追光者系列HikariCP连接池监控指标实战
Posted 工匠小猪猪的技术世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了追光者系列HikariCP连接池监控指标实战相关的知识,希望对你有一定的参考价值。
1.这是一个系列,有兴趣的朋友可以持续关注
2.如果你有HikariCP使用上的问题,可以给我留言,我们一起沟通讨论
3.希望大家可以提供我一些案例,我也希望可以支持你们做一些调优
![【追光者系列】HikariCP连接池监控指标实战]()
业务方关注哪些数据库指标?
首先分享一下自己之前的一段笔记(找不到引用出处了)
系统中多少个线程在进行与数据库有关的工作?其中,而多少个线程正在执行 SQL 语句?这可以让我们评估数据库是不是系统瓶颈。
多少个线程在等待获取数据库连接?获取数据库连接需要的平均时长是多少?数据库连接池是否已经不能满足业务模块需求?如果存在获取数据库连接较慢,如大于 100ms,则可能说明配置的数据库连接数不足,或存在连接泄漏问题。
哪些线程正在执行 SQL 语句?执行了的 SQL 语句是什么?数据库中是否存在系统瓶颈或已经产生锁?如果个别 SQL 语句执行速度明显比其它语句慢,则可能是数据库查询逻辑问题,或者已经存在了锁表的情况,这些都应当在系统优化时解决。
最经常被执行的 SQL 语句是在哪段源代码中被调用的?最耗时的 SQL 语句是在哪段源代码中被调用的?在浩如烟海的源代码中找到某条 SQL 并不是一件很容易的事。而当存在问题的 SQL 是在底层代码中,我们就很难知道是哪段代码调用了这个 SQL,并产生了这些系统问题。
在研究HikariCP的过程中,这些业务关注点我发现在连接池这层逐渐找到了答案。
监控指标
| HikariCP指标 | 说明 | 类型 | 备注 |
|---|---|---|---|
| hikaricp_connection_timeout_total | 每分钟超时连接数 | Counter | |
| hikaricp_pending_threads | 当前排队获取连接的线程数 | GAUGE | 关键指标,大于10则 报警 |
| hikaricp_connection_acquired_nanos | 连接获取的等待时间 | Summary | pool.Wait 关注99极值 |
| hikaricp_active_connections | 当前正在使用的连接数 | GAUGE | |
| hikaricp_connection_creation_millis | 创建连接成功的耗时 | Summary | 关注99极值 |
| hikaricp_idle_connections | 当前空闲连接数 | GAUGE | 关键指标,默认10,因为降低为0会大大增加连接池创建开销 |
| hikaricp_connection_usage_millis | 连接被复用的间隔时长 | Summary | pool.Usage 关注99极值 |
| hikaricp_connections | 连接池的总共连接数 | GAUGE |
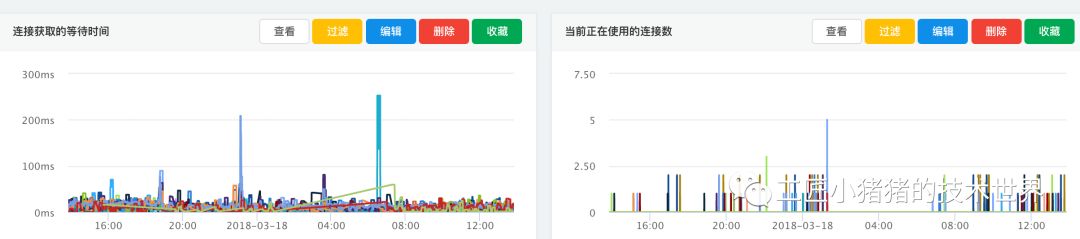
重点关注
hikaricp_pending_threads
该指标持续飙高,说明DB连接池中基本已无空闲连接。
拿之前业务方应用pisces不可用的例子来说(如下图所示),当时所有线程都在排队等待,该指标已达172,此时调用方已经产生了大量超时及熔断,虽然业务方没有马上找到拿不到连接的根本原因,但是这个告警出来之后及时进行了重启,避免产生更大的影响。
hikaricp_connection_acquired_nanos(取99位数)
下图是Hikari源码com.zaxxer.hikari.pool.HikariPool#getConnection部分,
public Connection getConnection(final long hardTimeout) throws SQLException
{
suspendResumeLock.acquire();
