root/apps/scp -r /root/apps/hadoop mini4:/root/apps/scp /etc/profile mini2:/etc/scp /etc/profile mini3:/etc/scp /etc/profile mini4:/etc/不要忘记三台机器都要重新加载一下配置文件
11、初始化HDFS
hadoop namenode -format12、批量启动/停止
#批量启动hdfsstart-dfs.sh#批量停止hdfsstop-dfs.sh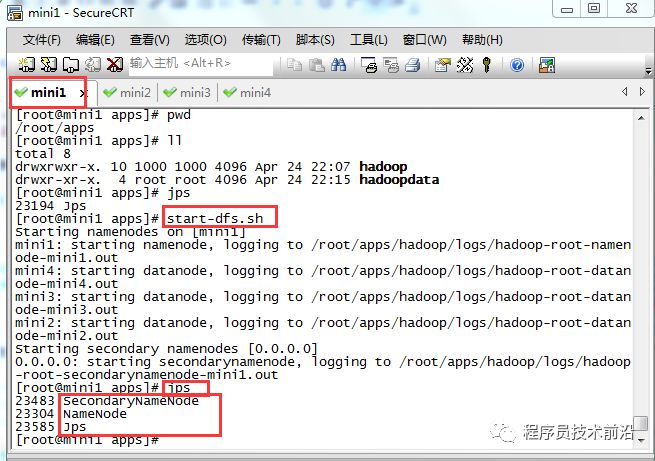
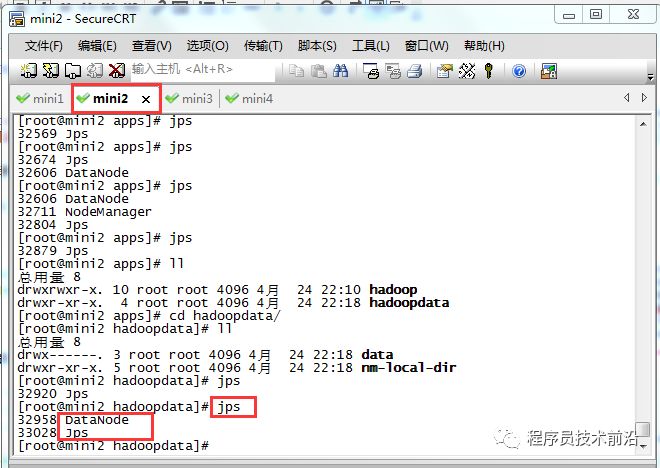
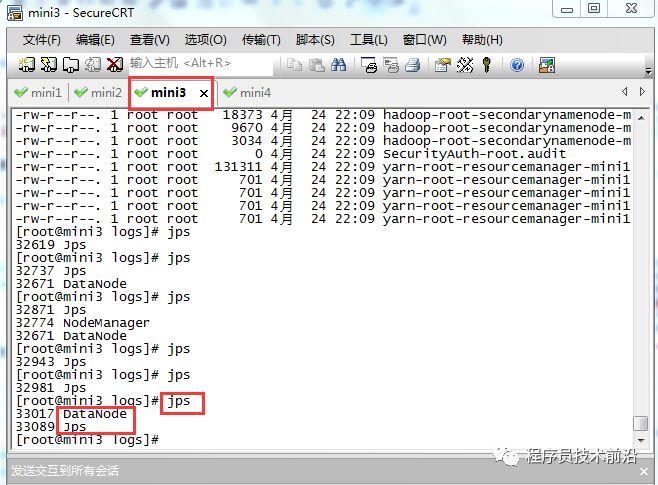
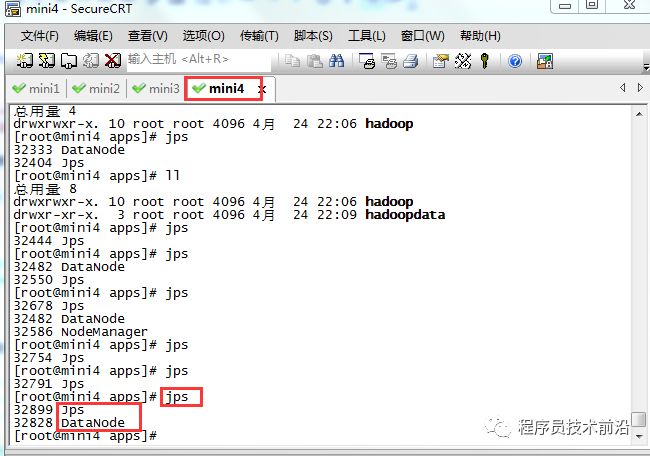
#批量启动yarnstrat-yarn.sh#批量停止yarnstop-yarn.sh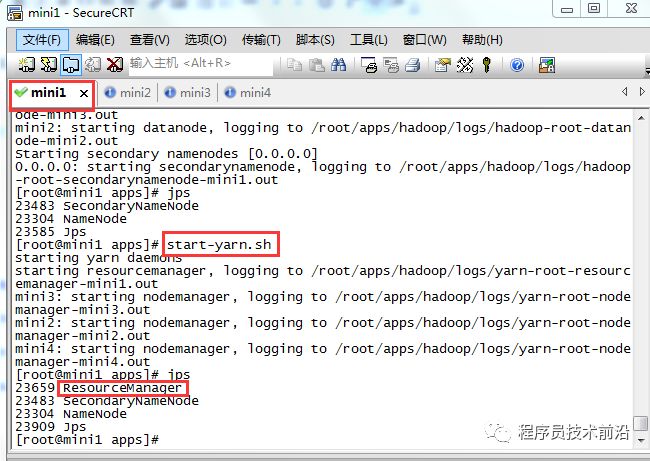
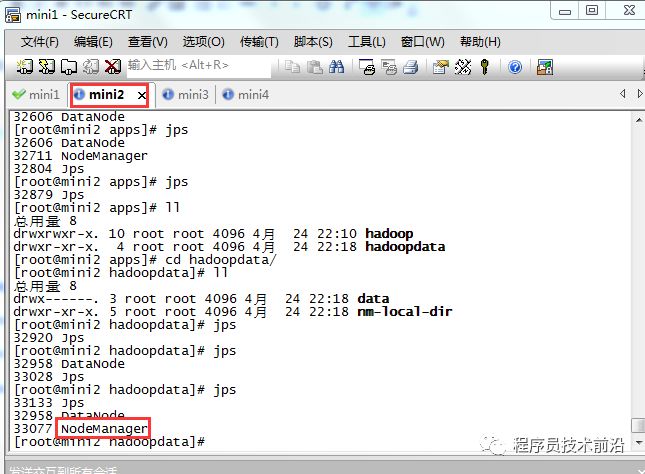
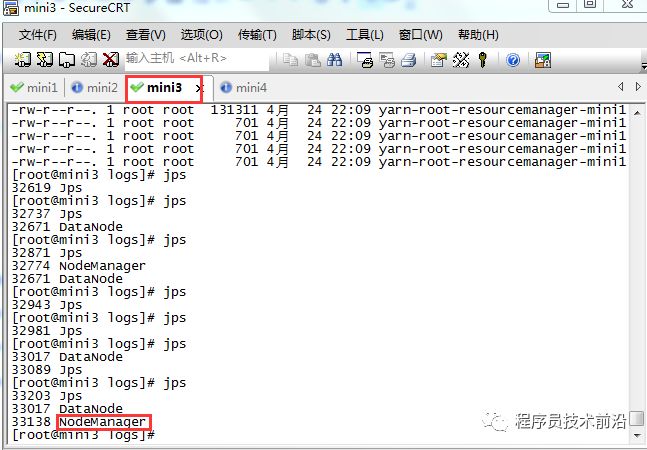
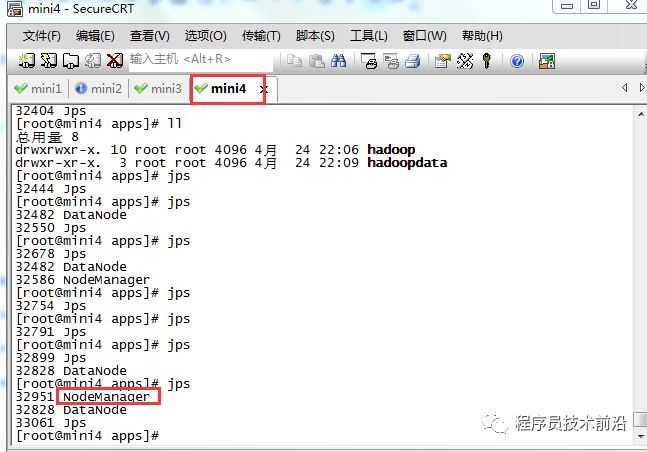
