数据库连接 - 为什么C3P0连接池那么慢
Posted 方丈的寺院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库连接 - 为什么C3P0连接池那么慢相关的知识,希望对你有一定的参考价值。
摘要
承接上篇数据库连接(1)从jdbc到mybatis,介绍下数据库连接池技术
为什么需要连接池
在上一篇中我们介绍说客户端建立一次连接耗时太长(建立连接,设置字符集,autocommit等),如果在每个sql操作都需要经历建立连接,关闭连接。不仅应用程序响应慢,而且会产生很多临时对象,应用服务器GC压力大。另外数据库server端对连接也有限制,比如mysql默认151个连接(实际环境中一般会调大这个值,尤其是多个服务时)
现在面临的问题就是如何提高对稀缺性的资源高效管理。因为客户端与数据库的连接本质就是tcp请求,加上基于tcp协议封装的mysql请求。那么通常解决这类问题,我们有两种方式,一种是池话技术,即使用一个容器,提前创建好连接,请求时直接从池子里面拿,另外一种就是利用IO多路复用技术。利于在spring5中,mongo ,cassandra等数据库的访问就可以利用reactive来实现了,但是关系型数据库不行,原因在于关型数据库的访问目前都是基于JDBC,JDBC操作数据库的流程,建立connection,构建Statement,执行这一套是串行的,阻塞型。一个事务中的多个操作只能在同一个连接中完成。所以不能使用IO多路复用技术,是受限于JDBC的阻塞。对于其他语言,是可以的,比如nodejs
所以我们使用池话技术来提供数据库访问
数据库连接池与线程池的区别
通常,程序员在业务开发中经常使用的是线程池,利用CPU多核,来并发处理任务,提高效率。数据库连接池与线程池同属于池化技术,没有太大区别,都是需要管理池的大小,资源控制。不同的数据库连接池中放的是connection,同时还需要管理事务,所以通常数据库连接池中会对这个进行优化
从连接池中取连接执行sql操作,多了两步设置connection autocommit属性操作
通过将connection分成两组,来提供效率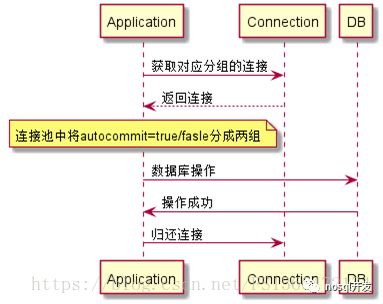
开源连接池技术介绍
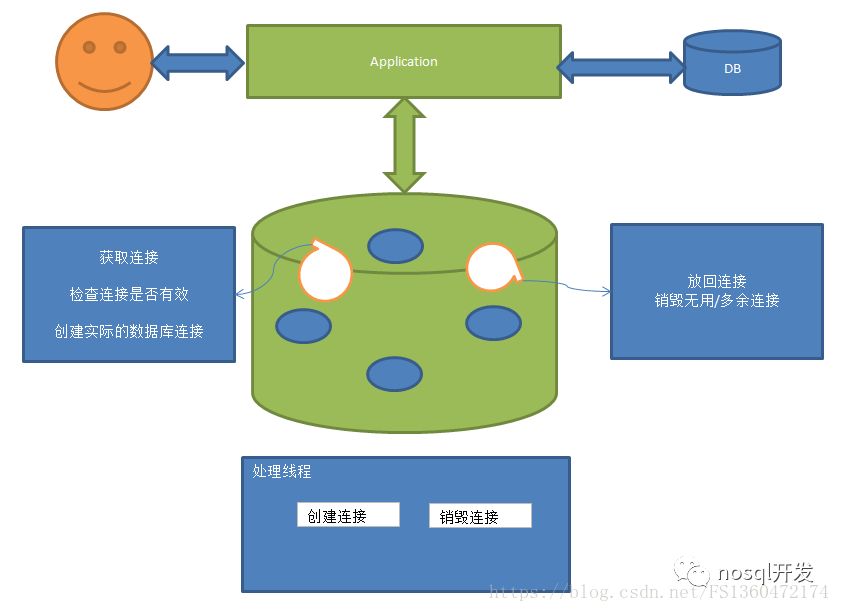
一个基本的数据库连接池包括几大部分
取出连接
放回连接
异步/同步处理线程
进行创建连接和销毁连接 对于一个数据库连接池的根本就在于并发容器的实现,也是决定连接池的效率高低,常见的连接池配置如下
initialSize:初始连接数
maxActive: 最大连接数量
minIdle: 最小连接数量
maxWait: 获取连接最大等待时间ms
minEvictableIdleTimeMillis:连接保持空闲而不被驱逐的最小时间
timeBetweenEvictionRunsMillis:销毁线程的时间检测
testOnBorrow:申请连接时执行,比较影响性能
validationQuery:testOnBorrow为true检测是否是有效连接sql
testWhileIdle:申请连接的时候检测
目前的开源数据库连接池主要有以下,
C3P0,和DBCP是出现的比较早的数据库连接,主要用于hibernate,和tomcat6.0以下,比较稳定,在低并发的情况下,工作还可以,但是高并发下,性能比较差,所以在tomcat6,又重写了一个jdbc-pool,来替代DBCP。
Druid是阿里巴巴开源的高性能数据库连接池,目前基本是各大互联网公司的标配了,加上又是国内的,文档比较易读,所以流行度比较高,另外一个是hikariCP,性能比较高,目前普及度还不是特别高。
那为什么C3P0和DBCP的性能比较低呢?前面提到数据库连接池本质上就是一个并发容器的实现。通常我们可以利用List+锁机制实现。或者使用jdk原生的,比如CopyOnWriteList这样的结构 而锁通过有两种,一种JVM级别的synchronized,一种是JDK提供的ReentrantLock,两者在语义上并没有多大区别,互斥,内存可见,可重入。JDK5中引入ReentrantLock时,性能比synchronzied要好很多,而在JDK6中,经过优化后的,两者并无太大性能上区别。所以ReentrantLock更多优势在于
可以中断等待的线程 一直拿不到锁的等待线程,可以中断掉,避免出现死锁
可以结合Condition,更加灵活控制线程
看下com.mchange.v2.c3p0.DriverManagerDataSource 的实现
// should NOT be sync'ed -- driver() is sync'ed and that's enough
// sync'ing the method creates the danger that one freeze on connect
// blocks access to the entire DataSource
public Connection getConnection() throws SQLException
{
ensureDriverLoaded();
// 通过此方法来获取连接
Connection out = driver().connect( jdbcUrl, properties );
if (out == null)
throw new SQLException("Apparently, jdbc URL '" + jdbcUrl + "' is not valid for the underlying " +
"driver [" + driver() + "].");
return out;
}
在获取连接的时候首先在一个synchonized中去获取java.sql.Driver,