final long startTime = currentTime();
try {
long timeout = hardTimeout;
do {
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
break; // We timed out... break and throw exception
}
final long now = currentTime();
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {
closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE);
timeout = hardTimeout - elapsedMillis(startTime);
}
else {
metricsTracker.recordBorrowStats(poolEntry, startTime);
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
} while (timeout > 0L);
metricsTracker.recordBorrowTimeoutStats(startTime);
throw createTimeoutException(startTime);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new SQLException(poolName + " - Interrupted during connection acquisition", e);
}
finally {
suspendResumeLock.release();
}
}
从上述代码可以看到,suspendResumeLock.acquire()走到poolEntry == null时已经超时了,拿到一个poolEntry后先判断是否已经被标记为待清理或已经超过了设置的最大存活时间(应用配置的最大存活时间不应超过DBA在DB端配置的最大连接存活时间),若是直接关闭继续调用borrow,否则才会返回该连接,metricsTracker.recordBorrowTimeoutStats(startTime);该段代码的意义就是此指标的记录处。
Vesta模版中该指标单位配为了毫秒,此指标和排队线程数结合,可以初步提出 增大连接数 或 优化慢查询/慢事务 的优化方案等。
当 排队线程数多 而 获取连接的耗时较短 时,可以考虑增大连接数
当 排队线程数少 而 获取连接的耗时较长 时,此种场景不常见,举例来说,可能是某个接口QPS较低,连接数配的小于这个QPS,而这个连接中有较慢的查询或事务,这个需要具体问题具体分析
当 排队线程数多 且 获取连接的耗时较长时,这种场景比较危险,有可能是某个时间点DB压力大或者网络抖动造成的,排除这些场景,若长时间出现这种情况则可认为 连接配置不合理/程序是没有达到上线标准 ,如果可以从业务逻辑上优化慢查询/慢事务是最好的,否则可以尝试 增大连接数 或 应用扩容 。
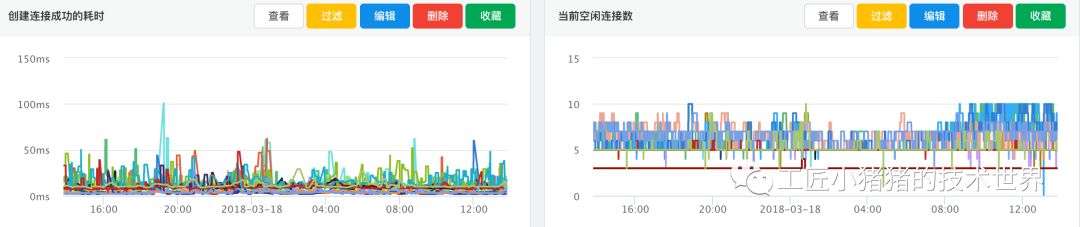
hikaricp_idle_connections
Hikari是可以配置最小空闲连接数的,当此指标长期比较高(等于最大连接数)时,可以适当减小配置项中最小连接数。
hikaricp_active_connections
此指标长期在设置的最大连接数上下波动时,或者长期保持在最大线程数时,可以考虑增大最大连接数。
hikaricp_connection_usage_millis(取99位数)
该配置的意义在于表明 连接池中的一个连接从 被返回连接池 到 再被复用 的时间间隔,对于使用较少的数据源,此指标可能会达到秒级,可以结合流量高峰期的此项指标与激活连接数指标来确定是否需要减小最小连接数,若高峰也是秒级,说明对比数据源使用不频繁,可考虑减小连接数。
hikaricp_connection_timeout_total
