开源有坑,使用谨慎:缓存连接池开源组件剖析
Posted 唯品会质量工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源有坑,使用谨慎:缓存连接池开源组件剖析相关的知识,希望对你有一定的参考价值。
引言
某域在使用 Venus-cache时发现使用Connection模式(缓存并一直使用 Template中的连接)后,性能比直接使用Template模式有所上升。
对于两种模式的使用区别,示例如下:
1.Connection模式:
MemcachedTemplate.getConnectionFactory().getConnection().get(“key”,serializer)
2.Template模式:
MemcachedTemplate.get(“key”)
针对此问题进行了详细的性能测试,并对其中的问题进行了深入的分析。
测试调研
测试场景
由于目前生产上使用Venus-cache 的有些域已经上了云,所以同时在物理机和虚拟机环境下进行压测,以下为测试环境参数:
测试结果
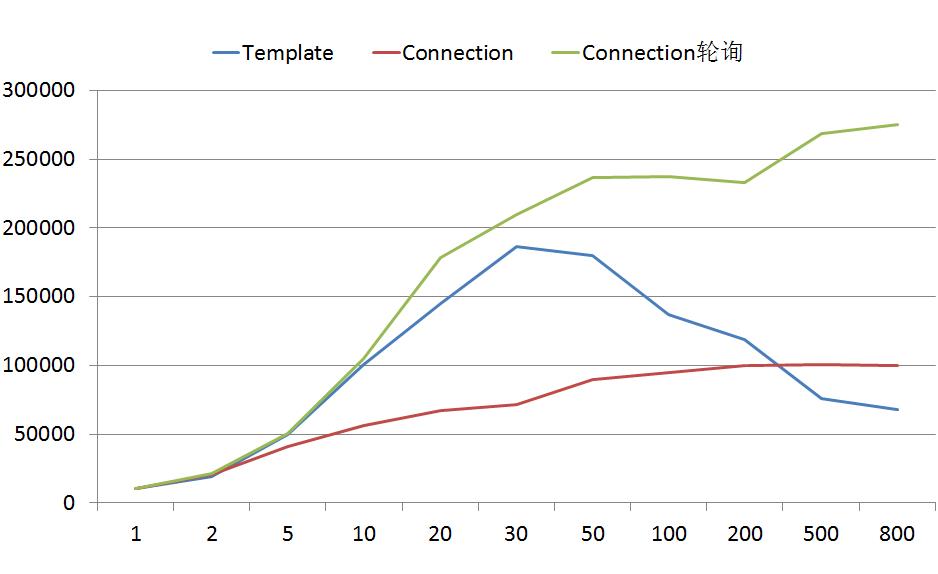
物理机(Template的最大连接数100):
云主机测试场景(Template的最大连接数20):
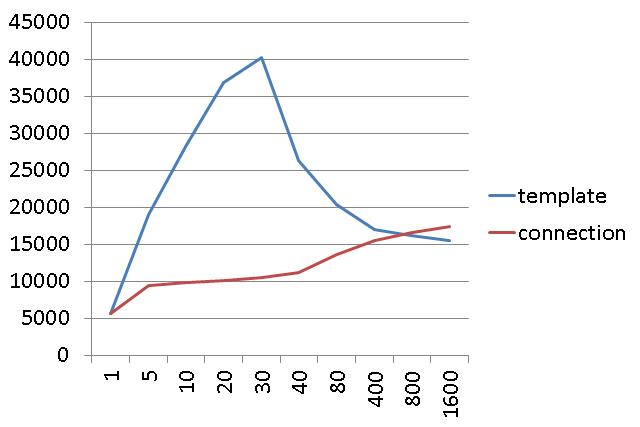
可以看到,虽然平台不同,但是测试结果是有共性的:
Template的吞吐量大于Connection
Template能够快速进入到QPS的峰值
Template在到达拐点后,会随着线程的增多,QPS大幅下降
Connection随着线程数量的增多,QPS一直稳定上升,并最终超过Template
这里有几个问题:
为什么 Template 会随着线程的增多性能下降?
为什么 Connection 会随着线程的增多性能反而上升?
为什么 Template 的吞吐量比 Connection 的大?
