没有HTTP连接池,空谈什么持久连接
Posted 魔笛手CTO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了没有HTTP连接池,空谈什么持久连接相关的知识,希望对你有一定的参考价值。
urllib3 如何实现 HTTP 连接池
从文档入手
先来看一下官方文档给出的使用说明:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request('GET', 'http://httpbin.org/robots.txt')
>>> r.status
200
>>> r.data
'User-agent: *
Disallow: /deny
'
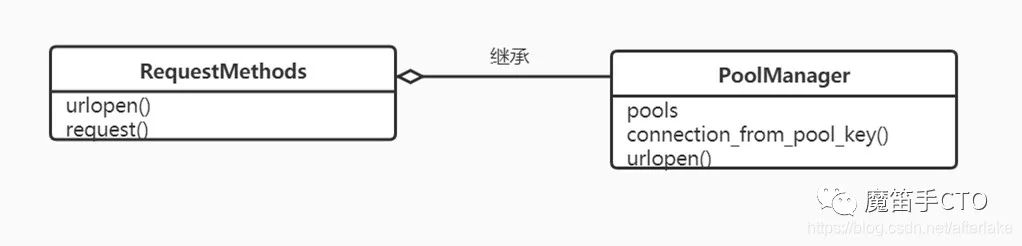
PoolManager
class PoolManager(RequestMethods):
def __init__(self, num_pools=10, headers=None, **connection_pool_kw):
RequestMethods.__init__(self, headers)
self.connection_pool_kw = connection_pool_kw
# pools故名思意,是连接池的池子
# 此处实例化的RecentlyUsedContainer看起来像是一个LRU,我们稍后再细看RecentlyUsedContainer
self.pools = RecentlyUsedContainer(num_pools, dispose_func=lambda p: p.close())
self.pool_classes_by_scheme = pool_classes_by_scheme
self.key_fn_by_scheme = key_fn_by_scheme.copy()
def connection_from_pool_key(self, pool_key, request_context=None):
# 如果大池子中没有对应的连接池,则新建一个
# 此处返回的pool对象才是真正缓存持久连接的连接池
with self.pools.lock:
pool = self.pools.get(pool_key)
if pool:
return pool
scheme = request_context["scheme"]
host = request_context["host"]
port = request_context["port"]
# 新建的连接池对象根据协议不同,可能是HTTPConnectionPool或者HTTPSConnectionPool
# 后续说明以HTTPConnectionPool为主
pool = self._new_pool(scheme, host, port, request_context=request_context)
self.pools[pool_key] = pool
return pool
def urlopen(self, method, url, redirect=True, **kw):
u = parse_url(url)
self._validate_proxy_scheme_url_selection(u.scheme)
# self.connection_from_host会根据主机、端口已经协议信息,拼接好pool_key,调用上面的self.connection_from_pool_key
conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)
# 此处省略后续的代码逻辑
pass
RecentlyUsedContainer
class RecentlyUsedContainer(MutableMapping):
"""
RecentlyUsedContainer作为urllib3内部实现的LRU(最近最少使用)结构,保证了线程安全,并且可以像dict一样使用,
"""
ContainerCls = OrderedDict
def __init__(self, maxsize=10, dispose_func=None):
self._maxsize = maxsize
self.dispose_func = dispose_func
# 内部通过OrderedDict来保存数据
self._container = self.ContainerCls()
# 加了线程锁,保证线程安全
self.lock = RLock()
def __getitem__(self, key):
# 覆写__getitem__,在返回数据之前刷新其状态至最新
with self.lock:
item = self._container.pop(key)
self._container[key] = item
return item
def __setitem__(self, key, value):
# 覆写__setitem__,除了保证数据状态保持最新之外,还确保数据量不会超过容器限制
evicted_value = _Null
with self.lock:
evicted_value = self._container.get(key, _Null)
self._container[key] = value
if len(self._container) > self._maxsize:
_key, evicted_value = self._container.popitem(last=False)
# 此处提供了一个钩子,可以在数据被垃圾回收之前做一些清理操作
if self.dispose_func and evicted_value is not _Null:
self.dispose_func(evicted_value)
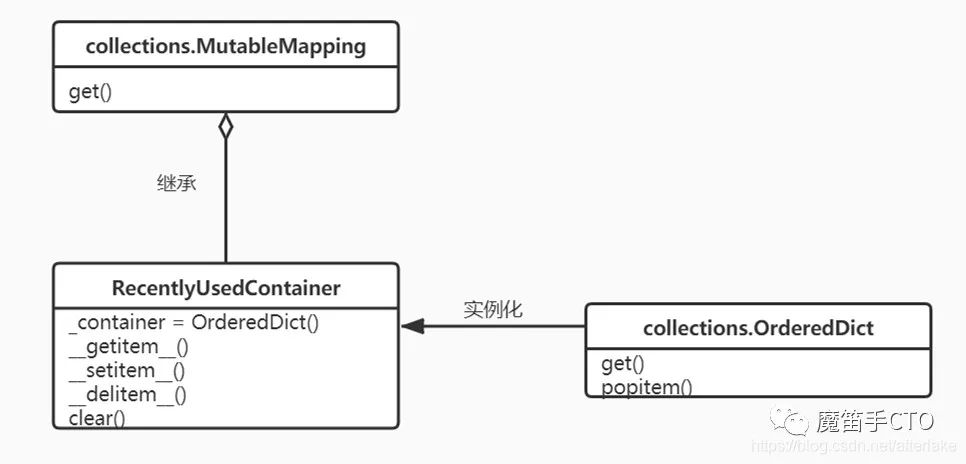
RecentlyUsedContainer 的 UML 类图稍微比 PoolManager 复杂了一些。
HTTPConnectionPool
class HTTPConnectionPool(ConnectionPool, RequestMethods):
scheme = "http"
# 连接池具体缓存的连接对象为HTTPConnection,我们稍后介绍
ConnectionCls = HTTPConnection
ResponseCls = HTTPResponse
def __init__(self, host, port=None, strict=False, timeout=Timeout.DEFAULT_TIMEOUT,
maxsize=1, block=False, headers=None, retries=None, _proxy=None,
_proxy_headers=None, _proxy_config=None, **conn_kw):
# 注意:此处省略了部分实例化代码
# pool作为实际的缓存HTTP连接的数据结构,同大池子一样,有一个最大容量
# self.QueueCls实际是继承自父类ConnectionPool,具体类型为urllib3自定义的队列结构LifoQueue
# 稍后会详细介绍LifoQueue
self.pool = self.QueueCls(maxsize)
# 省略后续的部分实例化代码
...
def _get_conn(self, timeout=None):
"""
获取HTTP连接的内部私有实例方法,实际调用方为self.urlopen
"""
conn = None
# 尝试从连接池获取一条连接
try:
conn = self.pool.get(block=self.block, timeout=timeout)
except AttributeError: # self.pool is None
raise ClosedPoolError(self, "Pool is closed.")
except queue.Empty:
if self.block:
raise EmptyPoolError(
self,
"Pool reached maximum size and no more connections are allowed.",
)
pass
# 对于获取的连接做检测
if conn and is_connection_dropped(conn):
log.debug("Resetting dropped connection: %s", self.host)
conn.close()
if getattr(conn, "auto_open", 1) == 0:
conn = None
# 如果缓存的连接为有效连接,直接返回,否则新建一条连接
return conn or self._new_conn()
def urlopen(self, method, url, body=None, headers=None, retries=None, redirect=True,
assert_same_host=True, timeout=_Default, pool_timeout=None, release_conn=None,
chunked=False, body_pos=None, **response_kw
):
# 由于代码太长,这里就不贴urlopen的代码了
# urlopen的实际功能为从连接池获取一个HTTPConnection实例,发送HTTP请求
# 另外考虑到从缓存获取的持久连接有可能已经被关闭,此时需要有重试机制
...

LifoQueue
class LifoQueue(queue.Queue):
# 实际上除self.queue不是list外,_qsize、_put、_get方法的实现与Python内置的LifoQueue没有区别
def _init(self, _):
self.queue = collections.deque()
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item):
# Queue的put方法在保证线程安全以及队列未满的前提下会调用_put,将数据放在队列尾
self.queue.append(item)
def _get(self):
# Queue的get方法会在保证线程安全的前提下调用_get,从队列尾部弹出数据
return self.queue.pop()
class HTTPConnection(_HTTPConnection, object):
pass
-
通过主机、端口等信息,检查大池子 PoolManager 有没有对应的连接池。 -
如果 PoolManager 有对应的连接池,跳到第4步。 -
如果 PoolManager 没有的连接池,新建一个连接池 HTTPConnectionPool 出来,并放入大池子。 -
检查连接池 HTTPConnectionPool 有没有可用的连接。 -
如果 HTTPConnectionPool 有可用的连接,从连接池取出,跳到第7步。 -
如果 HTTPConnectionPool 没有可用的连接,新建一个连接HTTPConnection出来。 -
通过 HTTPConnection 发送请求,中间可能涉及连接的重试机制。 -
获得响应之后,将连接 HTTPConnection 放回连接池。
以上是关于没有HTTP连接池,空谈什么持久连接的主要内容,如果未能解决你的问题,请参考以下文章