该配置的意义在于表明 连接池中总共超时的连接数量,此处的超时指的是连接创建超时。经常连接创建超时,一个排查方向是和运维配合检查下网络是否正常。
hikaricp_connection_creation_millis(取99位数)
该配置的意义在于表明 创建一个连接的耗时。主要反映当前机器到数据库的网络情况,在IDC意义不大,除非是网络抖动或者机房间通讯中断才会有异常波动。
监控指标部分实战案例
以下连接风暴和慢SQL两种场景是可以采用HikariCP连接池监控的。
连接风暴
连接风暴,也可称为网络风暴,当应用启动的时候,经常会碰到各应用服务器的连接数异常飙升,这是大规模应用集群很容易碰到的问题。先来描述一个场景
在项目发布的过程中,我们需要重启应用,当应用启动的时候,经常会碰到各应用服务器的连接数异常飙升。假设连接数的设置为:min值3,max值10。正常的业务使用连接数在5个左右,当重启应用时,各应用连接数可能会飙升到10个,瞬间甚至还有可能部分应用会报取不到连接。启动完成后接下来的时间内,连接开始慢慢返回到业务的正常值。这种场景,就是碰到了所谓的连接风暴。
连接风暴可能带来的危害主要有:
在多个应用系统同时启动时,系统大量占用数据库连接资源,可能导致数据库连接数耗尽
数据库创建连接的能力是有限的,并且是非常耗时和消耗CPU等资源的,突然大量请求落到数据库上,极端情况下可能导致数据库异常crash。
对于应用系统来说,多一个连接也就多占用一点资源。在启动的时候,连接会填充到max值,并有可能导致瞬间业务请求失败。
与连接风暴类似的还有:
启动时的preparedstatement风暴
缓存穿透。在缓存使用的场景中,缓存KEY值失效的风暴(单个KEY值失效,PUT时间较长,导致穿透缓存落到DB上,对DB造成压力)。可以采用 布隆过滤器 、单独设置个缓存区域存储空值,对要查询的key进行预先校验 、缓存降级等方法。
缓存雪崩。上条的恶化,所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。可以采用 加锁排队、 设置过期标志更新缓存 、 设置过期标志更新缓存 、二级缓存(引入一致性问题)、 预热、 缓存与服务降级等解决方法。
案例一 某公司订单业务(刘龘刘同学提供):
我们那时候采用弹性伸缩,数据库连接池是默认的,有点业务出了点异常,导致某个不重要的业务弹出N台机器,导致整个数据库连接不可用,影响订单主业务。
该案例就可以理解为是一次连接风暴,当时刚好那个服务跟订单合用一个数据库了,订单服务只能申请到默认连接数,访问订单TPS上不去,老刘同学说“损失惨重才能刻骨铭心呀”。
案例二 切库(DBA提供):
我司在切库的时候产生过连接风暴,瞬间所有业务全部断开重连,造成连接风暴,暂时通过加大连接数解决此问题。当然,单个应用重启的时候可以忽略不计,因为,一个库的依赖服务不可能同时重启。
案例三 机房出故障(DBA提供):
以前机房出故障的时候,应用全部涌进来,有过一次连接炸掉的情况。
慢SQL
我司的瓶颈其实不在连接风暴,我们的并发并不是很高,和电商不太一样。复杂 SQL 很多,清算、对账的复杂SQL都不少,部分业务的SQL比较复杂。比如之前有过一次催收线上故障,就是由于慢SQL导致Hikari连接池占满,排队线程指标飙升,当时是无法看到整个连接池的历史趋势的,也很难看到连接池实时指标,有了本监控大盘工具之后,业务方可以更方便得排查类似问题。
如何调优
经验配置连接池参数及监控告警
首先分享一个小故事《扁鹊三兄弟》
春秋战国时期,有位神医被尊为“医祖”,他就是“扁鹊”。一次,魏文王问扁鹊说:“你们家兄弟三人,都精于医术,到底哪一位最好呢?”扁鹊答:“长兄最好,中兄次之,我最差。”文王又问:“那么为什么你最出名呢?”扁鹊答:“长兄治病,是治病于病情发作之前,由于一般人不知道他事先能铲除病因,所以他的名气无法传出去;中兄治病,是治病于病情初起时,一般人以为他只能治轻微的小病,所以他的名气只及本乡里;而我是治病于病情严重之时,一般人都看到我在经脉上穿针管放血,在皮肤上敷药等大手术,所以以为我的医术高明,名气因此响遍全国。”
正文罗列的几种监控项可以配上告警,这样,能够在业务方发现问题之前第一时间发现问题,这就是扁鹊三兄弟大哥、二哥的做法,我们正是要努力成为扁鹊的大哥、二哥那样的人。