#单独启动或停止hdfs,yarnhadoop-daemon.sh start namenode hadoop-daemon.sh stop namenodehadoop-daemon.sh start datanode hadoop-daemon.sh stop datanodehadoop-daemon.sh start resourcemanager hadoop-daemon.sh stop resourcemanagerhadoop-daemon.sh start nodemanager hadoop-daemon.sh stop nodemanager回到顶部
总结
官网提供的版本本地库是32位的,在64位主机环境下无法执行。需要下载hadoop源码进行编译。
自己编译参考https://jingyan.baidu.com/article/ce436649fea8533772afd365.html
配置文件
hdfs-site.xml可不做任何配置,使用默认即可集群中每台机器都要记得修改
/etc/hosts文件集群中所有的机器配置环境变量后不要忘记source一下(因为本文的环境变量文件是通过scp命令传给各台机器的,很容易忘记source)
配置免密登录的时候不要忘记本机也配置上(将mini1的公钥发给mini1)(ssh-copy-id mini1)
如果哪台机器启动出错,可查看相应机器下的日志文件,根据错误信息百度查询解决方法(/root/apps/hadoop/logs/)(查看.log结尾的日志文件)
严格按照上述流程安装(包括目录创建以及目录的位置),可顺利完成集群的搭建
回到顶部
问题解决
datanode无法启动