报告分析
上一节的三个问题,将通过源码分析,JMC观察,以及JMH进行各种微测试逐个进行解答。
这里先解释一些前置条件:
· Memcached 我们使用的是 SpyMemcached 的框架,该框架和 Jedis 最大的不同是采用了 NIO 模型。对于JedisPool来说,对象池里的对象,是一个封装过的 Socket 对象,但是 SpyMemcaced 的 MemcahcedClient本身是一个线程对象,并且其自身会不停的进行 selector.select()操作。
也就是说,一个对象池里的对象就是一个线程,这点需要注意,相比传统的连接池,Template里池的对象会重很多。
1. 为什么 Template 的吞吐量比 Connection 的大?
这个问题比较好回答,在没有达到CPU核数之前,只使用一个 MemcachedConnection也就是一个线程来处理 NIO并没有发挥出完整的性能,而 Template 能够充分发挥电脑多核的性能优势,从而达到更高的吞吐量。
2. 为什么 Template 会随着线程的增多性能下降,而Connection却随着线程数上升性能上升?
先排除掉池中对象本身的开销,Template主要就是增加了Commons-pool的获取和归还开销。那第一个问题如果单一的来看,其实可以很简单的回答,因为锁的原因,获取对象需要获取锁,线程越多,获取锁的难度越大,并且随着线程增多,上下文切换也势必会增多。但是,如果结合起来看,就会变得很奇怪,因为 Connection 随着线程的增多,反而性能上升,而且 Connection 中也有着锁,为什么相同的场景和条件,缺截然相反的两种结果呢?
首先想到,其问题可能出现在Commons-pool上,于是采用JMH进行了微基准测试,得到了如下结果(最大对象为100个):
borrowObject,再 returnObject 为一次操作,压测出如下结果:
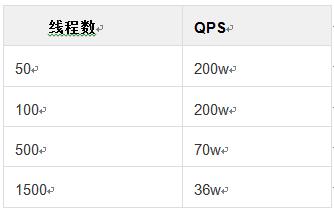
多线程进行offer操作,单线程进行drainTo操作,一次offer为一次操作:可以看到,正如之前的猜想,Commons-pool果然随着线程的增大,性能大幅下降。为了进行对比,研究了SpyMemcached的源码,并发现其多线程竞争主要是在一个LinkedBlockingQueue上,于是继续用 JMH 有模拟了Spy的 Queue操作。
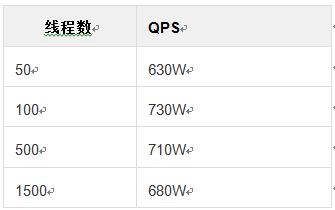
继续怀疑是否是Commons-pool中由于锁的关系导致了等待时间的增长,从而导致QPS的下降,于是观察JMC中的线程等待时间观察到LinkedBlockingQueue随着线程的增多,QPS虽然有所减少,但是减少的很有限。
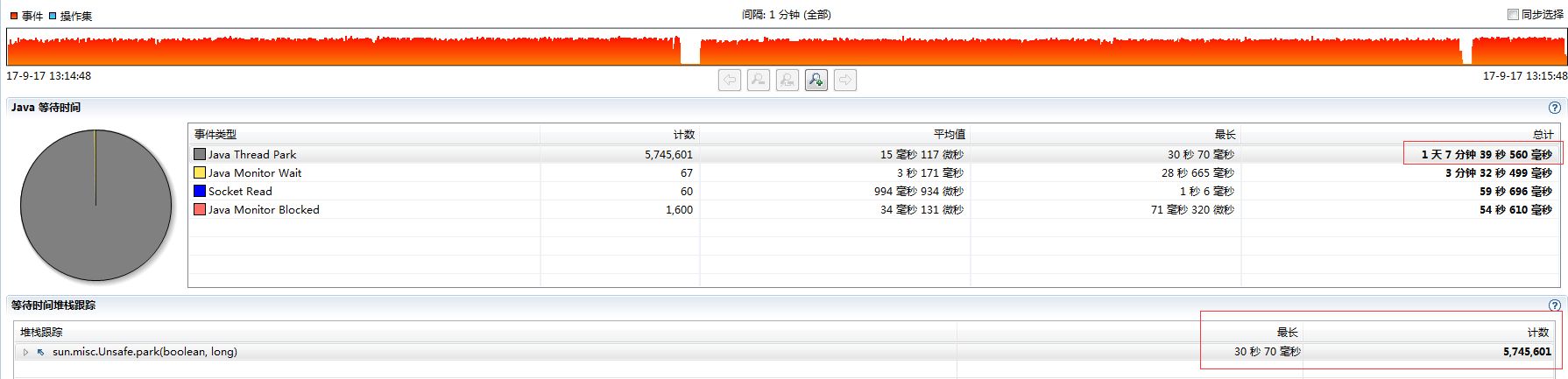