private synchronized Driver driver() throws SQLException
{
//To simulate an unreliable DataSource...
//double d = Math.random() * 10;
//if ( d > 1 )
// throw new SQLException(this.getClass().getName() + " TEST of unreliable Connection. If you're not testing, you shouldn't be seeing this!");
//System.err.println( "driver() <-- " + this );
if (driver == null)
{
if (driverClass != null && forceUseNamedDriverClass)
{
if ( Debug.DEBUG && logger.isLoggable( MLevel.FINER ) )
logger.finer( "Circumventing DriverManager and instantiating driver class '" + driverClass +
"' directly. (forceUseNamedDriverClass = " + forceUseNamedDriverClass + ")" );
try
{
driver = (Driver) Class.forName( driverClass ).newInstance();
this.setDriverClassLoaded( true );
}
catch (Exception e)
{ SqlUtils.toSQLException("Cannot instantiate specified JDBC driver. Exception while initializing named, forced-to-use driver class'" + driverClass +"'", e); }
}
else
driver = DriverManager.getDriver( jdbcUrl );
}
return driver;
}
具体的连接池管理是BasicResourcePool,可以看下代码,里面全都是synchronized方法。并发性能怎么能好。
再来看下Druid的实现,DruidDataSource
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
DruidConnectionHolder holder;
for (boolean createDirect = false;;) {
// 带有超时的连接获取
if (maxWait > 0) {
holder = pollLast(nanos);
} else {
holder = takeLast();
}
}
并发环境下去拿连接时,并没有在读操作上加锁,比互斥锁的性能要高 互斥锁是一种比较保守的策略,像synchronized,它避免了写写冲突,写读冲突,和读读冲突,对于数据库连接池,应用程序来拿,是一个读操作比较多的,允许多个读同时操作,能够提高系统的并发性。
private DruidConnectionHolder pollLast(long nanos) throws InterruptedException, SQLException {
long estimate = nanos;
for (;;) {
if (poolingCount == 0) {
// 通知创建线程去创建连接
emptySignal();
}
decrementPoolingCount();
// 从数组中获取连接
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
long waitNanos = nanos - estimate;
last.setLastNotEmptyWaitNanos(waitNanos);
return last;
}
}
在创建连接线程,销毁连接线程中增加写锁
private boolean put(DruidConnectionHolder holder) {
// 加锁
lock.lock();
try {
if (poolingCount >= maxActive) {
return false;
}
connections[poolingCount] = holder;
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
//发出连接池非空信号,等待的线程开始处理
notEmpty.signal();
notEmptySignalCount++;
if (createScheduler != null) {
createTaskCount--;
if (poolingCount + createTaskCount < notEmptyWaitThreadCount //
&& activeCount + poolingCount + createTaskCount < maxActive) {
emptySignal();
}
}
} finally {
lock.unlock();
}
return true;
}
想了解更多数据库知识,扫描下方二维码
HikariCP在读写锁的基础上进行了进一步的优化 https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole
参考
https://my.oschina.net/javahongxi/blog/1523745
以上是关于数据库连接 - 为什么C3P0连接池那么慢的主要内容,如果未能解决你的问题,请参考以下文章