原因:
初始化工作目录结构(hdfs namenode -format)只是初始化了namenode的工作目录,而datanode的工作目录是在datanode启动后自己初始化的。
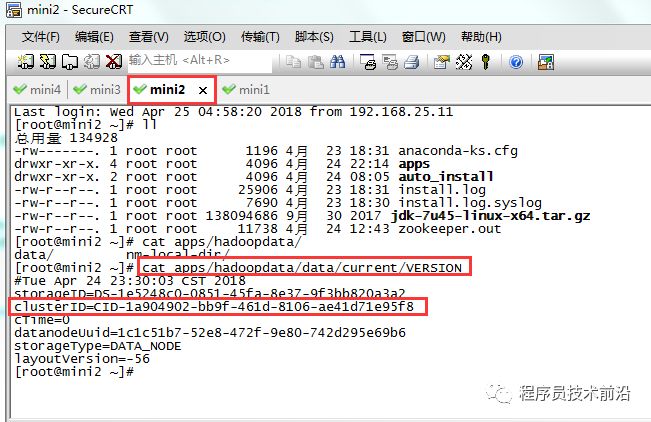
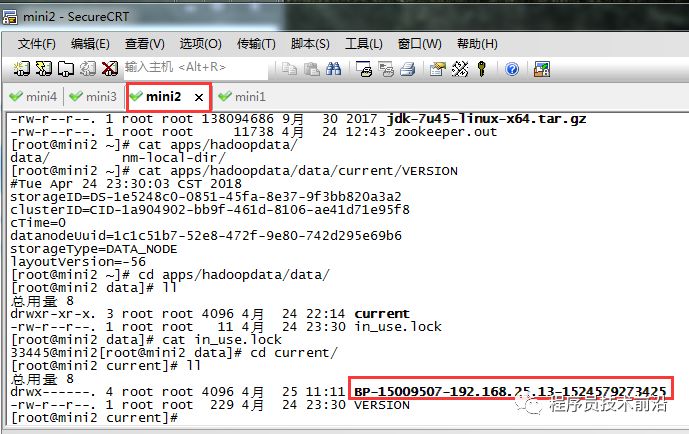
namenode在format初始化的时候会形成两个标识:
blockPoolId,
clusterId.
新的datanode加入时,会获取这两个标识作为自己工作目录中的标识。一旦namenode重新format后,namenode的身份标识已变,而datanode如果依然持有原来的id,就不会被namenode识别。解决方法:
将datanode机器上的工作目录删掉,重新启动datanode,它会重新创建工作目录,并获取namenode的标识。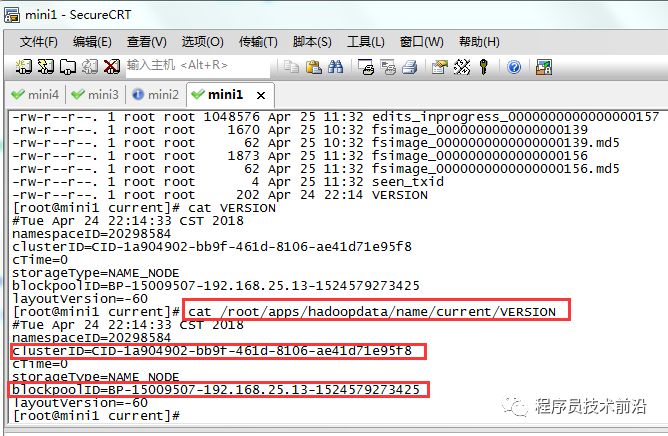
回到顶部
集群中各个端口
更多配置文件信息参考:https://blog.csdn.net/cuitaixiong/article/details/51591410
以上是关于图文详解Hadoop集群搭建(CentOs6.3)的主要内容,如果未能解决你的问题,请参考以下文章
大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
Hadoop入门(十四)——集群时间同步(图文详解步骤2021)