根据日常的运维经验,大多数线上应用可以使用如下的Hikari的配置:
maximumPoolSize: 20
minimumIdle: 10
connectionTimeout: 30000
idleTimeout: 600000
maxLifetime: 1800000
连接池连接数有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。这里提一下minimumIdle,hikari实际上是不推荐用户去更改Hikari默认连接数的。
This property controls the minimum number of idle connections that HikariCP tries to maintain in the pool. If the idle connections dip below this value and total connections in the pool are less than maximumPoolSize, HikariCP will make a best effort to add additional connections quickly and efficiently. However, for maximum performance and responsiveness to spike demands, we recommend not setting this value and instead allowing HikariCP to act as a fixed size connection pool. Default: same as maximumPoolSize
该属性的默认值为10,Hikari为了追求最佳性能和相应尖峰需求,hikari不希望用户使用动态连接数,因为动态连接数会在空闲的时候减少连接、有大量请求过来会创建连接,但是但是创建连接耗时较长会影响RT。还有一个考虑就是隐藏风险,比如平时都是空载的 10个机器就是100个连接,其实数据库最大连接数比如是150个,等满载的时候就会报错了,这其实就是关闭动态调节的能力,跟 jvm 线上 xmx和xms 配一样是一个道理。动态调节不是完全没用,比如不同服务连一个db然后,业务高峰是错开的,这样的情况其实比较少。
更多配置解析请参见本系列第二篇《【追光者系列】HikariCP连接池配置项》
压测
连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。
连接池的大小设置多少合适呢?再分配多了效果也不大,一个是应用服务器维持这个连接数需要内存支持,并且维护大量的连接进行分配使用对cpu也是一个不小的负荷,因此不宜太大,虽然sleep线程增多对DBA来说目前线上已经可以忽略,但是能处理一下当然最好。如果太小,那么在上述规模项目的并发量以及数据量上来以后会造成排队现象,系统会变慢,数据库连接会经常打开和关闭,性能上有压力,用户体验也不好。
如何评估数据库连接池的性能是有专门的算法公式的,【追光者系列】后续会更新,不过经验值一般没有压测准,连接池太大、太小都会存在问题。具体设置多少,要看系统的访问量,可通过反复测试,找到最佳点。
连接风暴问题的另一种探索
对于连接风暴,如果采用传统的proxy模式可以处理好这种问题,主要还是mysql的bio模型不支持大量连接。负载均衡 、故障转移、服务自动扩容 都可以在这一层实现。
预告
《【追光者系列】HikariCP连接池配置项》
《【追光者系列】HikariCP连接池设置多大合适》
感谢
感谢监控组、DBA、业务方的同学提供的相关案例。
以上是关于追光者系列HikariCP连接池监控指标实战的主要内容,如果未能解决你的问题,请参考以下文章
Day860.高性能数据库连接池HiKariCP -Java 并发编程实战
Day860.高性能数据库连接池HiKariCP -Java 并发编程实战
HikariCP 源码分析之 leakDetectionThreshold 及实战解决 Spark/Scala 连接池泄漏