Commons-pool
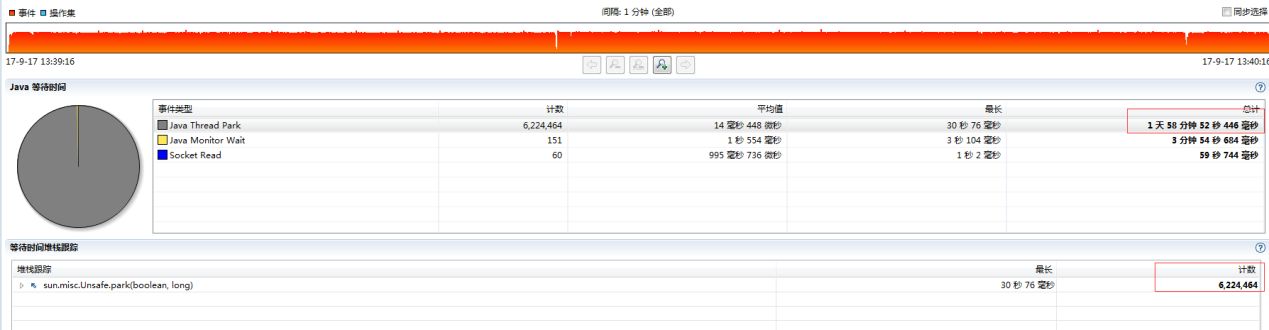
LinkedBlockingQueue
· LinkedBlockingQueue 等待了6,224,464 次
· Commons-pool 等待了5,745,601 次
Commons-pool的锁等待次数竟然比LinkedBlockingQueue 还要少,为什么会出现如此反差?需要进一步深入Commons-pool源码查看原因。
通过查看Commons-pool源码发现,Commons-pool内部使用的是 LinkedBlockingDeque
并且发现,一次操作(borrow& return),需要获取4次锁!分别是:
borrow过程中,先进行pollFirst
如果pollFirst不成功,则进行pollFirst(borrowMaxWaitMillis, TimeUnit.MILLISECONDS) 调用
return过程中,需要进行判断 size(),如果小于则放入池中
如果池未满,则需要 addLast(p)
LinkedBlockingDeque 中只有一把lock,生产者和消费者共用了一把锁。而LinkedBlockingQueue,里面有两把锁,一把putLock,一把takeLock,也就是说,offer和 drainTo两个操作不互相阻塞。
结合代码中的实现:Commons-pool之所以随着线程的增多,性能大幅下降,主要是因为,一次操作需要抢四次锁,并且没有put和take锁分离,导致了需要归还对象的线程抢到锁很难,而抢到锁的线程可能此时池子里又没有对象,大量的锁操作以及无用切换导致了QPS大幅降低。
LinkedBlockingQueue之所以线程增多性能不怎么变化,是因为,只要抢到锁,一定就完成了一次操作(业务线程只抢put锁)。无需再等待其他操作。
通过以上分析进一步认为,如果Commons-pool中存放了1500个对象,那由于每次抢到锁,也能保证一次操作的完成,而不存在我归还对象时抢不到锁,获取对象时抢到锁却没对象的尴尬场景,通过JMH再次实验:
最后总结下,Commons-pool之所以这么慢,首先是一次操作需要获取锁的次数多,其次是锁没有分为put和take两把,导致了return和borrow都会互相阻塞对方。果然如分析的那样,QPS又回到了200W的上限。但是,由于Template中存放的是一个Thread对象,再不改变 TLAB 大小的情况下,一个线程差不多就要1M,并且还需要大量的上下文切换,再考虑上GC的影响,是绝对不可能开的这么大的。
解决方案
使用多个Connection放在数组中,采用轮询或者Thread-Id取模的方式来获取Connection使用。
以上是关于开源有坑,使用谨慎:缓存连接池开源组件剖析的主要内容,如果未能解决你的问题,请参考以下文章